Watch this week's video on YouTube
While I normally prefer formatting my query results in a downstream app/reporting layer, sometimes I can't get around adding some business formatting logic to my SQL queries.
Today I want to show you four different ways to conditionally output rows of data based on a SQL query.
Setting Up The Base Query
You've probably worked with a query that results in either 0 or 1 rows being returned:
DECLARE @CurrentDatetime datetime = getdate();
SELECT
1 AS AreSecondsDivisbleBy2,
@CurrentDatetime AS CurrentDatetime
WHERE
DATEPART(second,@CurrentDatetime) % 2 = 0
If you put that query into a derived table and add some IIF() logic on top of it, you now have a situation where you your result may contain a row with one of two distinct values or no rows at all:
If you put that query into a derived table and add some IIF() logic on top of it, you now have a situation where you your result may contain a row with one of two distinct values or no rows at all:
DECLARE @CurrentDatetime datetime = GETDATE();
SELECT
IIF(DATEPART(second,d.CurrentDatetime) % 3 = 0, 1,0) AS AreSecondsDivisbleBy3And2,
d.CurrentDatetime
FROM
(
SELECT
1 AS AreSecondsDivisbleBy2,
@CurrentDatetime AS CurrentDatetime
WHERE
DATEPART(second,@CurrentDatetime) % 2 = 0
) d
(Note: if you ever need to know whether the seconds part of the current time is divisible by 3 and 2, use SELECT IIF(DATEPART(second,GETDATE()) % 6 = 0,1,0) and not this monstrosity of a query I'm creating to demonstrate a scenario when you dependent derived table logic).
Sometimes we may want to force certain scenarios based on the output of the query above. Here are few common patterns that I find myself doing when needing to meet certain business requirements of queries to return data conditionally.
Always Return 1 Row
Let's say we are happy with getting a result value of 0 or 1 for AreSecondDivisbleBy3And2, but want to additionally return some other value when our derived table returns no rows. We can accomplish this with a UNION ALL and some sorting:
DECLARE @CurrentDatetime datetime = GETDATE();
SELECT TOP 1
AreSecondsDivisbleBy3And2,
CurrentDatetime
FROM
(
SELECT
IIF(DATEPART(second,CurrentDatetime) % 3 = 0, 1,0) AS AreSecondsDivisbleBy3And2,
d.CurrentDatetime,
0 AS OrderPrecedence
FROM
(
SELECT
1 AS AreSecondsDivisbleBy2,
@CurrentDatetime AS CurrentDatetime
WHERE
DATEPART(second,@CurrentDatetime) % 2 = 0
) d
UNION ALL
SELECT
-1 AS AreSecondsDivisbleBy3And2,
@CurrentDatetime AS CurrentDatetime,
1 AS OrderPrecedence
) p
ORDER BY
OrderPrecedence
We can limit our query to return TOP 1 and then add an OrderPrecedence column to determine which query result row to return. If our original query has a row of data, it will be returned because of it's OrderPrecedence. If our original query returns 0 rows, our fall back UNION ALL default value of -1 will be returned.
Return 1 row when value is 1, 0 rows when value is 0
What about a situation where we want to return a row when AreSecondsDivisbleBy3And2 is equal to 1, but no row when it is equal to 0?
The IIF function and CASE statements work great for conditionally returning a value in a SELECT, but how can we conditionally return a row? Here's one approach:
DECLARE @CurrentDatetime datetime = GETDATE();
SELECT
AreSecondsDivisibleBy3And2,
CurrentDatetime
FROM
(
SELECT
IIF(DATEPART(second,d.CurrentDatetime) % 3 = 0, 1,0) AS AreSecondsDivisibleBy3And2,
CurrentDatetime
FROM
(
SELECT
1 AS AreSecondsDivisbleBy2,
@CurrentDatetime AS CurrentDatetime
WHERE
DATEPART(second,@CurrentDatetime) % 2 = 0
) d
) d1
INNER JOIN
(
SELECT
0 AS ValueToNotReturn
) d2
ON d1.AreSecondsDivisibleBy3And2 != d2.ValueToNotReturn
In this scenario, we return a row when our value is 1, but do not return a row when the value is 0 or our derived table doesn't return any rows.
We use an INNER JOIN to filter out the row value that we want to return 0 rows.
Return 1 row when null, and 0 rows when the value is 1 or 0
In this scenario we want to return no rows when AreSecondsDivisibleBy3And2=1 and a row when its not.
I've never had a real-world use for this one, but it's essentially a combination of the first two solutions.
SELECT
AreSecondsDivisibleBy3And2,
CurrentDatetime
FROM
(
SELECT TOP 1
AreSecondsDivisibleBy3And2,
CurrentDatetime
FROM
(
SELECT
IIF(DATEPART(second,d.CurrentDatetime) % 3 = 0, 1,0) AS AreSecondsDivisibleBy3And2,
d.CurrentDateTime,
0 AS OrderPrecedence
FROM
(
SELECT
1 AS AreSecondsDivisbleBy2,
@CurrentDatetime AS CurrentDatetime
WHERE
DATEPART(second,@CurrentDatetime) % 2 = 0
) d
UNION ALL
SELECT
-1 AS AreSecondsDivisibleBy3And2,
@CurrentDatetime AS CurrentDatetime,
1 AS OrderPrecedence
)u
ORDER BY
OrderPrecedence
) d1
INNER JOIN
(
SELECT
-1 AS ValueToNotReturn
) d2
ON d1.AreSecondsDivisibleBy3And2 = d2.ValueToNotReturn
This one is by far the most difficult one to logic through, but it's a pure reversal of return no rows when rows are present and return a row when no rows are present.
Always return 0 rows
I'm not exactly sure what the business case for never returning any rows would be, but this one is pretty simple: just add a condition that will always evaluate to false:
DECLARE @CurrentDatetime datetime = GETDATE();
SELECT
IIF(DATEPART(second,d.CurrentDatetime) % 3 = 0, 1,0) AS AreSecondsDivisibleBy3And2
FROM
(
SELECT
1 AS AreSecondsDivisbleBy2,
@CurrentDatetime AS CurrentDatetime
WHERE
DATEPART(second,@CurrentDatetime) % 2 = 0
) d
WHERE
1=0
Since 1=0 will never be true, your query will never return any results regardless of what kind of logic is happening in your SELECT or derived table.
 A homage to one of my favorite
A homage to one of my favorite  Need a ultra HD wide display to fit this all on one screen.
Need a ultra HD wide display to fit this all on one screen.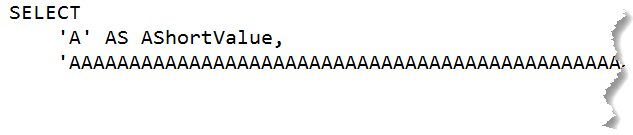
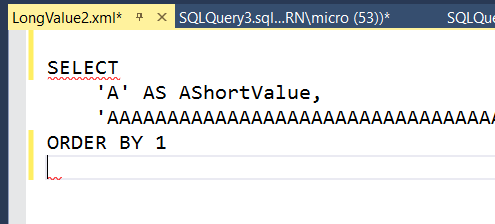 IntelliSense complains but I'm OK with it
IntelliSense complains but I'm OK with it
 FOR XML PATH is one of the most abused SQL Server functions.
FOR XML PATH is one of the most abused SQL Server functions. A significant portion of Yellowstone National Park sits on top of a
A significant portion of Yellowstone National Park sits on top of a