Watch this week's video on YouTube
I like solving the daily New York Times crossword on paper. However, logging in to download the PDF every day and printing it is a pain.
In this post, I will share how I automated the whole process with curl and some bash scripting.
Downloading a pdf file with curl
curl is a command line tool for making HTTP requests (and many other data transfer protocols).
Using it to download a file like the New York Times daily crossword puzzle is as easy as:
curl "https://www.nytimes.com/svc/crosswords/v2/puzzle/print/19803.pdf" -o crossword.pdf
This works great for unauthenticated websites but poses a problem here: the New York Times crossword is a paid subscription. For the above URL to work, the HTTP request needs to be part of a session that has first been authenticated by the New York Times server.
Three HTTP requests to login
The New York Times Crossword login process looks like this:
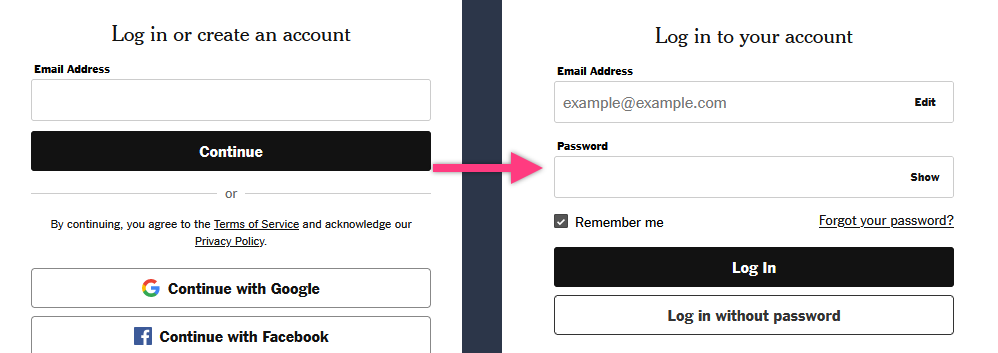
There are a total of three HTTP requests that need to happen:
- Loading the initial login page (left screenshot above)
- Clicking "Continue" after typing in your email address
- Pressing "Log In" after typing in your password
It's important to be aware that there are three requests because each request requires additional data to be sent along with it beyond the expected email address/password. Using your browser's developer tools is an easy way to identify these separate requests.
Multipage logins with curl
The first request
The first request (that loads the login page) is important because it contains two pieces of data we will need to submit with subsequent requests: 1. Some cookies that need to be carried through all login requests 2. A Cross Site Request Forgery (CSRF) token
Saving and passing along the cookies for each request is easy: the -c and -b arguments in curl to save and pass cookies to/from a local text file:
curl -c cookies.txt -b cookies.txt "https://myaccount.nytimes.com/auth/enter-email
The CSRF token is a little more work. Once the above page downloads the HTML code, we can parse the CSRF token into a variable with our bash script:
# Parse out the CSRF auth token
AUTH_TOKEN=$(curl -c cookies.txt -b cookies.txt "https://myaccount.nytimes.com/auth/enter-email?response_type=cookie&client_id=lgcl&redirect_uri=https%3A%2F%2Fwww.nytimes.com" 2>&1 | grep -oP '(?<=authToken":").*?(?=")')
# Replace HTML encoded entities
AUTH_TOKEN=${AUTH_TOKEN//=/=}
The second request
There are two more requests: the request that sends the email, then the request that sends the email and password together. These appear to be on the same web page but looking at the network traffic shows they are two separate requests.
Like before, we persist and pass the cookies for each request with the -c and -b arguments. We also pass some parameters in a JSON object after the -d flag. Finally, to mimic the browser/webpage making the request, we pass long required headers with the -H arguments:
# First page that asks for an email address
curl -c cookies.txt -b cookies.txt -X POST -d '{"email":"'$USERNAME'","auth_token":"'$AUTH_TOKEN'","form_view":"enterEmail"}' "https://myaccount.nytimes.com/svc/lire_ui/authorize-email" -H "Content-Type: application/json"
# Second page that asks for a password
curl -c cookies.txt -b cookies.txt -X POST -d '{"username":"'$USERNAME'","auth_token":"'$AUTH_TOKEN'","form_view":"login","password":"'$PASSWORD'","remember_me":"Y"}' "https://myaccount.nytimes.com/svc/lire_ui/login" -H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0' -H 'Accept: application/json' -H 'Accept-Language: en-US,en;q=0.5' --compressed -H 'Referer: https://myaccount.nytimes.com/auth/enter-email?response_type=cookie&client_id=lgcl&redirect_uri=https%3A%2F%2Fwww.nytimes.com' -H 'Content-Type: application/json' -H 'Req-Details: [[it:lui]]' -H 'Origin: https://myaccount.nytimes.com' -H 'DNT: 1' -H 'Connection: keep-alive' -H 'Sec-Fetch-Dest: empty' -H 'Sec-Fetch-Mode: cors' -H 'Sec-Fetch-Site: same-origin' -H 'TE: trailers'
Downloading the crossword puzzle
Once we finish those three requests, we should have a cookie saved to our cookies.txt file that indicates we are authorized and logged in. If all that went well, we can now run our first curl request again and the PDF puzzle download should work:
Once I have the cookie that shows I'm authenticated, I download the pdf:
# Download the print edition of the crossword
curl -b cookies.txt -s "https://www.nytimes.com/svc/crosswords/v2/puzzle/print/19803.pdf" -o crossword.pdf
There are a few more basic requests involved to variabalize the puzzle date (19803 above). If interested, you can find these additional steps in my NYTimes Crossword Download and Print script on GitHub.
Daily scheduling and printing automation.
With the PDF crossword puzzle downloaded, all I need to do is have the file automatically sent to my printer every morning.
I'm running this script on a Raspberry Pi server running Linux, so all I need to do is issue an lp command to send the file to my printer:
lp -n $NUMBER_OF_COPIES -o fit-to-page -d BrotherHL2170W crossword.pdf
That's it! I've scheduled the script with cron and now every morning at 7 am, I have two copies of that day's crossword puzzle sitting in my printer, ready to be filled with no manual intervention required.
If you want to do something similar, the full script is available on my GitHub New York Times Crossword Daily Download and Print repository.