This post is part 2 in a series about physical join operators (be sure to check out part 1 - nested loops joins, and part 3 - hash match joins).
Watch this week's video on YouTube
Merge joins are theoretically the fastest* physical join operators available, however they require that data from both inputs is sorted:
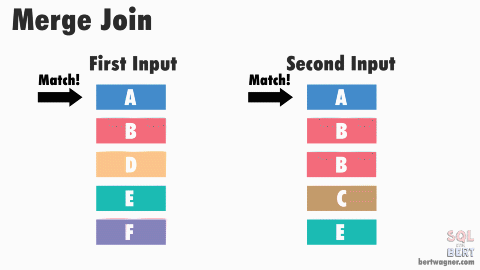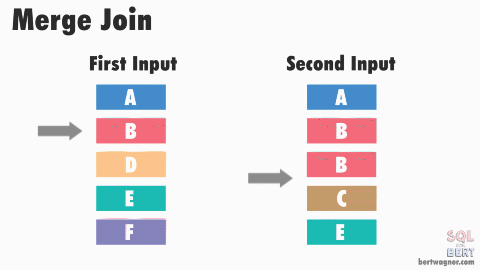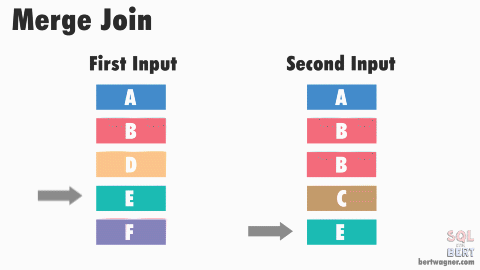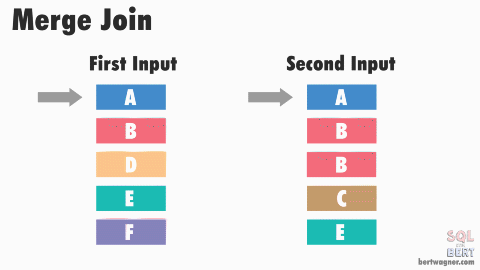
The base algorithm works as follows: SQL Server compares the first rows from both sorted inputs. It then continues comparing the next rows from the second input as long as the values match the first input's value.
Once the values no longer match, SQL Server increments the row of whichever input has the smaller value - it then continues performing comparisons and outputting any joined records. (For more detailed information, be sure to check out Craig Freedman's post on merge joins.)
This is efficient because in most instances SQL Server never has to go back and read any rows multiple times. The exception here happens when duplicate values exist in both input tables (or rather, SQL Server doesn't have meta data available proving that duplicates don't exist in both tables) and SQL Server has to perform a many-to-many merge join:
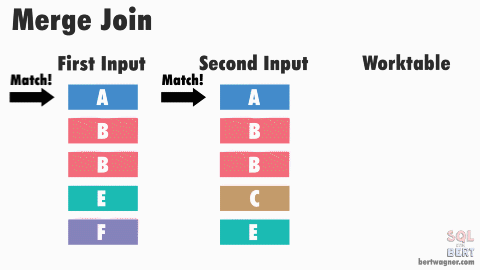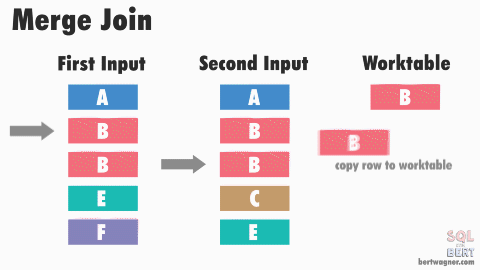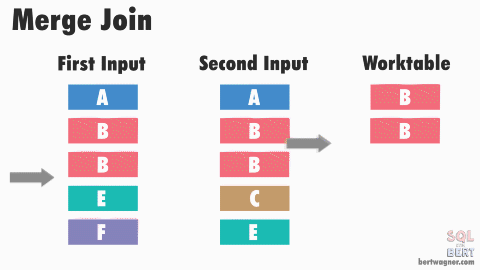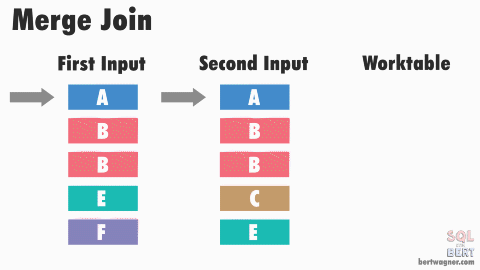
Note: The image above and the explanation below are "good enough" for understanding this process for practical purposes - if you want to dive into the peek-ahead buffers, optimizations, and other inner workings of this process, I highly recommend reading through Hugo Kornelis's reference on merge joins.
A many-to-many join forces SQL Server to write any duplicated values in the second table into a worktable in tempdb and do the comparisons there. If those duplicated values are also duplicated in the first table, SQL Server then compares the first table's values to those already stored in the worktable.
What Do Merge Joins Reveal?
Knowing the internals of how a merge join works allows us to infer what the optimizer thinks about our data and the join's upstream operators, helping us focus our performance tuning efforts.
Here are a few scenarios to consider the next time you see a merge join being used in your execution plan:
-
The optimizer chooses to use a merge join when the input data is already sorted or SQL Server can sort the data for a low enough cost. Additionally, the optimizer is fairly pessimistic at calculating the costs of merge joins (great explanation by Joe Obbish), so if a merge join makes its way into your plans, it probably means that it is fairly efficient.
-
While a merge join may be efficient, it's always worth looking at why the data coming in to the merge join operator is already sorted:
- If it's sorted because the merge join is pulling data directly from an index sorted on your join keys, then there is not much to be concerned about.
- If the optimizer added a sort to the upstream merge join though, it may be worth investigating whether it's possible to presort that data so SQL Server doesn't need to sort it on its own. Often times this can be as simple as redefining an included index column to a key column - if you are adding it as the last key column in the index then regression impact is usually minor but you may be able to allow SQL Server to use the merge join without any additional sorting required.
-
If your inputs contain many duplicates, it may be worth checking if a merge join is really the most efficient operator for the join. As outlined above, many-to-many merge joins require tempdb usage which could become a bottle neck!
So while merge joins are typically not the high-cost problem spots in your execution plans, it's always worth investigating upstream operators to see if some additional improvements can be made.
[]{#fastest-exception}
*NOTE: There are always exceptions to the rule. Merge joins have the fastest algorithm since each row only needs to be read once from the source inputs. Also, optimizations occurring in other join operators can give those operators better performance under certain conditions.
For example, a single row outer table with an indexed inner table using a nested loops join will outperform the same setup with a merge join because of the inner loops joins' optimizations:
DROP TABLE IF EXISTS T1;
GO
CREATE TABLE T1 (Id int identity PRIMARY KEY, Col1 CHAR(1000));
GO
INSERT INTO T1 VALUES('');
GO
DROP TABLE IF EXISTS T2;
GO
CREATE TABLE T2 (Id int identity PRIMARY KEY, Col1 CHAR(1000));
GO
INSERT INTO T2 VALUES('');
GO 100
-- Turn on execution plans and check actual rows for T2
SELECT *
FROM T1 INNER LOOP JOIN T2 ON T1.Id = T2.Id;
SELECT *
FROM T1 INNER MERGE JOIN T2 ON T1.Id = T2.Id;
*There might also be instances where inputs with many duplicate records that require worktables may be slower than a nested loop join. *
As I mentioned though, I typically find these types of scenarios to be the exceptions when encountering merge joins in the real-world.