
Watch this week's video on YouTube
Additional performance comparisons available in an updated post.
Starting with the 2016 release, SQL Server offers native JSON support. Although the implementation is not perfect, I am still a huge fan.
Even if a new feature like JSON support is awesome, I am only likely to use it if it is practical and performs better than the alternatives.
Today I want to pit JSON against XML and see which is the better format to use in SQL Server.
Enter XML, SQL's Bad Hombre
Full disclosure: I don't love XML and I also don't love SQL Server's implementation of it.
XML is too wordy (lots of characters wasted on closing tags), it has elements AND attributes (I don't like having to program for two different scenarios), and depending on what language you are programming in, sometimes you need schema files and sometimes you don't.
SQL Server's implementation of XML does have some nice features like a dedicated datatype that reduces storage space and validates syntax, but I find the querying of XML to be clumsy.
All XML grievances aside, I am still willing to use XML if it outperforms JSON. So let's run some test queries!
Is JSON SQL Server's New Sheriff in Town?
Although performance is the final decider in these comparison tests, I think JSON has a head start over XML purely in terms of usability. SQL Server's JSON function signatures are easier to remember and cleaner to write on screen.
The test data I'm using is vehicle year/make/model data from https://github.com/arthurkao/vehicle-make-model-data. Here's what it looks like once I loaded it into a table called dbo.XmlVsJson:
CREATE TABLE dbo.XmlVsJson
(
Id INT IDENTITY PRIMARY KEY,
XmlData XML,
JsonData NVARCHAR(MAX)
)
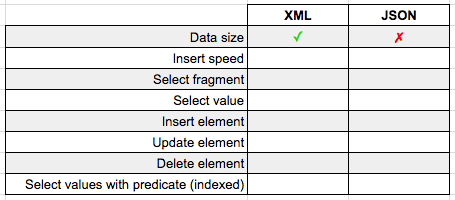
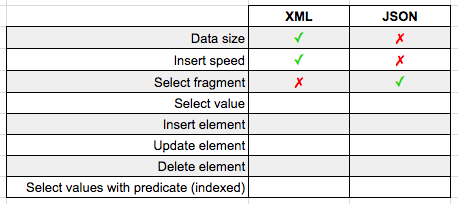
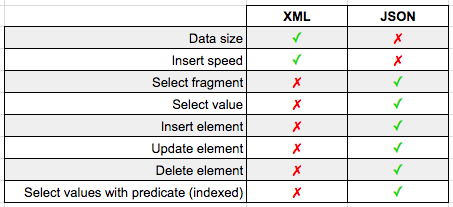
Data Size
So XML should be larger right? It's got all of those repetitive closing tags?
SELECT
DATALENGTH(XmlData)/1024.0/1024.0 AS XmlMB,
DATALENGTH(JsonData)/1024.0/1024.0 AS JsonMB
FROM
dbo.XmlVsJson

Turns out the XML is actually smaller! How can this be? This is the magic behind the SQL Server XML datatype. SQL doesn't store XML as a giant string; it stores only the XML InfoSet, leading to a reduction in space.
The JSON on the other hand is stored as regular old nvarchar(max) so its full string contents are written to disk. XML wins in this case.
So XML is physically storing less data when using the XML data type than JSON in the nvarchar(max) data type, does that mean it will insert faster as well? Here's our query that tries to insert 100 duplicates of the row from our first query:
SET STATISTICS TIME ON
INSERT INTO dbo.XmlVsJson (XmlData)
SELECT XmlData FROM dbo.XmlVsJson
CROSS APPLY
(
SELECT DISTINCT number
FROM master..spt_values
WHERE number BETWEEN 1 AND 100
)t WHERE Id = 1
GO
INSERT INTO dbo.XmlVsJson (JsonData)
SELECT JsonData FROM dbo.XmlVsJson
CROSS APPLY
(
SELECT DISTINCT number
FROM master..spt_values
WHERE number BETWEEN 1 AND 100
)t WHERE Id = 1
GO
And the results? Inserting the 100 XML rows took 613ms on my machine, while inserting the 100 JSON rows took 1305ms…XML wins again!
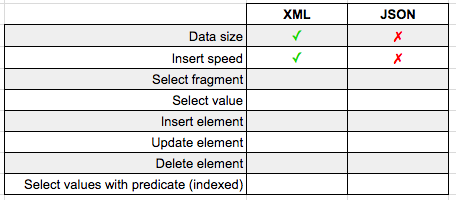
I'm guessing since the XML data type physically stores less data, it makes sense that it would also write it out to the table faster as well.
CRUD Operations
I'm incredibly impressed by SQL Server's JSON performance when compared to .NET — but how does it compare to XML on SQL Server?
Read
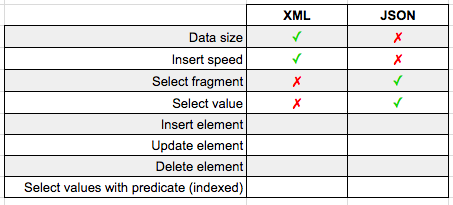
Let's select the fragment for our second car from our XML and JSON:
SELECT t.XmlData.query('/cars/car[2]')
FROM dbo.XmlVsJson t
WHERE Id = 1
SELECT JSON_QUERY(t.JsonData, '$.cars[1]')
FROM dbo.XmlVsJson t
WHERE Id = 1
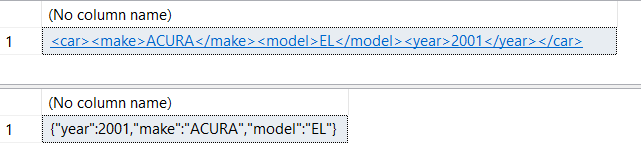
Result? JSON wins (at 0ms vs 63ms for XML) when needing to pluck out a fragment from our larger object string.
What if we want to grab a specific value instead of a fragment?
SELECT t.XmlData.value('(/cars/car[2]/model)[1]', 'varchar(100)') FROM dbo.XmlVsJson t
WHERE Id = 1
SELECT JSON_VALUE(t.JsonData, '$.cars[1].model')
FROM dbo.XmlVsJson t
WHERE Id = 1
Once again JSON wins with 0ms vs 11ms for XML.
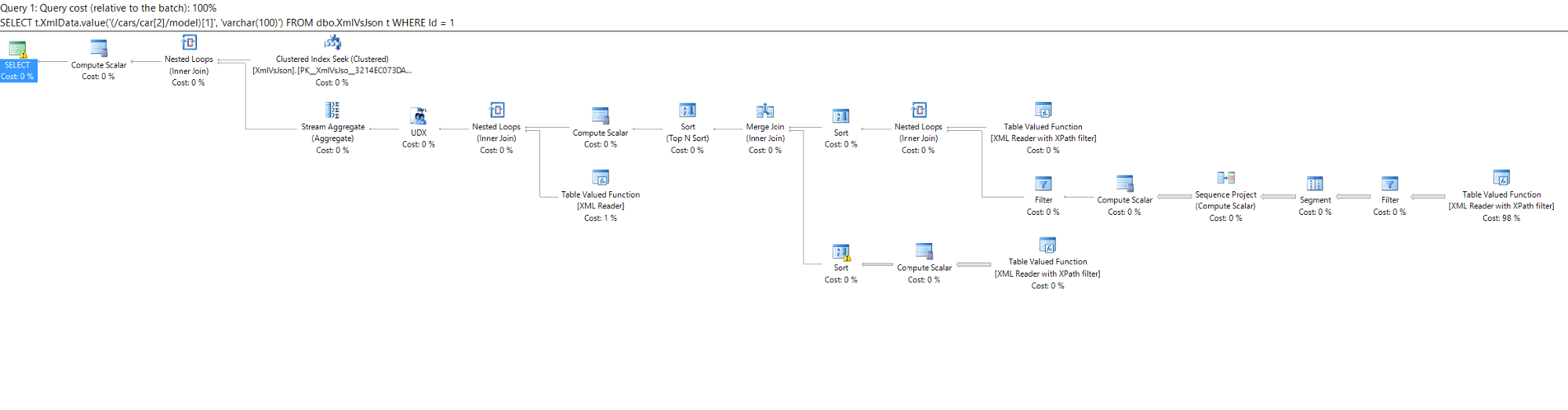
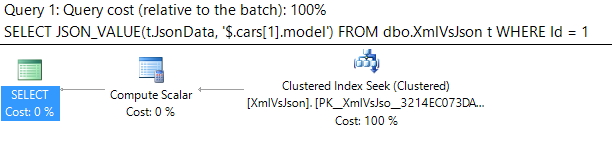
If you look at the execution plans for these last two queries, it's easy to see that XML has a lot more to do behind the scenes to retrieve the data:
XML:
JSON:
Create
We saw above that inserting rows of XML data is faster than inserting rows of JSON, but what if we want to insert new data into the object strings themselves? Here I want to insert the property "mileage" into the first car object:

UPDATE t SET XmlData.modify('
insert <mileage>100,000</mileage>
into (/cars/car[1])[1]')
FROM dbo.XmlVsJson t
WHERE Id = 1
UPDATE t SET JsonData = JSON_MODIFY(JsonData,
'$.cars[0].mileage','100,000')
FROM dbo.XmlVsJson t
WHERE Id = 1
In addition to the cleaner syntax (JSON_MODIFY() is essentially the same as a REPLACE()) the JSON insert runs in 22ms compared to the 206ms for XML. Another JSON win.
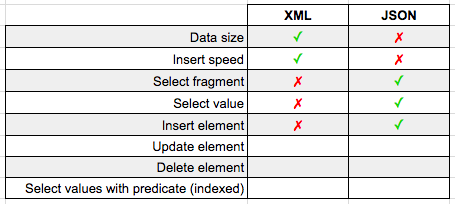
Update
Let's update the mileage properties we just added to have values of 110,000:
UPDATE t SET XmlData.modify('
replace value of (/cars/car[1]/mileage/text())[1]
with "110,000"')
FROM dbo.XmlVsJson t
WHERE Id = 1
UPDATE t SET JsonData = JSON_MODIFY(JsonData, '$.cars[0].mileage','110,000')
FROM dbo.XmlVsJson t
WHERE Id = 1

Result? JSON has the quicker draw and was able to perform this update in 54ms vs XML's 194ms.
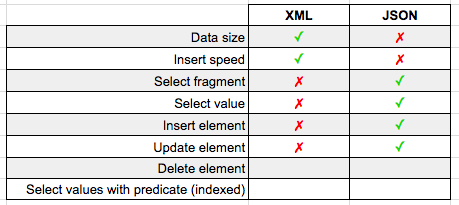
Delete
Deleting large string data, a DBA's dream *snicker*.
Let's delete the mileage property, undoing all of that hard work we just did:
UPDATE t SET XmlData.modify('
delete /cars/car[1]/mileage[1]')
FROM dbo.XmlVsJson t
WHERE Id = 1
UPDATE t SET JsonData = JSON_MODIFY(JsonData, '$.cars[0].mileage', null)
FROM dbo.XmlVsJson t
WHERE Id = 1
JSON doesn't take any time to reload and wins against XML again 50ms to 159ms.
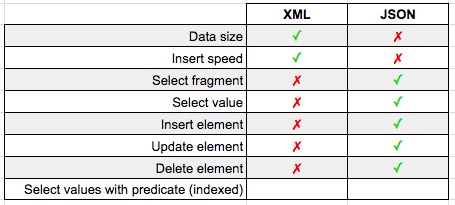
Read Part 2: Indexes
So above we saw that JSON was faster than XML at reading fragments and properties from a single row of serialized data. But our SQL Server's probably have LOTS of rows of data — how well does indexed data parsing do in our match up?
First let's expand our data — instead of storing all of our car objects in a single field, let's build a new table that has each car on its own row:
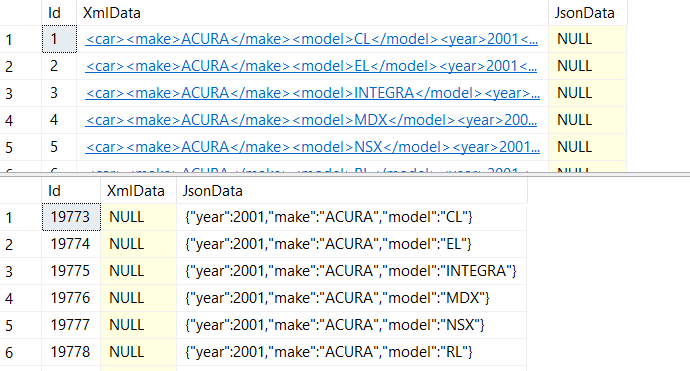
Now that we have our expanded data in our table, let's add some indexes. The XML datatype in SQL Server has its own types of indexes, while JSON simply needs a computed column with a regular index applied to it.
DROP INDEX IF EXISTS PXML_XmlData ON XmlVsJson2
CREATE PRIMARY XML INDEX PXML_XmlData
ON XmlVsJson2 (XmlData);
ALTER TABLE dbo.XmlVsJson2
ADD MakeComputed AS JSON_VALUE(JsonData, '$.make')
CREATE NONCLUSTERED INDEX IX_JsonData ON dbo.XmlVsJson2 (MakeComputed)
(Note: I also tried adding an XML secondary index for even better performance, but I couldn't get the query engine to use that secondary index on such a basic dataset)
If we try to find all rows that match a predicate:
SELECT Id, XmlData
FROM dbo.XmlVsJson2 t
WHERE t.XmlData.exist('/car/make[.="ACURA"]') = 1
SELECT Id, JsonData
FROM dbo.XmlVsJson2 t
WHERE JSON_VALUE(t.JsonData, '$.make') = 'ACURA'
XML is able to filter out 96 rows in 200ms and JSON accomplishes the same in 9ms. A final win for JSON.
Conclusion
If you need to store and manipulate serialized string data in SQL Server, there's no question: JSON is the format of choice. Although JSON's storage size is a little larger than its XML predecessor, SQL Server's JSON functions outperform XML in speed in nearly all cases.
Is there enough performance difference to rewrite all of your old XML code to JSON? Probably not, but every case is different.
One thing is clear: new development should consider taking advantage of SQL Server's new JSON functions.


 This post is a response to this month's
This post is a response to this month's 