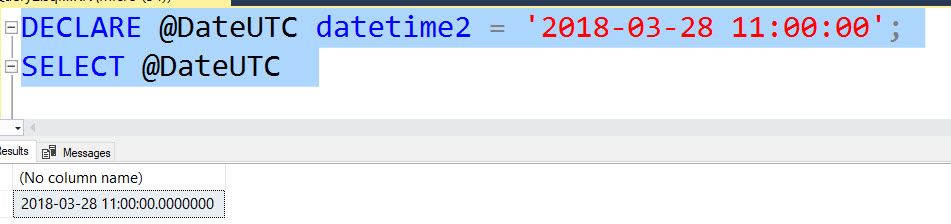
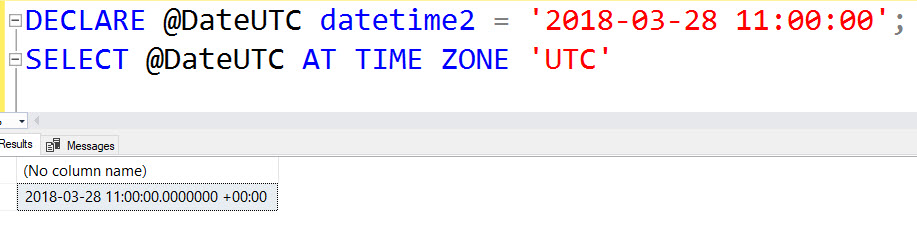
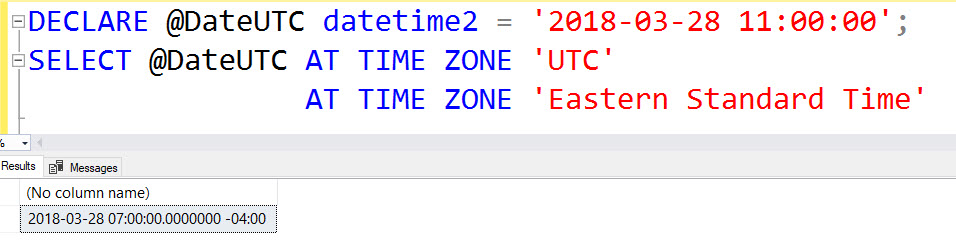
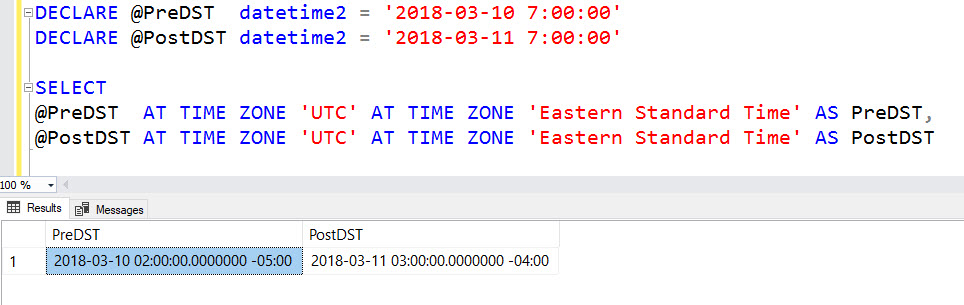
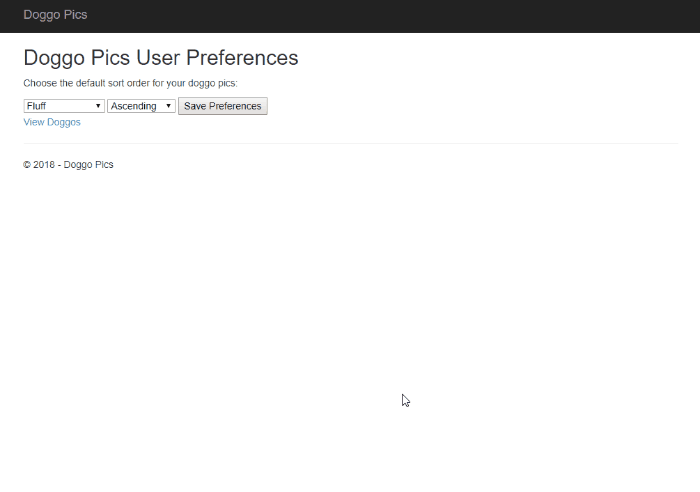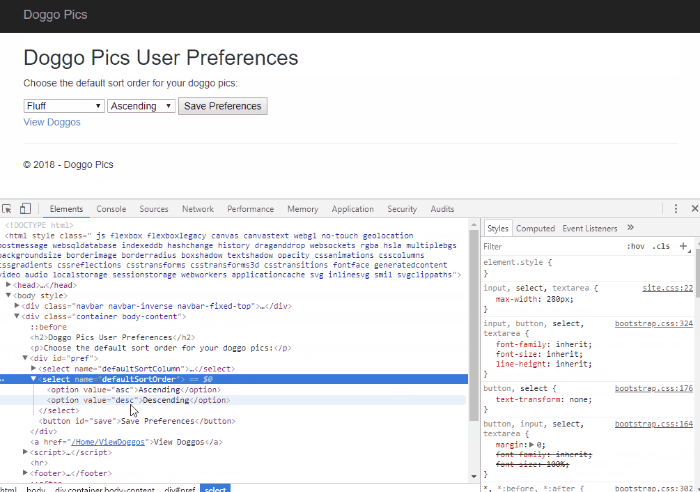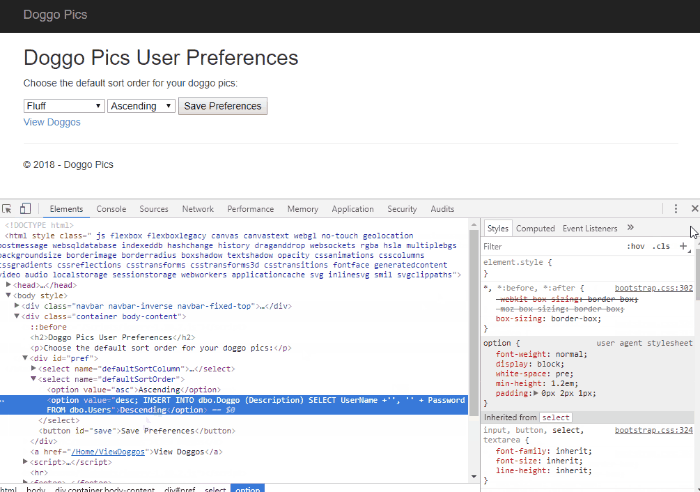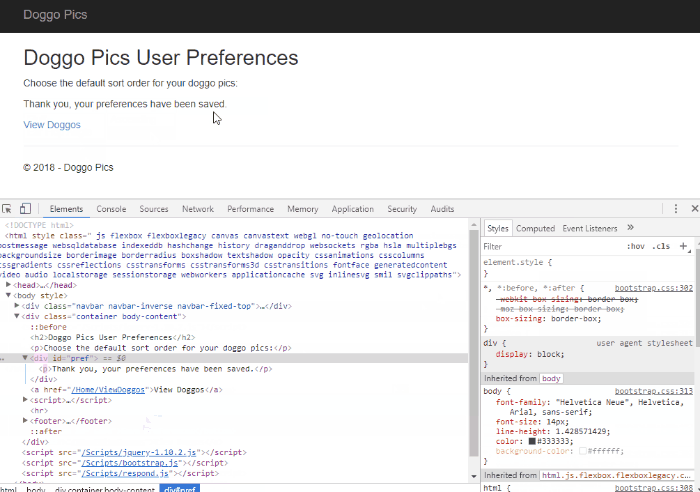
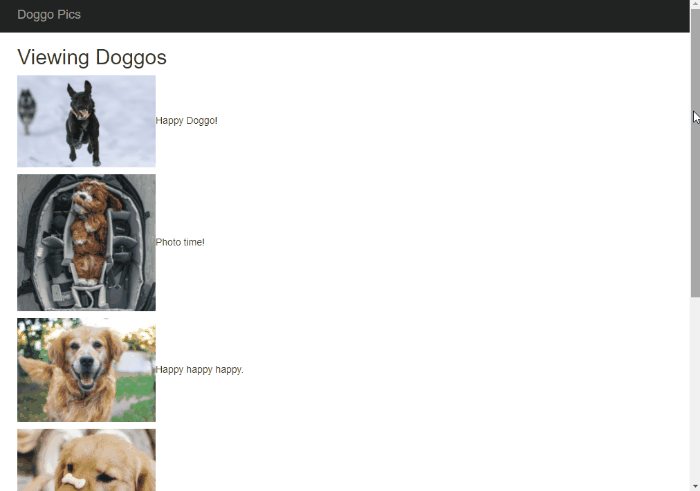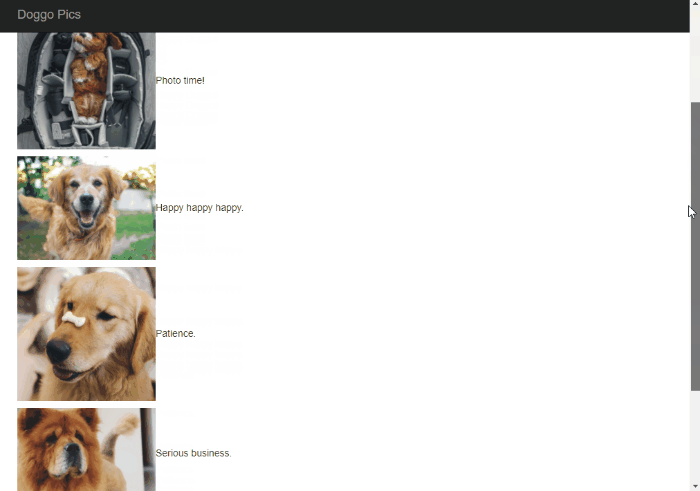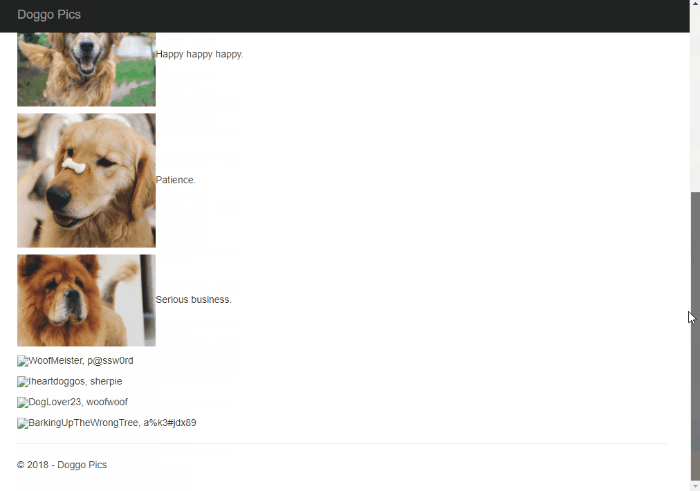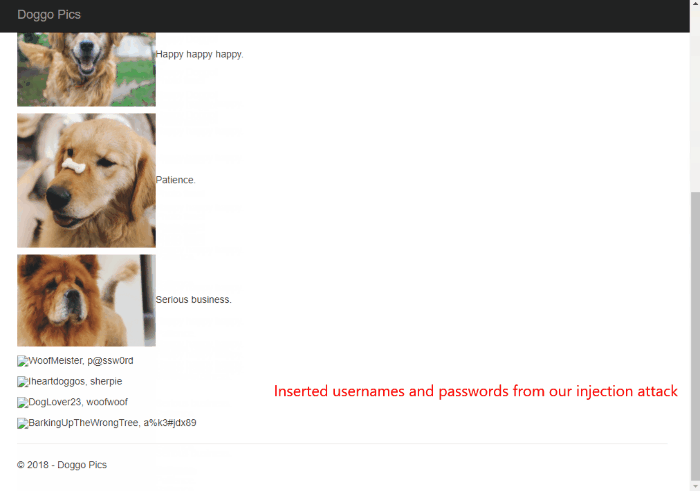
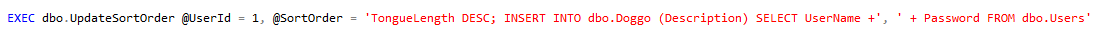This post is a response to this month's T-SQL Tuesday #100 prompt by the creator of T-SQL Tuesday himself, Adam Machanic. T-SQL Tuesday is a way for SQL Server bloggers to share ideas about a different database or professional topic every month.
This post is a response to this month's T-SQL Tuesday #100 prompt by the creator of T-SQL Tuesday himself, Adam Machanic. T-SQL Tuesday is a way for SQL Server bloggers to share ideas about a different database or professional topic every month.
This month I'm going down the science fiction route and pretending that I'm writing about a new SQL Server feature in 2026.
Fully Automatic Tuning
Watch this week's video on YouTube
I was really excited when automatic tuning capabilities were first introduced in SQL Server 2017. I couldn't wait to say so-long to the days where I had to spend time fixing basic, repetitive query tuning problems.
And while those first versions of automatic plan choice corrections were fine, there was a lot left to be desired...
Fortunately, Microsoft has fully leveraged its built-in R and Python services to allow for advanced automatic tuning to make the life of SQL Server DBAs and developers that much easier.
On By Default
Perhaps the coolest part of these new automatic tuning capabilities is that they are on by default. What this means is that databases will seem to perform better right out of the box without any kind of intervention.
I think the fact that Microsoft is confident enough to enable this by default in the on-premise version of SQL Server shows how confident they are in the capabilities of these features.
Optimize For Memory and Data Skew
While the first iterations of automatic query tuning involved swapping out query plans when SQL Server found a regression in CPU performance, the new automatic plan correction is able to factor in many more elements.
For example, instead of optimizing for CPU usage, setting the new flag OPTIMIZE_FOR_MEMORY = ON allows SQL server to minimize memory usage instead.
Also, with the addition of the new "Optimized" cardinality estimator (so now we have "Legacy", "New", and "Optimized" - who's in charge of naming these things???) SQL Server is able to swap out different estimators at the query level in order to generate better execution plans!
What time is it?
Another new addition to automatic plan corrections is SQL Server's ability to choose an appropriate execution plan based on historical time-of-day server usage.
So if a query is executing during a lull period on the server, SQL Server is intelligent enough to realize this and choose a plan that is more resource intensive. This means faster query executions at the cost of a more intensive plan - but that's OK since the server isn't being fully utilized during those times anyway.
Making use of hardware sensors
As the world continues to include more data collecting sensors everywhere, SQL Server makes good use of these data points in 2026.
Tying into the server's CPU and motherboard temperature sensors, SQL Server is able to negotiate with the OS and hardware to allow for dynamic CPU overclocking based on server demands.
While this option is not turned on by default, enabling dynamic overclocking allows for SQL Server to give itself a CPU processing boost when necessary, and then dial back down to more stable levels once finished.
This obviously won't be a feature used by everybody, but users who are willing to trade off some stability for additional analytical processing performance will love this feature.
How I Stopped Worrying And Learned To Love Automatic Tuning
At the end of the day, we are our own worst enemies. Even with the latest and greatest AI technology, we are capable of writing queries so terrible that even the smartest machine learning algorithms can't grasp.
While SQL Server's automatic tuning features work wonderfully on the boring and mundane performance problems, there are still plenty of performance problems that it leaves for us to troubleshoot.
And I love that. Let the software optimize itself and maintain a "good enough" baseline while letting me play with the really fun performance problems.
I'm sure these features will continue to evolve - but so will we, working on new problems and facing new data challenges.