Watch this week's video on YouTube
When you need to filter query results on multiple values, you probably use an IN() statement or multiple predicates separated by ORs:
WHERE Col1 IN ('A','B','C')
or
WHERE Col1 = 'A' OR Col1 = 'B' OR Col1 = 'C'
While SQL Server will generate the same query plan for either syntax, there is another technique you can try that can sometimes can improve performance under certain conditions: UNION ALL.
This post is a continuation of my series to document ways of refactoring queries for improved performance. I'll be using the StackOverflow 2014 data dump for these examples if you want to play along at home.
Lookups and Scans
Let's say we have the following index on our dbo.Badges table:
CREATE NONCLUSTERED INDEX [IX_Badges] ON [dbo].[Badges] ([Name]) INCLUDE ([UserId]);
Next let's run these two separate queries:
/* Query 1 */
SELECT
Name, UserId, Date
FROM
dbo.Badges
WHERE
Name = 'Benefactor'
OPTION(MAXDOP 1)
/* Query 2 */
SELECT
Name, UserId, Date
FROM
dbo.Badges
WHERE
Name = 'Research Assistant'
OPTION(MAXDOP 1)
Note I'm enforcing MAXDOP 1 here to remove any performance differences due to parallelism in these demos.
The nonclustered index doesn't cover these queries - while SQL Server can seek the index for the Name predicate in the WHERE clause, it can't retrieve all the columns in the SELECT from the index alone. This leaves SQL Server with a tough choice to make:
- Does it scan the whole clustered index to return all the required columns for the rows requested?
- Does it seek to the matching records in the nonclustered index and then perform a key lookup to retrieve the remaining data?
So, what does SQL Server decide to do?
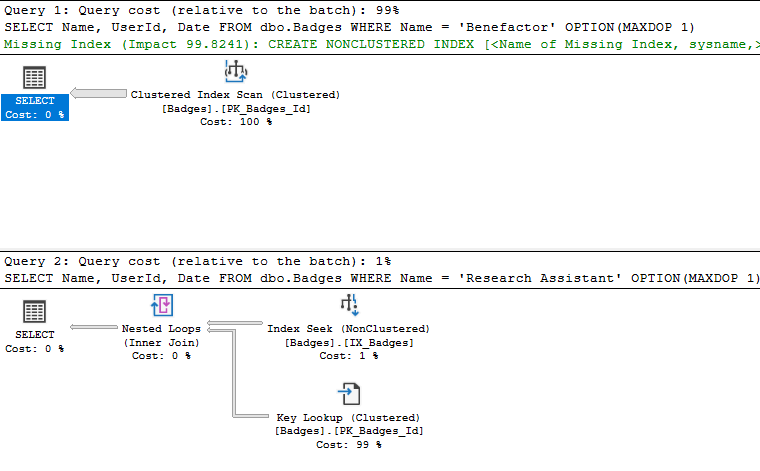
For Query 1, SQL Server thinks that reading the entire clustered index and returning only the rows where Name = 'Benefactor' is the best option.
SQL Server takes a different approach for Query 2 however, using the non-covering nonclustered indexes to find the records with Name = 'Research Assistant' and then going to look up the Date values in the clustered index via a Key Lookup
The reason SQL server chooses these two different plans is because it thinks it will be faster to return smaller number of records with a Seek + Key Lookup approach ("Research Assistant", 127 rows), but faster to return a larger number of records with a Scan ("Benefactor", 17935 rows).
Kimberly Tripp has an excellent post that defines where this "tipping point" from a key lookup to a clustered index scan typically occurs, but the important thing to keep in mind for this post is that we can sometimes use SQL Server's ability to switch between these two approaches to our advantage.
Combining Queries with IN
So, what plan does SQL Server generate when we combine our two queries into one?
SELECT
Name, UserId, Date
FROM
dbo.Badges
WHERE
Name IN ('Benefactor','Research Assistant')
OPTION(MAXDOP 1)
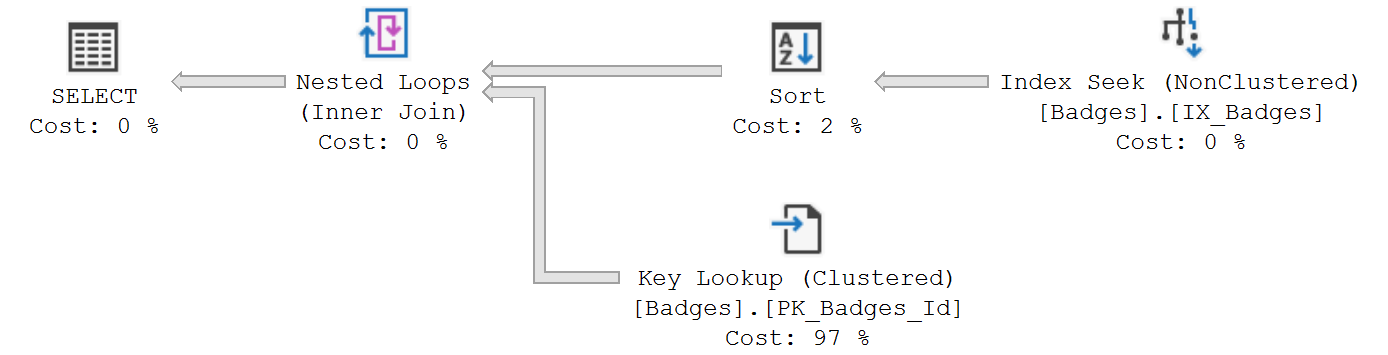
Interestingly enough SQL Server decides to retrieve the requested rows from the nonclustered index and then go lookup the remaining Date column in the clustered index.
If we look at the page reads (SET STATISTICS IO ON;) we'll see SQL Server had to read 85500 pages to return the data requested:
(18062 rows affected)
Table 'Badges'. Scan count 2, logical reads 85500, physical reads 20, read-ahead reads 33103, ...
Without correcting our index to include the Date column, is there some way we can achieve the same results with better performance?
UNION ALL
In this case it's possible to rewrite our query logic to use UNION ALL instead of IN/ORs:
SELECT
Name,UserId,Date
FROM
dbo.Badges
WHERE
Name = 'Benefactor'
UNION ALL
SELECT
Name,UserId,Date
FROM
dbo.Badges
WHERE
Name = 'Research Assistant'
OPTION(MAXDOP 1)
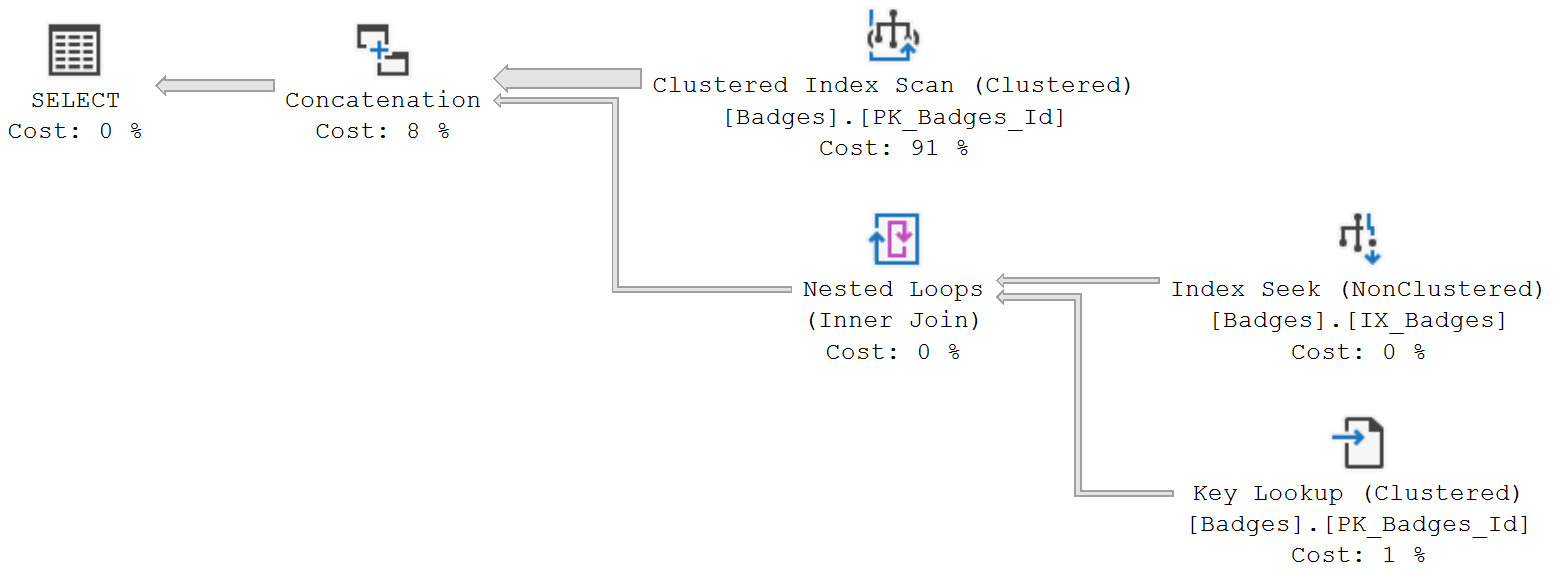
We get the same exact results through a hybrid execution plan.
In this case, our plan mirrors what SQL Server did when running our original two queries separately:
- The rows where
Name = 'Benefactor'are returned by scanning the clustered index. - The nonclustered index is seeked with clustered index lookups for the
Name = 'Research Assistant'records.
Looking at the IO statistics for this UNION ALL query:
(18062 rows affected)
Table 'Badges'. Scan count 2, logical reads 50120, physical reads 6, read-ahead reads 49649, ...
Even though this query reads the whole clustered index to get the Benefactor rows, the total number of logical reads is still smaller than the seek/key lookup pattern seen in the combined query with IN(). This UNION ALL version gives SQL Server the ability to build a hybrid execution plan, combining two different techniques to generate a plan with fewer overall reads.
IN or UNION ALL?
There's no way to know for sure without trying each variation.
But if you have a slow performing query that is filtering on multiple values within a column, it might be worth trying to get SQL Server to use a different plan by rewriting the query.