Watch this week's video on YouTube
It's important to be aware of columns that allow NULL values since SQL Server may handle NULLs differently than you might expect.
Today I want to look at what things to consider when joining on columns containing NULL values.
Natural, Composite, NULLable keys
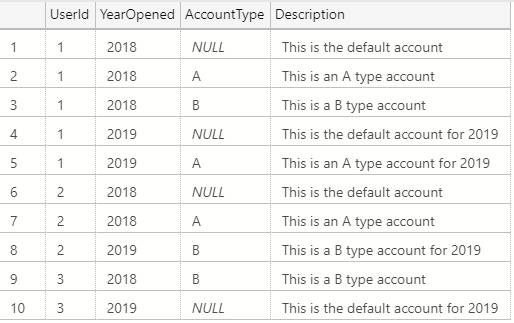
Let's pretend we have an Account table containing the accounts of various users and an AccountType table describing the different types of accounts:
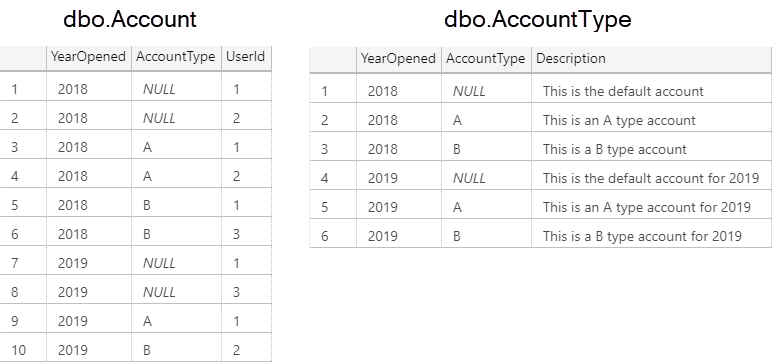
These tables have the unfortunate design characteristics of:
- They use a natural, composite key of
YearOpenedandAccountType - NULL is the valid default for
AccountType
Not that either of the above attributes are outright bad, just that we need to handle them appropriately. For example, if we want to bring back a description of each user's account, we might write a query with an inner join like this:
SELECT
a.UserId,
at.YearOpened,
at.AccountType,
at.Description
FROM
dbo.Account a
INNER JOIN dbo.AccountType at
ON a.YearOpened = at.YearOpened
AND a.AccountType = at.AccountType
Only to discover the rows with NULLs are not present:
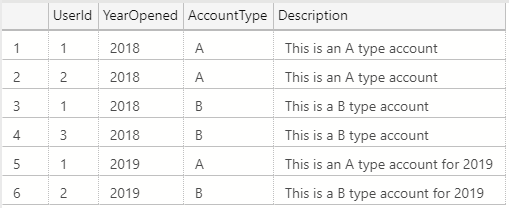
Joining on NULLs
Since it's not possible to join on NULL values in SQL Server like you might expect, we need to be creative to achieve the results we want.
One option is to make our AccountType column NOT NULL and set some other default value. Another option is to create a new column that will act as a surrogate key to join on instead.
Both of the above options would fix the problem at the source, but what about if we can only make changes to our queries?
One common approach is to convert the NULLs to some other non-NULL value using a function like COALESCE or ISNULL:
SELECT
a.UserId,
at.YearOpened,
at.AccountType,
at.Description
FROM
dbo.Account a
INNER JOIN dbo.AccountType at
ON a.YearOpened = at.YearOpened
AND ISNULL(a.AccountType,'`') = ISNULL(at.AccountType,'`')
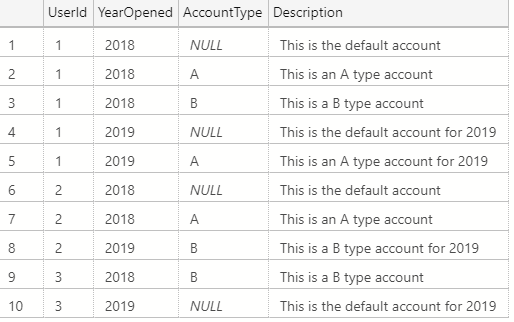
While this returns the results we want, there are two major issues with this approach:
- In the above example we converted NULLs to the ` character. If we had a valid ` character in our data, we would get logically incorrect joins.
- Our query can no longer perform index seeks.
The first issue isn't a huge deal if you can guarantee the character you are replacing NULLs with will never appear in the column of data.
The second issue is more important since ISNULL prevents your query from being SARGable and will cause poor performance on large tables of data.
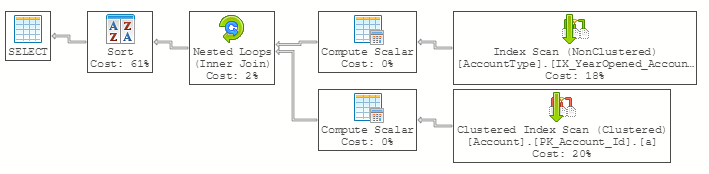
Those Compute Scalar operators are forcing SQL Server to Scan the indexes and compute a value for every row.
A More Efficient Solution
If using a function like ISNULL hurts the performance of our queries, what can we do instead?
SELECT
a.UserId,
at.YearOpened,
at.AccountType,
at.Description
FROM
dbo.Account a
INNER JOIN dbo.AccountType at
ON a.YearOpened = at.YearOpened
AND (a.AccountType = at.AccountType OR (a.AccountType IS NULL AND at.AccountType IS NULL))
This produces the same exact results while allowing SQL Server to Seek when possible and avoid costly row by row computations:
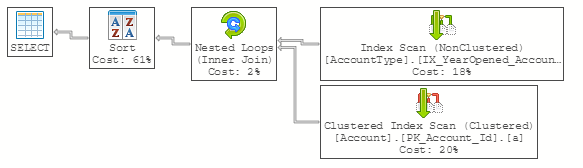
While there are a few more variations that can achieve the same results using different execution plans (writing a query that joins non-nulls and unioning it with a query that selects only the nulls, using a computed column to convert the NULLs to non-null values, etc...) the key to good performance is to choose a solution that will not force SQL Server to compute values for every single row.