Watch this week's video on YouTube
A few months ago I was presenting for a user group when someone asked the following question:
Does a query embedded in a stored procedure execute faster than that same query submitted to SQL Server as a stand alone statement?
The room was pretty evenly split on the answer: some thought the stored procedures will always perform faster while others thought it wouldn't really matter.
In short, the answer is that the query optimizer will treat a query defined in a stored procedure exactly the same as a query submitted on its own.
Let's talk about why.
Start with a Plan
While submitting an "EXEC <stored procedure>" statement to SQL Server may require fewer packets of network traffic than submitting the several hundred (thousands?) lines that make up the query embedded in the procedure itself, that is where the efficiencies of a stored procedure end*.
*NOTE: There are certain SQL Server performance features, like temporary object caching, natively compiled stored procedures for optimized tables, etc… that will improve the performance of a stored procedure over an ad hoc query. However in my experience, most people aren't utilizing these types of features so it's a moot point.
After receiving the query, SQL Server's query optimizer looks at these two submitted queries exactly the same. It will check to see if a cached plan already exists for either query (and if one does, it will use that), otherwise it will send both queries through the optimization process to find a suitable execution plan. If the standalone query and the query defined in the stored procedure are exactly the same, and all other conditions on the server are exactly the same at the time of execution, SQL Server will generate the same plans for both queries.
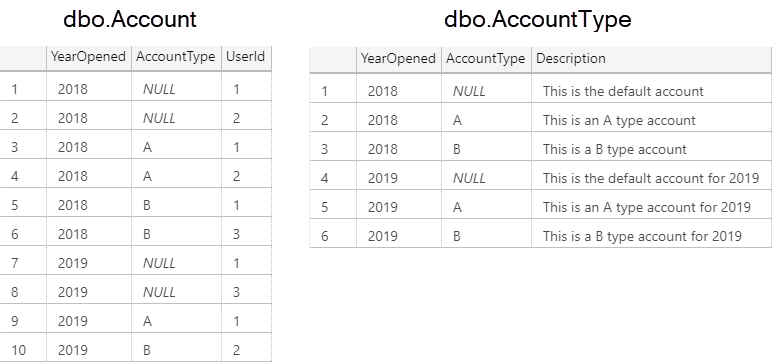
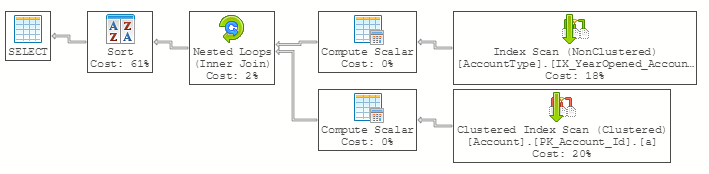
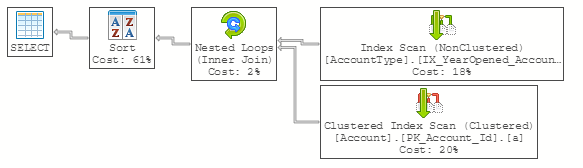
To prove this point, let's look at the following query's plan as well as the plan for a stored procedure containing that same query:
CREATE OR ALTER PROCEDURE dbo.USP_GetUpVotes
@UserId int
AS
SELECT
COUNT(*) AS UpVotes
FROM
dbo.Posts p
INNER JOIN Votes v
ON v.PostId = p.Id
WHERE
p.OwnerUserId = @UserId
and VoteTypeId = 2
ORDER BY UpVotes DESC
EXEC dbo.USP_GetUpVotes 23
DECLARE @UserId int = 23
SELECT
COUNT(*) AS UpVotes
FROM
dbo.Posts p
INNER JOIN Votes v
ON v.PostId = p.Id
WHERE
p.OwnerUserId = @UserId
and VoteTypeId = 2
ORDER BY UpVotes DESC
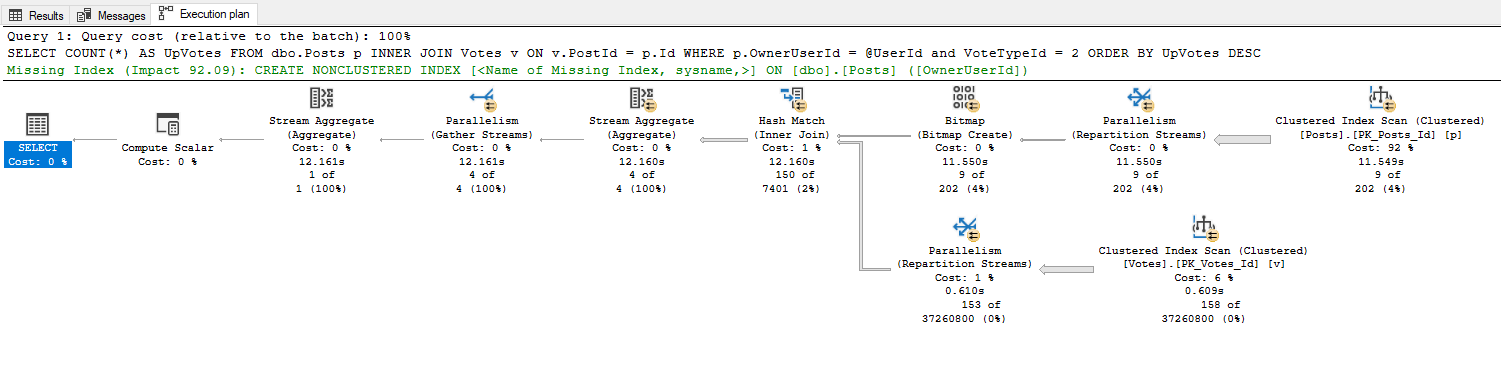
As you can see, the optimizer generates identical plans for both the standalone query and the stored procedure. In the eyes of SQL Server, both of these queries will be executed in exactly the same way.
But I Swear My Stored Procedures Run Faster!
I think that a lot of the confusion for thinking that stored procedures execute faster comes from caching.
As I wrote about a little while back, SQL Server is very particular about needing every little detail about a query to be exactly the same in order for it to reuse its cached plan. This includes things like white space and case sensitivity.
It is much less likely that a query inside of a stored procedure will change compared to a query that is embedded in code. Because of this, it's probably more likely that your stored procedure plans are being ran from cached plans while your individually submitted query texts may not be utilizing the cache. Because of this, the stored procedure may in fact be executing faster because it was able to reuse a cached plan. But this is not a fair comparison - if both plans would pull from the cache, or if both plans had to generate new execution plans, they would both have the same execution performance.
So does it matter if I use stored procedures or not?
So while in the majority of cases a standalone query will perform just as quickly as that same query embedded in a store procedure I still think it's better to use stored procedures when possible.
First, embedding your query inside of a stored procedure increases the likelihood that SQL Server will reuse that query's cached execution plan as explained above.
Secondly, using stored procedures is cleaner for organization, storing all of your database logic in one location: the database itself.
Finally, and most importantly, using stored procedures gives your DBA better insight into your queries. Storing a query inside of a stored procedure means your DBA can easily access and analyze it, offering suggestions and advice on how to fix it in case it is performing poorly. If your queries are all embedded in your apps instead, it makes it harder for the DBA to see those queries, reducing the likelihood that they will be able to help you fix your performance issues in a timely manner.