Watch this week's video on YouTube
When beginning to learn SQL, at some point you learn that indexes can be created to help improve the performance of queries.
Creating your first few indexes can be intimidating though, particularly when trying to understand what order to put your key columns in.
Today we'll look at how row store indexes work to understand whether index column order matters.
Heap: Stack of Pages
 Imagine a stack of loose leaf pages. This collection of pages is our table.
Imagine a stack of loose leaf pages. This collection of pages is our table.
Each page has information about a bird on it - the bird's name, picture, description, habitat, migration patterns, visual markings, etc... You can think of each of these pages as a row of data.
The problem with this stack of pages is that there is no enforced order: it's a heap. Without any enforced order, searching for individual birds is time consuming; in order to find a particular bird, for example a blue jay, you would have to go through the stack of pages one at a time until you find the blue jay page.
The scanning doesn't stop there though. Even though we found a blue jay page, there's no way for us to guarantee that there are no other blue jay pages in the stack. This means we have to continue flipping through every page until we finish searching through the whole heap of pages.
Having to do this process every single time we need to retrieve data from our bird table is painful. To make our job easier, we can define and enforce an order on the data by defining a clustered index.
Clustered Index: Bound Pages
 To make searching through our pages easier, we sort all of the pages by bird name and glue on a binding. This book binding now keeps all of our pages in alphabetical order by bird name.
To make searching through our pages easier, we sort all of the pages by bird name and glue on a binding. This book binding now keeps all of our pages in alphabetical order by bird name.
The SQL version of a book binding is a clustered index. The clustered index is not an additional object to our data - it is that same exact table data, but now with an enforced sort order.
Having all of our data in sorted order by bird name makes certain queries really fast and efficient - instead of having to scan through every page to find the blue jay entry, we can now quickly flip to the "B" section, then the "BL" section, then the "BLU" section, etc... until we find BLUE JAY. This is done quickly and efficiently because we know where to find blue jays in the book because the bird names are stored in alphabetical order.
Even better, after we find the blue jay page, we flip to the next page and see a page for cardinal. Since we know all of the entries are stored alphabetically, we know that once we get to the next bird we have found all of our blue jay pages and don't need to continue flipping through the rest of the book.
While the clustered index allows us to find birds by name quickly, it's not perfect; since the clustered index is the table, it contains every property (column) of each bird, which is a lot of data!
Having to constantly reference this large, clustered index for each of my queries can be too cumbersome. For most of our queries, we could get by with condensed version of my bird book that only contains the most essential information in it.
Nonclustered Index: Cut and Copy
 Let's say we want a lighter-weight version of our book that contains the most relevant information (bird name, color, description).
Let's say we want a lighter-weight version of our book that contains the most relevant information (bird name, color, description).
We can photocopy the entire book and then cut out and keep only the pieces of information that are relevant while discarding the rest. If we paste all of those relevant pieces of information into a new book, still sorted by bird name, we now have a second copy of our data. This is our nonclustered index.
This nonclustered index contains all of the same birds as my clustered index, just with fewer columns. This means I can fit multiple birds onto a page, requiring me to flip through fewer pages to find the bird I need.
If we ever need to look up additional information about a particular bird that's not in our nonclustered index, we can always go back to my giant clustered index and retrieve any information we need.
With the lighter-weight nonclustered index in-hand, we go out to the woods to start identifying some birds.
Upon spotting an unfamiliar bird in our binoculars, we can flip open the nonclustered index to identify the bird.
The only problem is, since we don't know this bird's name, our nonclustered index by bird name is of no help. We end up having to flip through each page one at a time trying to identify the bird instead of flipping directly to the correct page.
For these types of inquires where we want to identify a bird don't know the bird's name, a different index would beneficial...
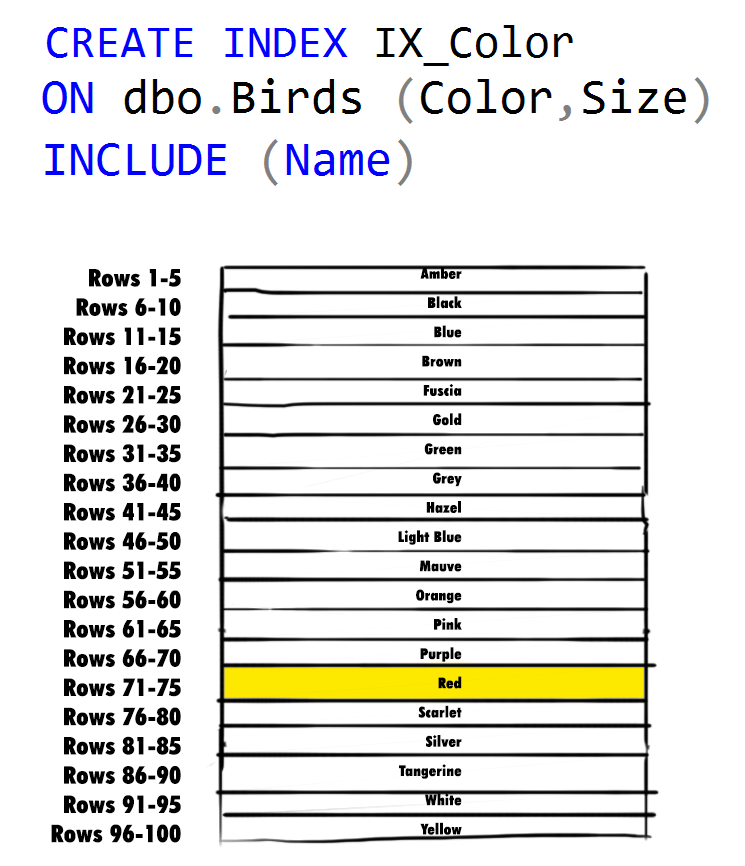
Nonclustered Index 2: Color Bugaloo
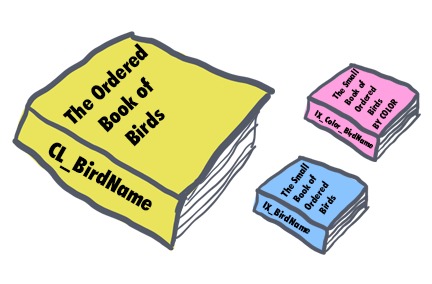 Instead of having a nonclustered index sorted by bird name, what we really need is a way to filter down to the list of potential birds quickly.
Instead of having a nonclustered index sorted by bird name, what we really need is a way to filter down to the list of potential birds quickly.
One way we can do this is to create another copy of my book, still containing just bird names, colors, and descriptions, but this time order the book pages so they are in order of color first, then bird name.
When trying to identify an unknown bird, we can first limit the number of pages to search through by filtering on the bird's color. In our case, color is a highly selective trait, since it filters down our list of potential birds to only a small subset of the whole book. In our blue jay example, this means we would find the small subset of pages that contain blue birds, and then just check each one of those pages individually until we find the blue jay.
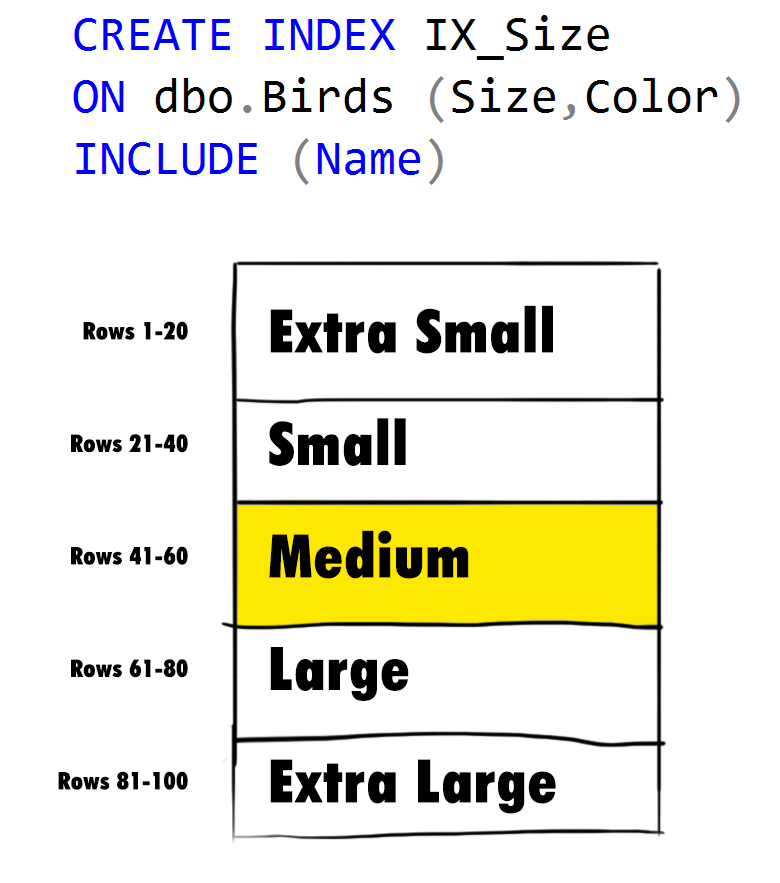
Order Matters
Indexes aren't magic; their high-performance capabilities come from the fact that they store data in a predetermined order. If your query can utilize data stored in that order, great!
However, if your query wants to filter down on color first, but your index is sorted on bird name, then you'll be out of luck. When it comes to determining what column should be the first key in your index, you should choose whichever one will be most selective (which one will filter you down to the fewest subset of results) for your particular query.
There's a lot more optimizing that can be done with indexes, but correctly choosing the order of columns for your index key is an essential first step.
Want to learn even more about index column order? Be sure to check out this post on cardinality.

 I wish all of my execution plans were this simple.
I wish all of my execution plans were this simple. This execution plan looks the same, but you'll notice the smaller, more data dense index is being used.
This execution plan looks the same, but you'll notice the smaller, more data dense index is being used.




 Photo by
Photo by