Today I want to show you a trick that could make your queries run faster.
It won't always work, but when it does everyone will be impressed with your performance tuning prowess. Let's go!
Watch this week's video on YouTube
Our Skewed Data
Let's create a table and insert some data.
Notice the heavily skewed value distribution. Also notice how we have a clustered index and a very skimpy nonclustered index:
DROP DATABASE IF EXISTS ORUnionAll
CREATE DATABASE ORUnionAll
GO
CREATE TABLE ORUnionAll.dbo.TestData
(
Col1 int,
Col2 char(200),
Col3 int
)
GO
INSERT INTO ORUnionAll.dbo.TestData VALUES (1,'',1)
GO 10000
INSERT INTO ORUnionAll.dbo.TestData VALUES (2,'',2)
GO 50
INSERT INTO ORUnionAll.dbo.TestData VALUES (3,'',3)
GO 50
CREATE CLUSTERED INDEX CL_Col1 ON ORUnionAll.dbo.TestData ( Col1 )
GO
CREATE NONCLUSTERED INDEX IX_Col3 ON ORUnionAll.dbo.TestData (Col3)
GO
If we write a query that filters on one of the low-occurrence values in Col3, SQL Server will perform an index seek with a key lookup (since our skimpy nonclustered index doesn't cover all of the columns in our SELECT):
SELECT
Col2, Col3
FROM
ORUnionAll.dbo.TestData
WHERE
Col3 = 2

If we then add an OR to our WHERE clause and filter on another low-occurrence value in Col3, SQL Server changes how it wants to retrieve results:
SELECT
Col2, Col3
FROM
ORUnionAll.dbo.TestData
WHERE
Col3 = 2 OR Col3 = 3
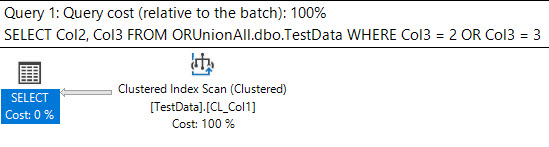
Suddenly those key-lookups become too expensive for SQL Server and the query optimizer thinks it'll be faster to just scan the entire clustered index.
In general this makes sense; SQL Server tries to pick plans that are good enough in most scenarios, and in general I think it chooses wisely.
However, sometimes SQL Server doesn't pick great plans. Sometimes the plans it picks are downright terrible.
If we encountered a similar scenario in the real-world where our tables had more columns, more rows, and larger datatypes, having SQL Server switch from a seek to a scan could kill performance.
So what can we do?
Solutions...maybe
The first thing that comes to mind is to modify or add some indexes.
But maybe our (real-world) table already has too many indexes. Or maybe we are working with a data source where we can't modify our indexes.
We could also use the FORCESEEK hint, but I don't like using hints as permanent solutions because they feel dirty (and are likely to do unexpected things as your data changes).
One solution to UNION ALL
One solution that a lot of people overlook is rewriting the query so that it uses UNION ALLs instead of ORs.
A lot of the time it's pretty easy to refactor the query to multiple SELECT statements with UNION ALLs while remaining logically the same and returning the same results:
SELECT
Col2, Col3
FROM
ORUnionAll.dbo.TestData
WHERE
Col3 = 2
UNION ALL
SELECT
Col2, Col3
FROM
ORUnionAll.dbo.TestData
WHERE
Col3 = 3
Sure, the query is uglier and will be a bigger pain to maintain if you need to make changes in the future, but sometimes we have to suffer for ~~fashion~~ query performance.
But does our UNION ALL query perform better?
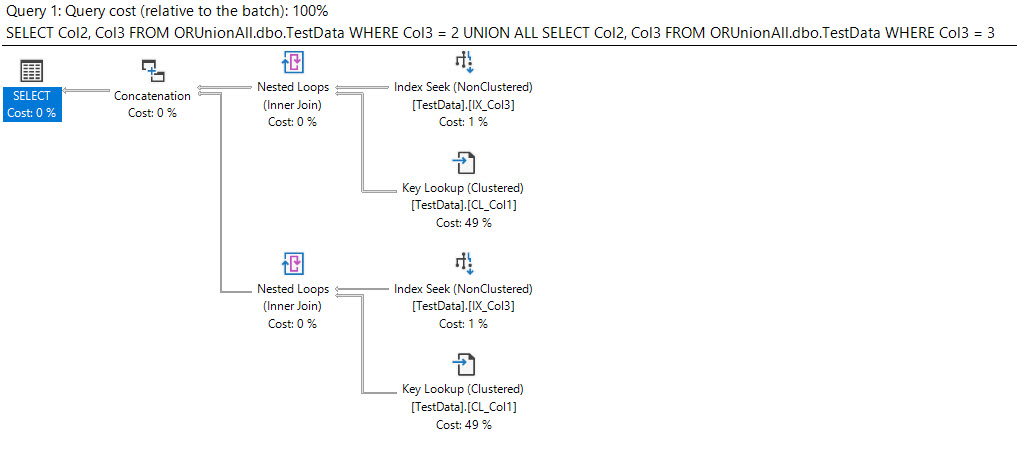
Well the plan shows seeks, but as Erik Darling recently pointed out, seeks aren't always a good thing.
So let's compare the reads of the OR query versus the UNION ALL query using SET STATISTICS IO ON:
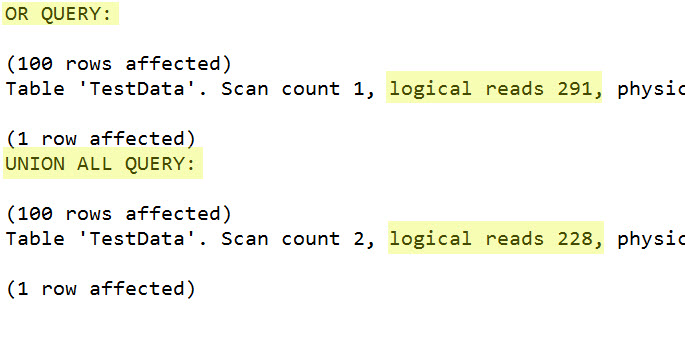
So in this case, tricking SQL Server to pick a a different plan by using UNION ALLs gave us a performance boost. The difference in reads isn't that large in the above scenario, but I've had this trick take my queries from minutes to seconds in the real world.
So the next time you are experiencing poor performance from a query with OR operators in it, try rewriting it using UNION ALLs.
It's not always going to fix your performance problem but you won't know until you give it a try.