Watch this week's video on YouTube
It's 4:30 pm on Friday and Mr. Manager comes along to tell you that he needs you to run some important ad-hoc analysis for him.
Previously this meant having to stay late at the office, writing cumbersome queries to extract business information from transactional data.
Lucky for you, you've recently started using Temporal Tables in SQL Server ensuring that you'll be able to answer your boss's questions and still make it to happy hour for \$3 margaritas.
Sound like a plan? Keep reading below!
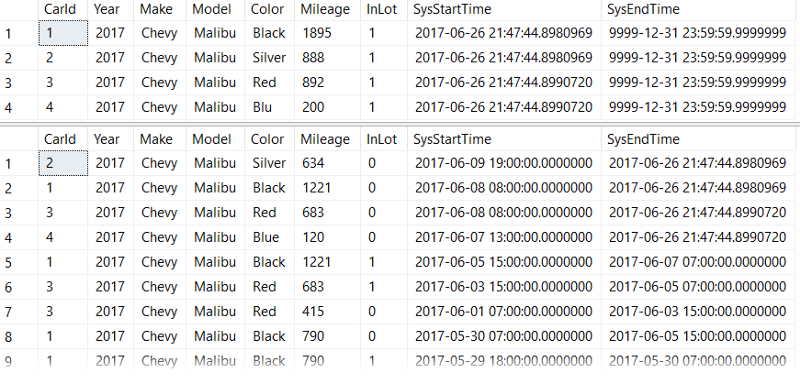
The Data
For these demos, we'll be using my imaginary car rental business data. It consists of our temporal table dbo.CarInventory and our history table dbo.CarInventoryHistory:
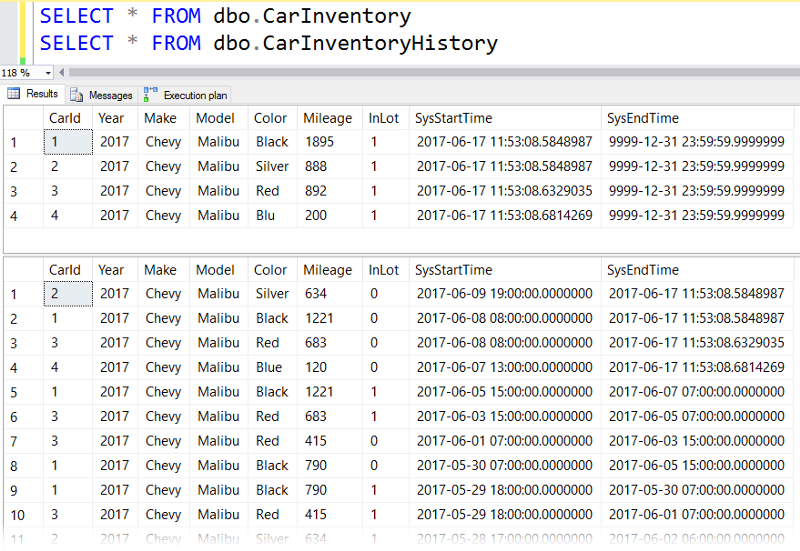
Business Problem #1 — "Get me current inventory!"
To get our current inventory of rental cars, all we have to do is query the temporal table:
SELECT * FROM dbo.CarInventory
That's it.
I know this query seems lame — it's just a SELECT FROM statement. There are no FOR SYSTEM TIME clauses, WHERE statements, and no other interesting T-SQL features.
But that's the point! Have you ever had to get the "current" rows out of a table that is keeping track of all transactions? I'm sure it involved some GROUP BY statements, some window functions, and more than a few cups of coffee.
Temporal tables automatically manage your transaction history, providing the most current records in one table (dbo.CarInventory) and all of the historical transactions in another (dbo.CarInventoryHistory). No need for complicated queries.
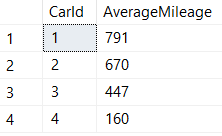
Business Problem #2 — "How many miles on average do our customers drive each of our cars?"
In this example, we use FOR SYSTEM_TIME ALL and a plain old GROUP BY to get the data we need:
SELECT
CarId, AVG(Mileage) AS AverageMileage
FROM
dbo.CarInventory FOR SYSTEM_TIME ALL
WHERE
InLot = 1 -- The car has been successfully returned to our lot
AND SysStartTime > '2017-05-13 08:00:00.0000000' -- Ignore our initial car purchase
GROUP BY
CarId
FOR SYSTEM_TIME ALL returns all rows from both the temporal and history table. It's equivalent to:
SELECT * FROM dbo.CarInventory
UNION ALL
SELECT * FROM dbo.CarInventoryHistory
Once again, there isn't anything too fancy going on here — but that's the point. With temporal tables, your data is organized to make analysis easier.
Business Problem #3 — "How many cars do we rent out week over week?"
Here at Wagner Car Rentals we want to figure out how often our cars are being rented and see how those numbers change from week to week.
SELECT
CurrentWeek.CarId,
CurrentWeek.RentalCount AS CurrentRentalCount,
PreviousWeek.RentalCount AS PreviousRentalCount
FROM
(
SELECT
CarId,
COUNT(*) AS RentalCount
FROM
dbo.CarInventory FOR SYSTEM_TIME FROM '2017-06-05' TO '2017-06-12'
WHERE
InLot = 0 -- Car is out with the customer
GROUP BY
CarId
) CurrentWeek
FULL JOIN
(
SELECT
CarId,
COUNT(*) AS RentalCount
FROM
dbo.CarInventory FOR SYSTEM_TIME FROM '2017-05-29' TO '2017-06-05'
WHERE
InLot = 0 -- Car is out with the customer
GROUP BY
CarId
) PreviousWeek
ON CurrentWeek.CarId = PreviousWeek.CarId
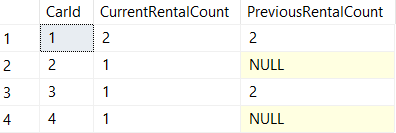
In this query, we are using FOR SYSTEM_TIME FOR/TO on our temporal table to specify what data we want in our "CurrentWeek" and "PreviousWeek" subqueries.
FOR/TOreturns any records that were active during the specified range(BETWEEN/AND does the same thing, but its upper bound datetime2 value is inclusive instead of exclusive).
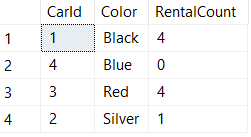
Business Problem #4 — "What color cars are rented most often?"
We're thinking of expanding our fleet of rental vehicles and want to purchase cars in the most popular colors so we can keep customers happy (and get more of their business!). How can we tell which color cars get rented most often?
SELECT
CarId,
Color,
COUNT(*)/2 AS RentalCount -- Divide by 2 because transactions are double counted (rental and return dates)
FROM
dbo.CarInventory FOR SYSTEM_TIME CONTAINED IN ('2017-05-15','2017-06-15')
GROUP BY
CarId,
Color
Here we use CONTAINED IN because we want to get precise counts of how many cars were rented and returned in a specific date range (if a car wasn't returned — stolen, wrecked and totaled, etc… — we don't want to purchase more of those colors in the future).
Business Problem #5 — "Jerry broke it. FIX IT!"
The computer systems that we use at Wagner Car Rentals are a little…dated.
Instead of scanning a bar code to return a car back into our system, our employees need to manually type in the car details. The problem here is that some employees (like Jerry) can't type, and often makes typos:
SELECT * FROM dbo.CarInventory FOR SYSTEM_TIME ALL WHERE CarId = 4

Having inconsistent data makes our reporting much more difficult, but fortunately since we have our temporal table tracking row-level history, we can easily correct Jerry's typos by pulling the correct values from a previous record:
;WITH InventoryHistory
AS
(
SELECT ROW_NUMBER () OVER (PARTITION BY CarId ORDER BY SysStartTime DESC) AS RN, *
FROM dbo.CarInventory FOR SYSTEM_TIME ALL WHERE CarId = 4
)
--SELECT * FROM InventoryHistory
/*Update current row by using N-th row version from history (default is 1 - i.e. last version)*/
UPDATE dbo.CarInventory
SET Color = h.Color
FROM
dbo.CarInventory i
INNER JOIN InventoryHistory h
ON i.CarId = h.CarId
AND RN = 2

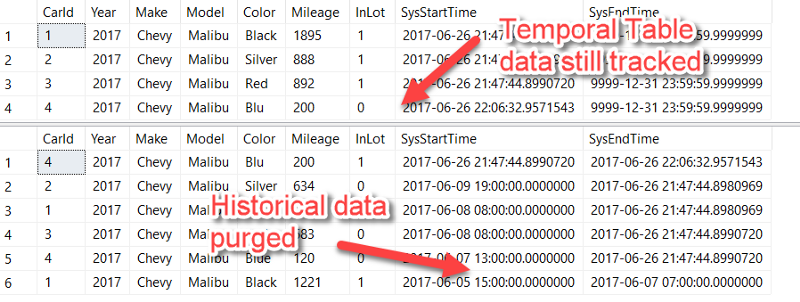
Although we could have fixed this issue without using a temporal table, it shows how having all of the row-level transaction history makes it possible to repair incorrect data in more difficult scenarios. For even hairier situations, you can even roll-back your temporal table data.
Conclusion
Temporal tables are easy to setup and make writing analytical queries a cinch.
Hopefully writing queries against temporal tables will prevent you from having to stay late in the office the next time your manager asks you to run some ad-hoc analysis.