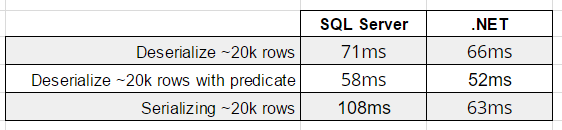
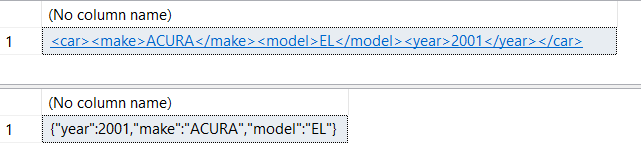
Watch this week's video on YouTube
So you've started using temporal tables because they make your point-in-time analysis queries super easy.
Your manager is happy because you're getting historical data to him quickly. Your DBA is happy because she doesn't have to clean up any performance killing triggers that replicate a temporal table's functionality. Everything with temporal tables has made your life better.
Except that time when you accidentally inserted some bad data into your temporal table.
Whoops
The good news is that all of your data is still intact — it's been copied over to the historical table. Phew!
Now all you need to do is rollback this inadvertent row insertion and make your tables look just like you did before you started breaking them.
This should be easy right?
Well not exactly — there's no automatic way to roll back the data in a temporal table. However, that doesn't mean we can't write some clever queries to accomplish the same thing.
Let's make some data
Don't mind the details of this next query too much. It uses some non-standard techniques to fake the data into a temporal/historical table with "realistic" timestamps:
IF OBJECT_ID('dbo.CarInventory', 'U') IS NOT NULL
BEGIN
-- When deleting a temporal table, we need to first turn versioning off
ALTER TABLE dbo.CarInventory SET ( SYSTEM_VERSIONING = OFF )
DROP TABLE dbo.CarInventory
DROP TABLE dbo.CarInventoryHistory
END;
CREATE TABLE CarInventory
(
CarId INT IDENTITY PRIMARY KEY NOT NULL,
Year INT,
Make VARCHAR(40),
Model VARCHAR(40),
Color varchar(10),
Mileage INT,
InLot BIT NOT NULL DEFAULT 1
);
CREATE TABLE CarInventoryHistory
(
CarId INT NOT NULL,
Year INT,
Make VARCHAR(40),
Model VARCHAR(40),
Color varchar(10),
Mileage INT,
InLot BIT NOT NULL,
SysStartTime datetime2 NOT NULL,
SysEndTime datetime2 NOT NULL
);
INSERT INTO dbo.CarInventoryHistory (CarId,Year,Make,Model,Color,Mileage,InLot,SysStartTime,SysEndTime) VALUES(1,2017,'Chevy','Malibu','Black',0,1,'2017-05-13 8:00:00.0000000','2017-05-14 8:00:00.0000000');
INSERT INTO dbo.CarInventoryHistory (CarId,Year,Make,Model,Color,Mileage,InLot,SysStartTime,SysEndTime) VALUES(2,2017,'Chevy','Malibu','Silver',0,1,'2017-05-13 8:00:00.0000000','2017-05-14 9:00:00.0000000');
INSERT INTO dbo.CarInventoryHistory (CarId,Year,Make,Model,Color,Mileage,InLot,SysStartTime,SysEndTime) VALUES(1,2017,'Chevy','Malibu','Black',0,0,'2017-05-14 8:00:00.0000000','2017-05-15 7:00:00.0000000');
INSERT INTO dbo.CarInventoryHistory (CarId,Year,Make,Model,Color,Mileage,InLot,SysStartTime,SysEndTime) VALUES(2,2017,'Chevy','Malibu','Silver',0,0,'2017-05-14 9:00:00.0000000','2017-05-19 15:00:00.0000000');
INSERT INTO dbo.CarInventoryHistory (CarId,Year,Make,Model,Color,Mileage,InLot,SysStartTime,SysEndTime) VALUES(1,2017,'Chevy','Malibu','Black',73,1,'2017-05-15 7:00:00.0000000','2017-05-16 10:00:00.0000000');
INSERT INTO dbo.CarInventoryHistory (CarId,Year,Make,Model,Color,Mileage,InLot,SysStartTime,SysEndTime) VALUES(2,2017,'Chevy','Malibu','Silver',488,1,'2017-05-19 15:00:00.0000000','2017-05-20 08:00:00.0000000');
ALTER TABLE dbo.CarInventory
ADD SysStartTime DATETIME2 GENERATED ALWAYS AS ROW START NOT NULL
CONSTRAINT DF_SysStart DEFAULT SYSUTCDATETIME(),
SysEndTime DATETIME2 GENERATED ALWAYS AS ROW END NOT NULL
CONSTRAINT DF_SysEnd DEFAULT '9999-12-31 23:59:59.9999999',
PERIOD FOR SYSTEM_TIME (SysStartTime, SysEndTime);
SET IDENTITY_INSERT dbo.CarInventory ON;
INSERT INTO dbo.CarInventory (CarId,Year,Make,Model,Color,Mileage,InLot) VALUES(1,2017,'Chevy','Malibu','Black',120,1);
INSERT INTO dbo.CarInventory (CarId,Year,Make,Model,Color,Mileage,InLot) VALUES(2,2017,'Chevy','Malibu','Silver',591,1);
SET IDENTITY_INSERT dbo.CarInventory OFF;
-- We need to make sure that the last SysEndTimes in our historical table match the SysStartTimes in our temporal table
DECLARE @LastSysStartTimeInTemporalCar1 DATETIME2, @LastSysStartTimeInTemporalCar2 DATETIME2
SELECT @LastSysStartTimeInTemporalCar1 = SysStartTime FROM dbo.CarInventory WHERE CarId = 1
SELECT @LastSysStartTimeInTemporalCar2 = SysStartTime FROM dbo.CarInventory WHERE CarId = 2
INSERT INTO dbo.CarInventoryHistory (CarId,Year,Make,Model,Color,Mileage,InLot,SysStartTime,SysEndTime) VALUES(1,2017,'Chevy','Malibu','Black',73,0,'2017-05-16 10:00:00.0000000',@LastSysStartTimeInTemporalCar1);
INSERT INTO dbo.CarInventoryHistory (CarId,Year,Make,Model,Color,Mileage,InLot,SysStartTime,SysEndTime) VALUES(2,2017,'Chevy','Malibu','Silver',488,0,'2017-05-20 08:00:00.0000000',@LastSysStartTimeInTemporalCar2);
ALTER TABLE dbo.CarInventory SET ( SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.CarInventoryHistory));
-- If everything worked well, we should see our data correctly in these table
SELECT * FROM dbo.CarInventory
SELECT * FROM dbo.CarInventoryHistory
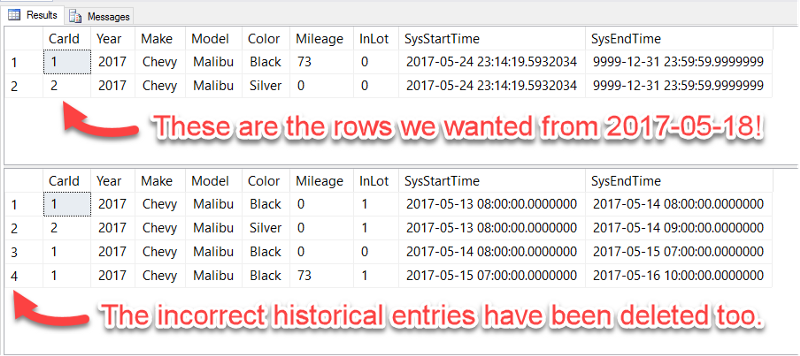
If you look at the results of our temporal table (top) and historical table (bottom), they should look something like this:
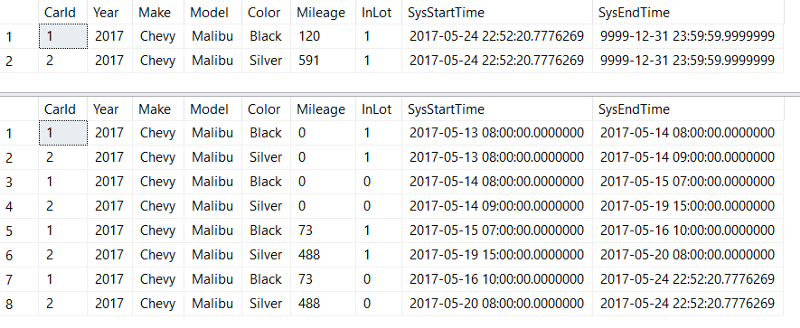
You see those two rows in the top temporal table? Those are the ones I just added accidentally. I actually had a bug in my code *ahem* and all of the data inserted after 2017–05–18 is erroneous.
The bug has been fixed, but we want to clean up the incorrect entries and roll back the data in our temporal tables to how it looked on 2017–05–18. Basically, we want the following two rows to appear in our "current" temporal table and the historical table to be cleaned up of any rows inserted after 2017–05–18:
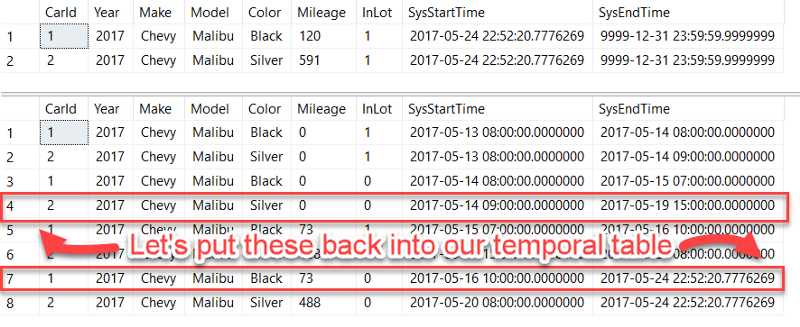
Fortunately, we can query our temporal table using FOR SYSTEM_TIME AS OF to get the two rows highlighted above pretty easily. Let's do that and insert into a temp table called ##Rollback:
DROP TABLE IF EXISTS ##Rollback
SELECT
*
INTO ##Rollback
FROM
dbo.CarInventory
FOR SYSTEM_TIME AS OF '2017-05-18'
-- Update the SysEndTime to the max value because that's what it's always set to in the temporal table
UPDATE ##Rollback SET SysEndTime = '9999-12-31 23:59:59.9999999'
You'll notice we also updated the SysEndTime — that's because a temporal table always has its AS ROW END column set to the max datetime value.
Looking at ##Rollback, we have the data we want to insert into our temporal table:

Now, it'd be nice if we could just insert the data from #Rollback straight into our temporal table, but that would get tracked by the temporal table!
So instead, we need to turn off system versioning, allow identity inserts, delete our existing data, and insert from ##Rollback. Basically:
ALTER TABLE dbo.CarInventory SET ( SYSTEM_VERSIONING = OFF);
SET IDENTITY_INSERT dbo.CarInventory ON;
DELETE FROM dbo.CarInventory WHERE CarId IN (SELECT DISTINCT CarId FROM ##Rollback)
INSERT INTO dbo.CarInventory (CarId,Year,Make,Model,Mileage,Color,InLot)
SELECT CarId,Year,Make,Model,Mileage,Color,InLot
FROM ##Rollback
While system versioning is off, we can also clean up the historical table by deleting all records after 2017–05–18 by joining the ##Rollback temp table on SysStartTime:
DELETE h
FROM ##Rollback t
INNER JOIN dbo.CarInventoryHistory h
ON
h.CarId = t.CarId
AND t.SysStartTime <= h.SysStartTime
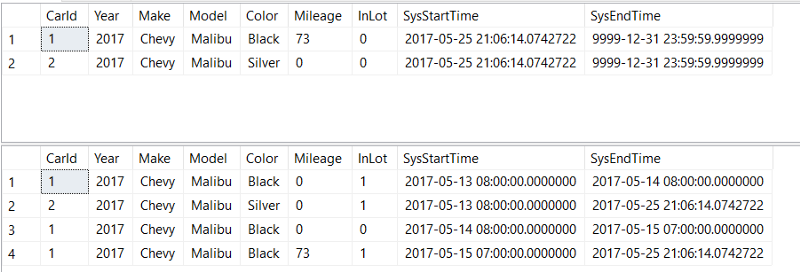
We have rolled back our data successfully!
Only One Tiny Problem
Did you notice that the last SysEndTime values in our historical table don't match up with the SysStartTime values in our temporal table?
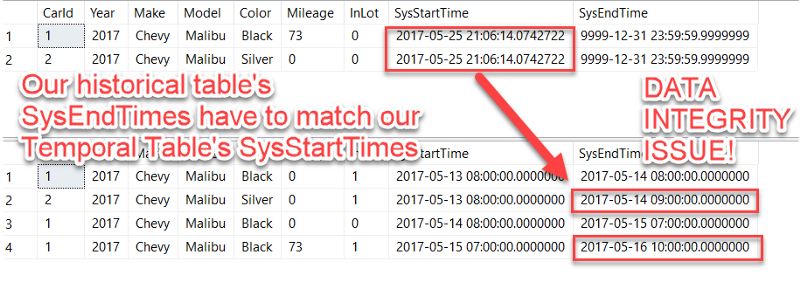
This is a data integrity issue for our temporal table — our datetimes should always be continuous.
Fortunately this is easily fixed with one more UPDATE statement:
UPDATE t
SET t.SysEndTime = i.SysStartTime
FROM dbo.CarInventoryHistory t
INNER JOIN ##Rollback r
ON t.CarId = r.CarId
AND t.SysEndTime = r.SysStartTime
INNER JOIN dbo.CarInventory i
ON t.CarId = i.CarId
AND r.CarId = i.CarId
SELECT * FROM dbo.CarInventory
SELECT * FROM dbo.CarInventoryHistory
Finally, remember to turn system versioning back on and to turn off our identity inserts to restore the original functionality of our temporal tables:
ALTER TABLE dbo.CarInventory SET ( SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.CarInventoryHistory));
SET IDENTITY_INSERT dbo.CarInventory OFF;
Congratulations, you've rolled back your temporal table data!