Watch this week's video on YouTube
A while back I learned that it's possible to create temporary stored procedures in SQL Server.
I never put that knowledge into practice however because I struggled to think of a good use case for when a temporary stored procedure would be preferable to a permanent stored procedure.
Not long ago I encountered a scenario where using a temporary stored procedure was the perfect solution to my problem.
Building New Tables
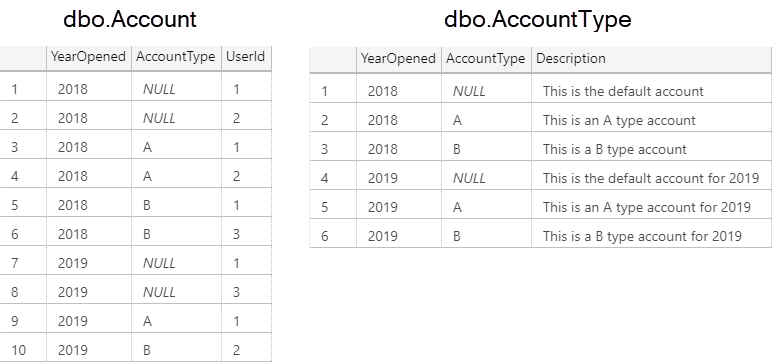
Recently, I had to build a new version of a legacy table because the legacy table's upstream data source was going to be retired.
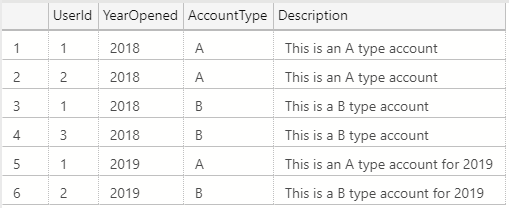
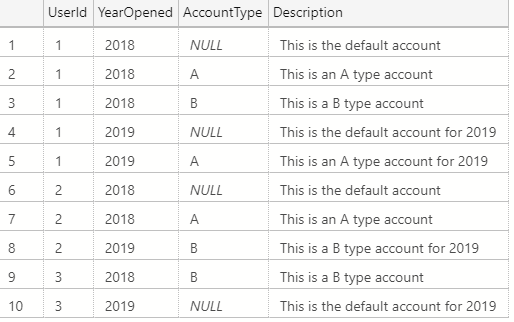
The new table would contain all the same data as the legacy table, but populated from the new data source. Additionally, the new table would also include additional rows and columns. After building the final table, the plan was to create a view to replace the functionality of the legacy table.
I had to spend quite a bit of time writing a fairly elaborate query to make the data for the new data source match what was appearing in the legacy table (remember my gaps and islands post from a few weeks back? Imagine that on steroids).
Before building out the new ETL and tables though, I wanted to be able to test that the new query was producing the correct results. This was challenging because some of the data sources were on other servers. I was in a catch 22: couldn't test the data because I didn't build the ETL yet, but I didn't want to build the ETL until I tested the results.
Less Than Ideal Options
To make matters worse, I was only able to test my query using data in the production environment.
I thought of putting my new query into a stored procedure to make the logic easier to test. But with the production elevate process being length and restricted, I couldn't easily put my parameterized query into a permanent stored procedure to test my query with.
At this point I had a few options:
- Don't test anything and just build out the tables and ETL in production. Cross my fingers and hope it all works, fixing any issues after the fact.
- Create a permanent stored procedure with the query and elevate it to production. Hope that I don't have to make changes and go through the slow elevate process again.
- Run the query over and over again with different parameters.
I didn't like the first two options because of the amount of time I would lose trying to elevate new tables or procedures into production.
The third option wasn't ideal either because while it would allow me to iterate quickly, documenting all of my tests would involve a massive file that would not be easy to navigate or change.
What I needed was a way to run a query through many different parameters in a concise manner without making any permanent production changes.
Temporary Stored Procedures for Regression Testing
Since I have access to create temporary stored procedures in production, I was able to create a temporary procedure containing my complex query:
CREATE PROCEDURE #ComplexBusinessLogic
@parm1 int
AS
BEGIN
/* This isn't the actual query. The real one was ugly and hundreds of lines long.*/
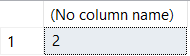
SELECT CASE @parm1
WHEN 1 THEN 'A'
WHEN 2 THEN 'B'
WHEN 3 THEN 'C'
END AS ResultValue
END;
As I mention in the comment of the stored procedure, this query was huge. If I wanted to execute it multiple times with different parameter values to test with, I'd have a gigantic file that would be difficult to navigate and easy to make errors in.
Instead, the temporary stored procedure made it easy to document my tests and execute the query as many times as needed:
/* Test for when parameter is 1 */
EXEC #ComplexBusinessLogic @parm1 = 1;
/* Test for scenario 2 */
EXEC #ComplexBusinessLogic @parm1 = 2;
/* The rarely occuring but very important test scenario 3 */
EXEC #ComplexBusinessLogic @parm1 = 3
I was able then to clearly define all of my tests and run them against the production data without creating any permanent production objects. This was great because I did find errors with my logic, but I was able to fix them and retry my tests over and over again until everything ran without issues.
Testing in Production
Ideally I wouldn't have to use this solution. It would have been much better to have data to test with in a non-production environment. Using a temporary stored procedure to test in production is a hack to get around environment restrictions.
However, what is ideal and what is real-world doesn't always align. Sometimes a hack helps meet deadlines when better options aren't available. In this instance, temporary stored procedures helped make testing a breeze.