Watch this week's video on YouTube
The SQL Server FIRST_VALUE function makes it easy to return the "first value in an ordered set of values."
The problem is that if that first value happens to be a NULL, there is no easy, built-in way to skip it.
While a UserVoice item exists to add the ability to ignore nulls (go vote!), today, we're going accomplish that end result with some alternative queries.
The Setup
Here's the example data we'll be skipping nulls on:
CREATE TABLE ##Data
(
Id int IDENTITY(0,1),
GroupId int,
Value1 int
);
GO
INSERT INTO ##Data VALUES (1,1)
INSERT INTO ##Data VALUES (1,1)
INSERT INTO ##Data VALUES (1,3)
INSERT INTO ##Data VALUES (2,NULL)
INSERT INTO ##Data VALUES (2,NULL)
INSERT INTO ##Data VALUES (2,6)
INSERT INTO ##Data VALUES (2,4)
INSERT INTO ##Data VALUES (2,5);
GO
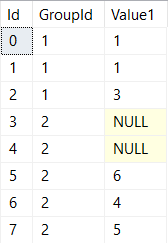
We've got a an integer identity column, two groups of rows, and NULLs that are sprinkled into otherwise unsuspecting integer values.
If we write a query that uses the FIRST_VALUE function, you'll notice that our NULL gets chosen in group two - not quite what we want:
SELECT
Id,
GroupId,
Value1,
FIRST_VALUE(Value1) OVER (PARTITION BY GroupId ORDER BY Id) AS FirstValue1
FROM
##Data
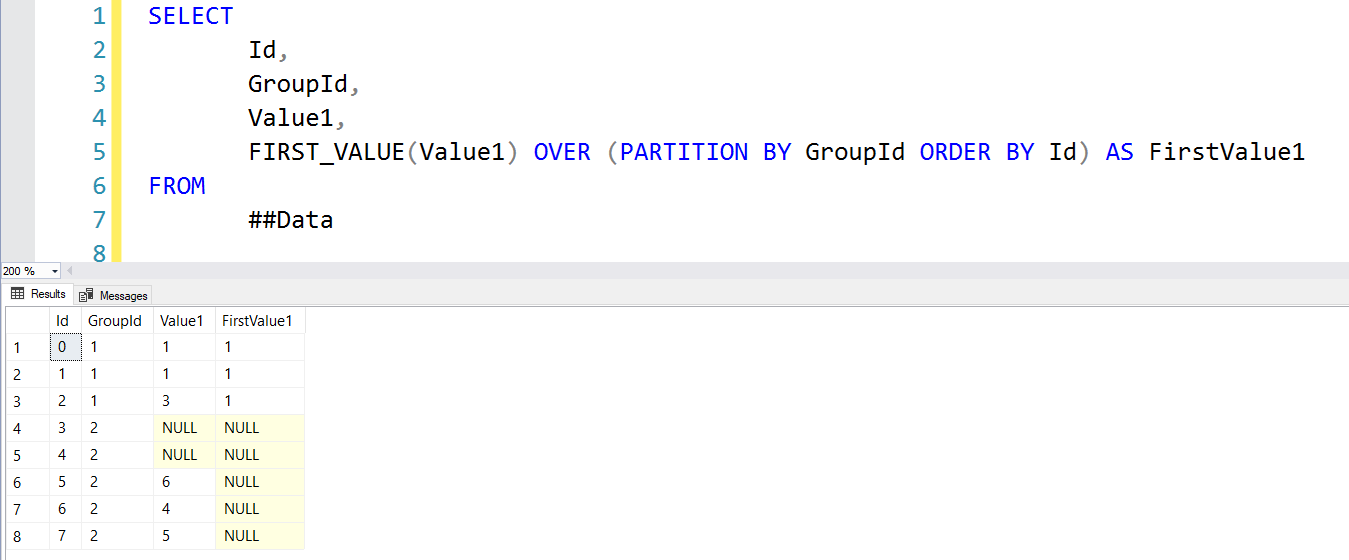
Let's look at two queries that will help us get the number 6 into that FirstValue1 column for the second group.
The Contenders
"The Derived FIRST_VALUE"
First up is still the FIRST_VALUE function, but inside of a derived table:
SELECT
d.Id,
d.GroupId,
d.Value1,
d2.FirstNotNullValue1
FROM
##Data d
INNER JOIN
(
SELECT DISTINCT
GroupId,
FIRST_VALUE(Value1) OVER (PARTITION BY GroupId ORDER BY Id) as FirstNotNullValue1
FROM ##Data
WHERE Value1 IS NOT NULL
) d2
ON d.GroupId = d2.GroupId
By filtering out NULLs in our derived table query, FIRST_VALUE returns the first non-null value like we want. We then join that back to the original data and all is right again.
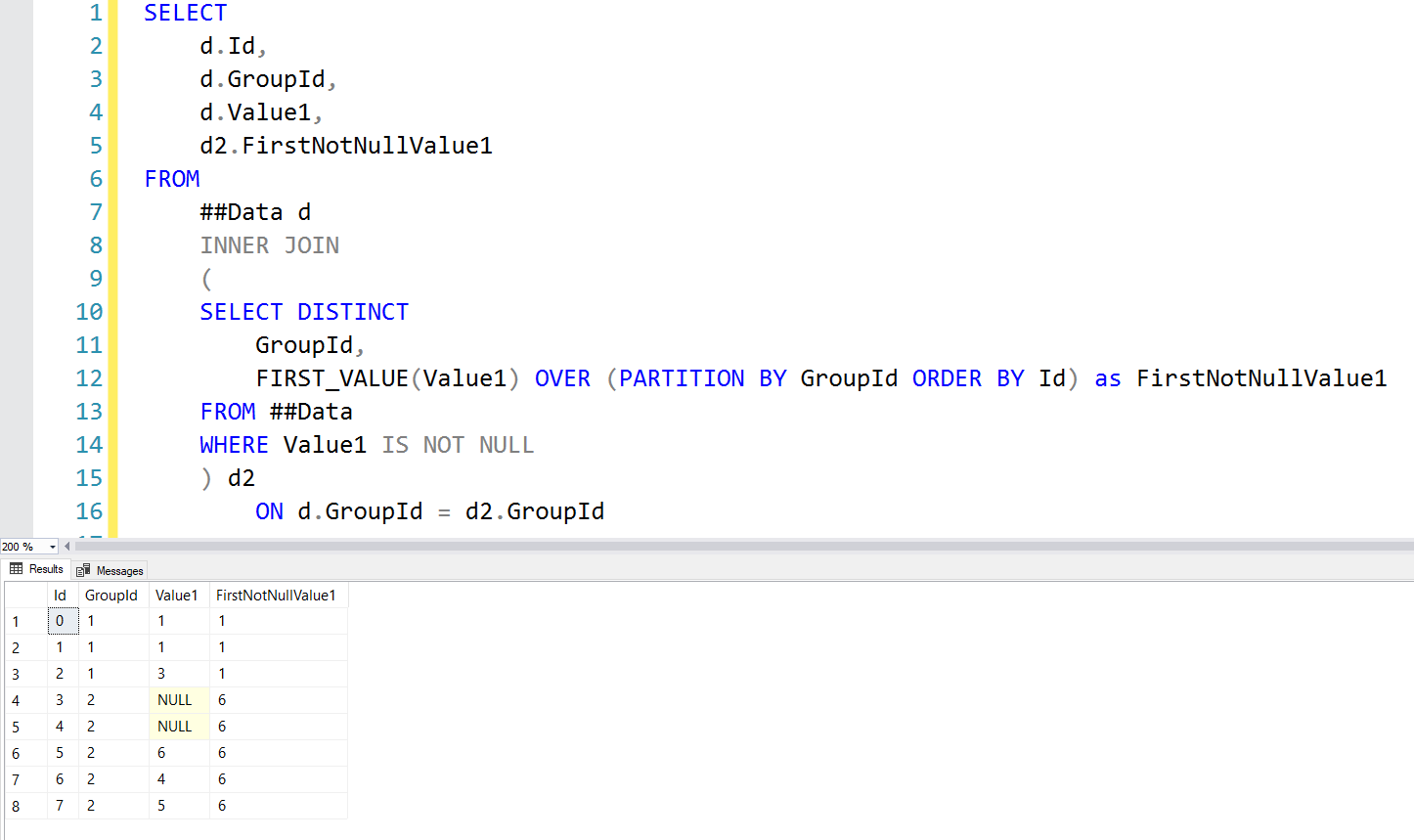
"The Triple Join"
Our second attempt at this query sends us back to the dark ages of SQL Server 2008 before the FIRST_VALUE function existed:
SELECT
d.Id,
d.GroupId,
d.Value1,
d2.Value1 AS FirstNotNullValue1
FROM
##Data d
LEFT JOIN
(
SELECT
GroupId,
MIN(Id) AS FirstNotNullIdValue1
FROM
##Data
WHERE
Value1 IS NOT NULL
GROUP BY
GroupId
) m
ON d.GroupId = m.GroupId
INNER JOIN ##Data d2
ON m.FirstNotNullIdValue1 = d2.Id;
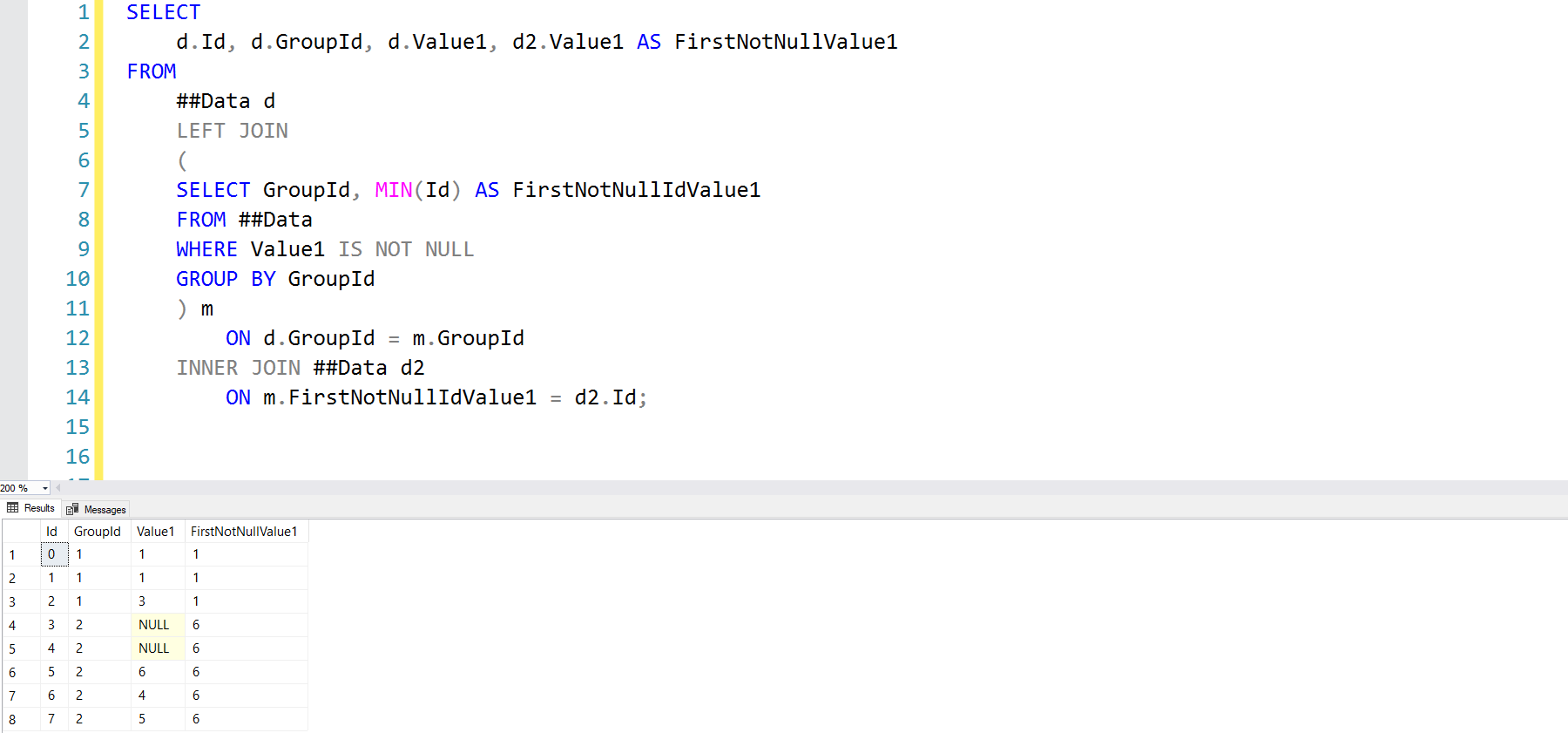
We perform a triple join, with the critical element being our derived table which gets the MIN Id for each group of rows where Value1 IS NOT NULL. Once we have the minimum Id for each group, we join back in the original data and produce the same final result:
The Performance
Both of the above queries produce the same output - which one should you use in your production code?
Well, the "Derived FIRST_VALUE" query has a lower relative cost than the "Triple Join" query, maybe it's better?
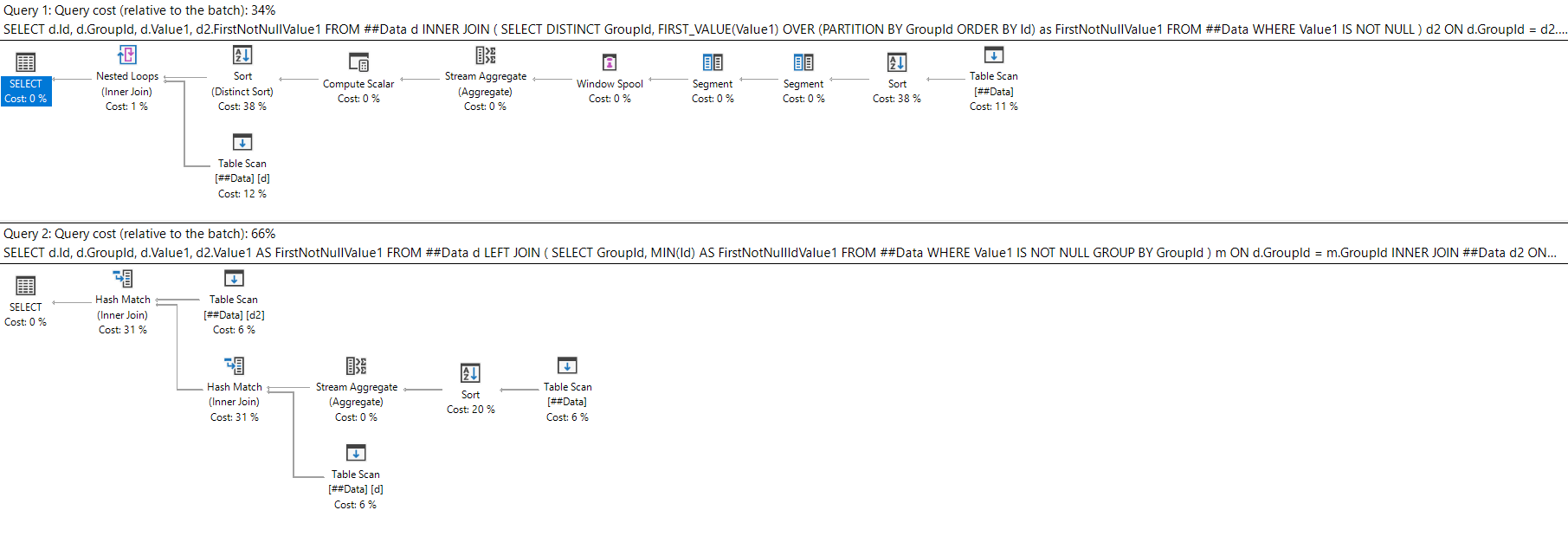
This isn't a real-world execution plan though - surely we never scan heaps our production environments.
Let's add a quick clustered index and see if that changes anything:
CREATE CLUSTERED INDEX CL_Id ON ##Data (GroupId,Id,Value1)

Okay, a closer match up but the "Derived FIRST_VALUE" query still appears to have a slight edge.
If we SET STATISTICS IO ON though we start to see a different story:

With only 8 rows of data, our "Derived FIRST_VALUE" query sure is performing a lot of reads.
What if we increase the size of our sample dataset?
SET STATISTICS IO, TIME OFF;
SET NOCOUNT ON;
GO
INSERT INTO ##Data (GroupId, Value1)
SELECT GroupId, Value1 FROM ##Data
GO 10
And now check our plans and stats IO:


WOW that's a lot of reads in the "Derived FIRST_VALUE" query.
Conclusion
Besides sharing some solutions, the point I tried to make above is that DON'T TRUST CODE YOU FIND ON THE INTERNET (or in books, or copied from colleagues, etc...)
Both of the above queries will return the first value without NULLs. But they probably won't perform exactly the same as they did on my examples above.
Copy the above code for sure - but test it out. See what works better on your specific server configuration, data size, and indexes. Maybe both queries are terrible and you need a third, better way of doing it (if you write one, let me know!) - but please, please, please, always test your code.