This post is the first in a series about physical join operators (be sure to check out part 2 - merge joins, and part 3 - hash match joins).
Watch this week's video on YouTube
What Physical Join Operators Tell Us
Everyone has their own method of reading an execution plan when performance tuning a slow SQL query. One of the first things I like to look at are what kind of join operators are being used:

These three little icons may not seem like the most obvious place to begin troubleshooting a slow query, but with larger plans especially I like starting with a quick glance at the join operators because they allow you to infer a lot about what SQL Server thinks about your data.
This will be a three part series where we'll learn how each join algorithm works and what they can reveal about our upstream execution plan operators.
Nested Loops Join
Nested loops joins work like this: SQL Server takes the first value from our first table (our "outer" table - by default SQL Server decides for us which table of the two this will be), and compares it to every value in our second "inner" table to see if they match.
Once every inner value has been checked, SQL Server moves to the next value in the outer table and the process repeats until every value from our outer table has been compared to every value in our inner table.
This description is a worst case example of the performance of a nested loop join. Several optimizations exist that can make the join more efficient. For example, if the inner table join values are sorted (because of an index you created or a spool that SQL Server created), SQL Server can process the rows much faster:
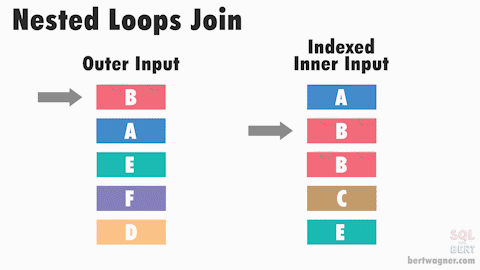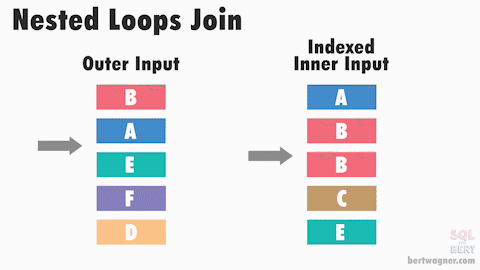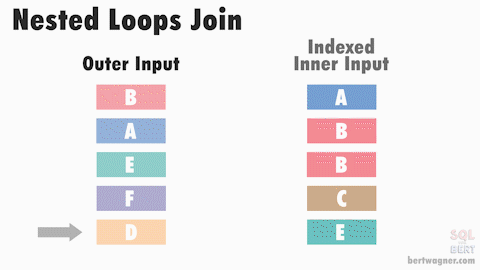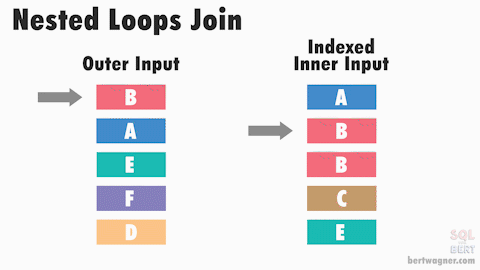
In the above animation, the inner input is a index sorted on the join key, allowing SQL Server to seek directly to the rows it needs, reducing the total number of comparisons that need to be made
For more in-depth explanations of the internals and optimizations of nested loops joins, I recommend reading this post by Craig Freedman as well as Hugo Kornelis's reference on nested loops.
What Do Nested Loops Joins Reveal?
Knowing the internals of how a nested loops join works allows us to infer what the optimizer thinks about our data and the join's upstream operators, helping us focus our performance tuning efforts.
Here are a few scenarios to consider the next time you see a nested loops join being used in your execution plan:
- Nested loops joins are CPU intensive; at worst, every row needs to be compared to every other row and this can take some time. This means when you see a nested loops join, SQL Server probably thinks that one of the two inputs is relatively small.
-
... and if one of the inputs is relatively small, great! If instead you see upstream operators that are moving large amounts of data, you may have a estimation problem going on in this area of the plan and may need to update stats/add indexes/refactor the query to have SQL Server provide better estimates (and maybe a more appropriate join).
-
Nested loops sometimes accompany RID or key lookups. I always check for one of these because they often leave room for some performance improvements:
- If a RID lookup exists, it's usually easy enough to add a clustered index to that underlying table to squeeze out some extra performance.
-
If either RID or key lookup exist, I always check what columns are being returned to see if a smaller index could be used instead (by including a column in a key/column of an existing index) or if the query can be refactored to not bring back those columns (eg. get rid of the SELECT *).
-
Nested loops joins do not require data to be sorted on input. However, performance can improve with an indexed inner data source (see animation above), and SQL Server might choose a more efficient operator if the inputs are both sorted.
- At the very least, nested loops joins make me think to check whether the input data isn't sorted because of some upstream transformations, or because of missing indexes.
So while nested loops in your plans will always require more investigation, looking at them and the operators around them can provide some good insight into what SQL Server thinks about your data.