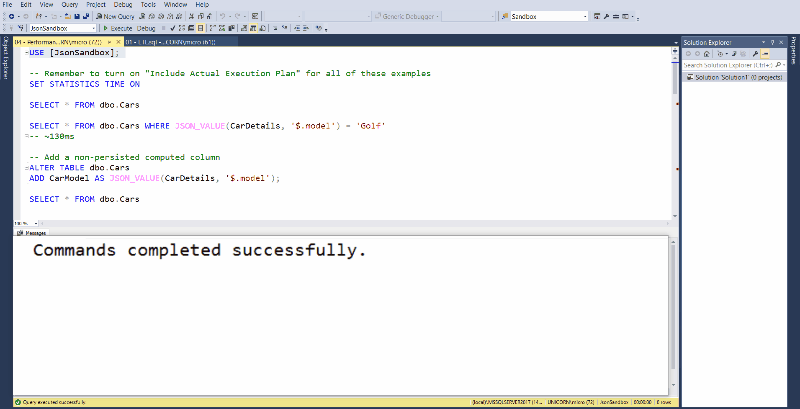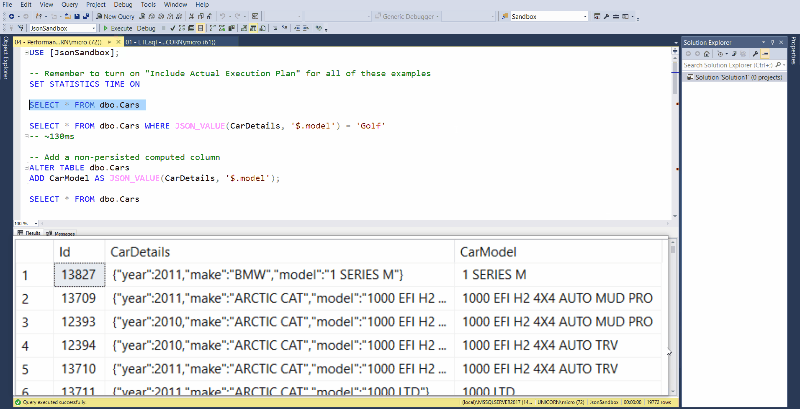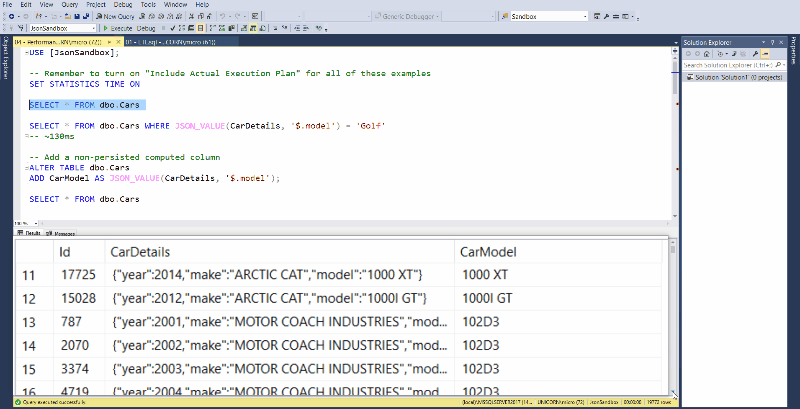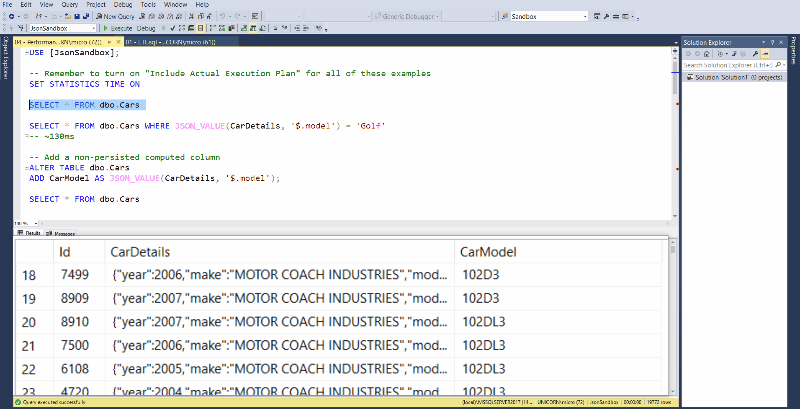
This post is a response to this month's T-SQL Tuesday #106 prompt by Steve Jones. T-SQL Tuesday is a way for the SQL Server community to share ideas about different database and professional topics every month.
This post is a response to this month's T-SQL Tuesday #106 prompt by Steve Jones. T-SQL Tuesday is a way for the SQL Server community to share ideas about different database and professional topics every month.
This month's topic asks to share our experiences with triggers in SQL Server.
Watch this week's video on YouTube
Triggers are something that I rarely use. I don't shy away from them because of some horrible experience I've had, but rather I rarely have a good need for using them.
The one exception is when I need a poor man's temporal table.
Temporal Table <3
When temporal tables were added in SQL Server 2016 I was quick to embrace them.
A lot of the data problems I work on benefit from being able to view what data looked like at a certain point back in time, so the easy setup and queriability of temporal tables was something that I immediately loved.
No System Versioning For You
Sometimes I can't use temporal tables though, like when I'm forced to work on an older version of SQL Server.
Now, this isn't a huge issue; I can still write queries on those servers to achieve the same result as I would get with temporal tables.
But temporal tables have made me spoiled. They are easy to use and I like having SQL Server manage my data for me automatically.
Fake Temporal Tables With Triggers
I don't want to have to manage my own operational versus historical data and write complicated queries for "point-in-time" analysis, so I decided to fake temporal table functionality using triggers.
Creating the base table and history table are pretty similar to that of a temporal table, just without all of the fancy PERIOD and GENERATED ALWAYS syntax:
CREATE TABLE dbo.Birds
(
Id INT IDENTITY PRIMARY KEY,
BirdName varchar(50),
SightingCount int,
SysStartTime datetime2 DEFAULT SYSUTCDATETIME(),
SysEndTime datetime2 DEFAULT '9999-12-31 23:59:59.9999999'
);
GO
CREATE TABLE dbo.BirdsHistory
(
Id int,
BirdName varchar(50),
SightingCount int,
SysStartTime datetime2,
SysEndTime datetime2
) WITH (DATA_COMPRESSION = PAGE);
GO
CREATE CLUSTERED INDEX CL_Id ON dbo.BirdsHistory (Id);
GO
The single UPDATE,DELETE trigger is really where the magic happens though. Everytime a row is updated or deleted, the trigger inserts the previous row of data into our history table with correct datetimes:
CREATE TRIGGER TemporalFaking ON dbo.Birds
AFTER UPDATE, DELETE
AS
BEGIN
SET NOCOUNT ON;
DECLARE @CurrentDateTime datetime2 = SYSUTCDATETIME();
/* Update start times for newly updated data */
UPDATE b
SET
SysStartTime = @CurrentDateTime
FROM
dbo.Birds b
INNER JOIN inserted i
ON b.Id = i.Id
/* Grab the SysStartTime from dbo.Birds
Insert into dbo.BirdsHistory */
INSERT INTO dbo.BirdsHistory
SELECT d.Id, d.BirdName, d.SightingCount,d.SysStartTime,ISNULL(b.SysStartTime,@CurrentDateTime)
FROM
dbo.Birds b
RIGHT JOIN deleted d
ON b.Id = d.Id
END
GO
The important aspect to this trigger is that we always join our dbo.Birds table to our inserted and deleted tables based on the primary key, which is the Id column in this case.
If you try to insert/update/delete data from the dbo.Birds table, the dbo.BirdsHistory table will be updated exactly like a regular temporal table would:
/* inserts */
INSERT INTO dbo.Birds (BirdName, SightingCount) VALUES ('Blue Jay',1);
GO
INSERT INTO dbo.Birds (BirdName, SightingCount) VALUES ('Cardinal',1);
GO
BEGIN TRANSACTION
INSERT INTO dbo.Birds (BirdName, SightingCount) VALUES ('Canada Goose',1)
INSERT INTO dbo.Birds (BirdName, SightingCount) VALUES ('Nuthatch',1)
COMMIT
GO
BEGIN TRANSACTION
INSERT INTO dbo.Birds (BirdName, SightingCount) VALUES ('Dodo',1)
INSERT INTO dbo.Birds (BirdName, SightingCount) VALUES ('Ivory Billed Woodpecker',1)
ROLLBACK
GO
/* updates */
UPDATE dbo.Birds SET SightingCount = SightingCount+1 WHERE id = 1;
GO
UPDATE dbo.Birds SET SightingCount = SightingCount+1 WHERE id in (2,3);
GO
BEGIN TRANSACTION
UPDATE dbo.Birds SET SightingCount = SightingCount+1 WHERE id =4;
GO
ROLLBACK
/* deletes */
DELETE FROM dbo.Birds WHERE id = 1;
GO
DELETE FROM dbo.Birds WHERE id in (2,3);
GO
BEGIN TRANSACTION
UPDATE dbo.Birds SET SightingCount = SightingCount+1 WHERE id =4;
GO
ROLLBACK
If you run each of those batches one at a time and check both tables, you'll see how the dbo.BirdsHistory table keeps track of all of our data changes.
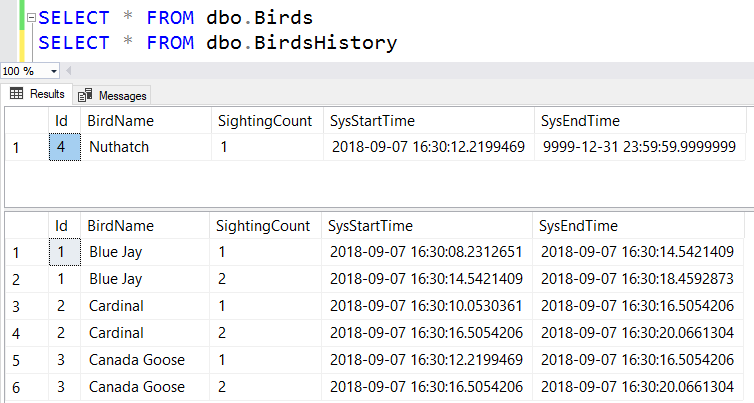
Now seeing what our dbo.Birds data looked like at a certain point-in-time isn't quite as easy as a system versioned table in SQL Server 2016, but it's not bad:
DECLARE @SYSTEM_TIME datetime2 = '2018-09-07 16:30:11';
SELECT *
FROM
(
SELECT * FROM dbo.Birds
UNION ALL
SELECT * FROM dbo.BirdsHistory
) FakeTemporal
WHERE
@SYSTEM_TIME >= SysStartTime
AND @SYSTEM_TIME < SysEndTime;
Real Performance
One reason many people loath triggers is due to their potential for bad performance (particular when many triggers get chained together).
I wanted to see how this trigger solution compares to an actual temporal table. While searching for good ways to test this difference, I found that Randolph West has done some testing on trigger-based temporal tables. While our solutions are different, I like their performance testing methodology: view the transaction log records for real temporal tables and compare them to those of the trigger-based temporal tables.
I'll let you read the details of how to do the comparison test in their blog post but I'll just summarize the results of my test: the trigger based version is almost the same as a real system versioned temporal table.
Because of how I handle updating the SysStartTime column in my dbo.Birds table, I get one more transaction than a true temporal table:
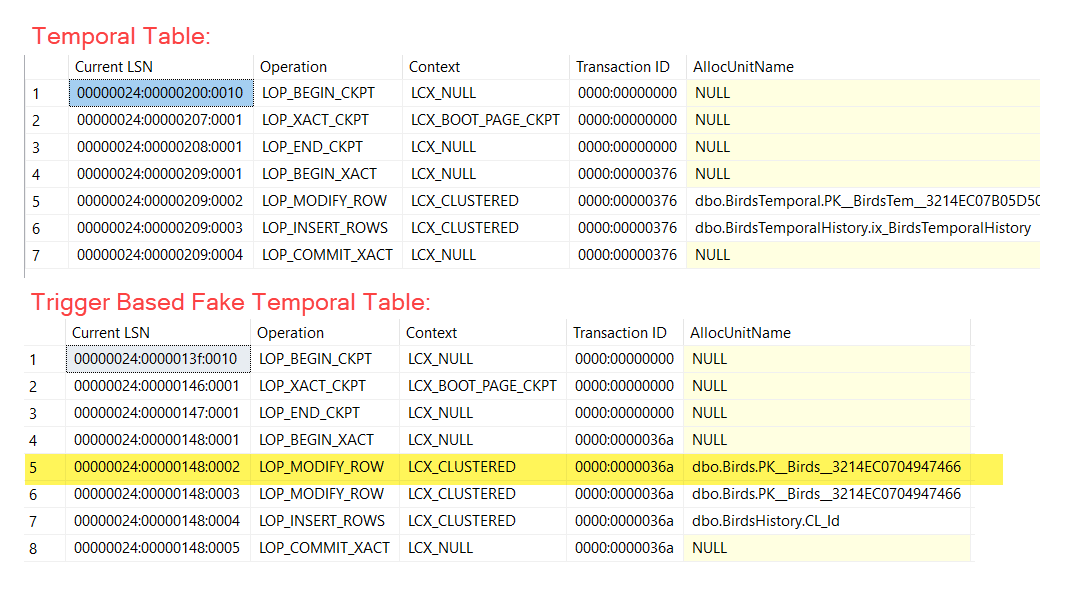
You could make the trigger solution work identical to the true temporal table (as Randolph does) if you are willing to make application code changes to populate the SysStartTime column on insert into dbo.Birds.
Conclusion
For my purposes, the trigger-based temporal table solution has a happy ending. It works for the functionality that I need it for and prevents me from having to manage a history table through some other process.
If you decide to use this in your own pre-2016 instances, just be sure to test the functionality you need; while it works great for the purposes that I use temporal tables for, your results may vary if you need additional functionality (preventing truncates on the history table, defining a retention period for the history, etc... are all features not implemented in the examples above).




 Look at those beautifully zoomed in results!
Look at those beautifully zoomed in results!