Watch this week's video on YouTube
Temporal Tables are awesome.
They make analyzing time-series data a cinch, and because they automatically track row-level history, rolling-back from an "oops" scenario doesn't mean you have to pull out the database backups.
The problem with temporal tables is that they produce a lot of data. Every row-level change stored in the temporal table's history table quickly adds up, increasing the possibility that a low-disk space warning is going to be sent to the DBA on-call.
In the future with SQL Server 2017 CTP3, Microsoft allows us to add a retention period to our temporal tables, making purging old data in a temporal table as easy as specifying:
ALTER DATABASE DatabaseName
SET TEMPORAL_HISTORY_RETENTION ON
CREATE TABLE dbo.TableName (
...
)
WITH
(
SYSTEM_VERSIONING = ON
(
HISTORY_TABLE = dbo.TableNameHistory,
HISTORY_RETENTION_PERIOD = 6 MONTHS
)
);
However, until we are all on 2017 in production, we have to manually automate the process with a few scripts.
Purging old data out of history tables in SQL Server 2016
In the next few steps we are going to write a script that deletes data more than a month old from my CarInventoryHistory table:
SELECT * FROM dbo.CarInventory;
SELECT * FROM dbo.CarInventoryHistory;
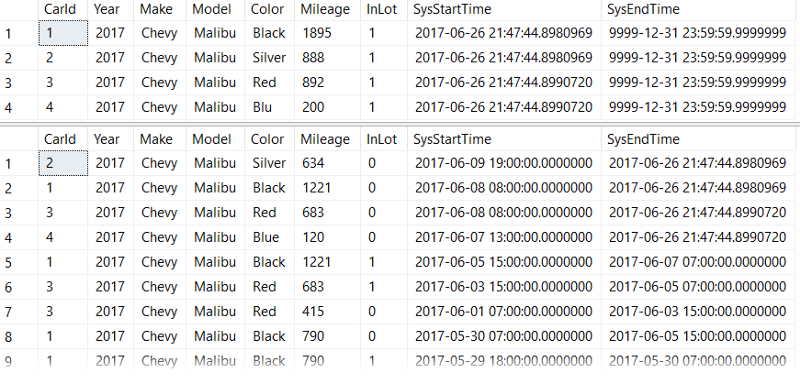
And now if we write our DELETE statement:
ALTER TABLE dbo.CarInventory SET ( SYSTEM_VERSIONING = OFF ) ;
GO
-- In the real-world we would do some DATE math here
DECLARE @OneMonthBack DATETIME2 = '2017-06-04';
DELETE FROM dbo.CarInventoryHistory WHERE SysStartTime < @OneMonthBack;
You'll notice that we first had to turn system versioning off: SQL Server won't let us delete data from a history table that is currently tracking a temporal table.
This is a poor solution however. Although the data will delete correctly from our history table, we open ourselves up to data integrity issues. If another process INSERTs/UPDATEs/DELETEs into our temporal table while the history deletion is occurring, those new INSERTs/UPDATEs/DELETEs won't be tracked because system versioning is turned off.
The better solution is to wrap our ALTER TABLE/DELETE logic in a transaction so any other queries running against our temporal table will have to wait:
-- Run this in query window #1 (delete data):
BEGIN TRANSACTION;
ALTER TABLE dbo.CarInventory SET ( SYSTEM_VERSIONING = OFF );
GO
-- In the real-world we would do some DATE math here
DECLARE @OneMonthBack DATETIME2 = '2017-06-04';
DELETE FROM dbo.CarInventoryHistory WITH (TABLOCKX)
WHERE SysStartTime < @OneMonthBack;
-- Let's wait for 10 seconds to mimic a longer delete operation
WAITFOR DELAY '00:00:10';
--Re-enable our SYSTEM_VERSIONING
ALTER TABLE dbo.CarInventory SET ( SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.CarInventoryHistory));
GO
COMMIT TRANSACTION;
-- Run this in query window #2 during the same time as the above query (trying to update during deletion):
UPDATE dbo.CarInventory SET InLot = 0 WHERE CarId = 4;
And the result? Our history table data was deleted while still tracking the row-level data changes to our temporal table:
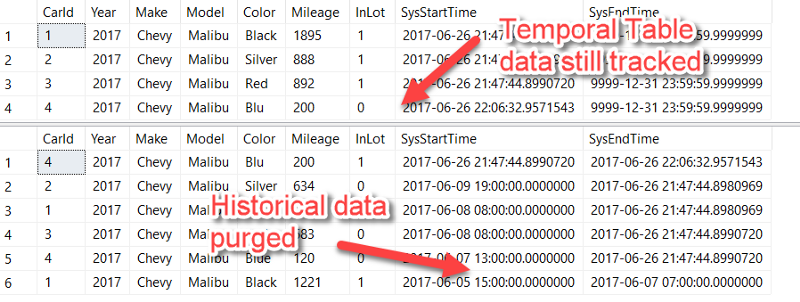
All that is left to do is to throw this script into a SQL Agent job and schedule how often you want it to run.