Spaghetti Sauce Origins
During the 1970s consumers had a limited number of spaghetti sauces that they could purchase at their local supermarket. Each store-bought sauce tasted the same, developed in test kitchens from the average flavor preferences of focus groups.
During this time, Prego brand spaghetti sauce was new to the market and was having a difficult time competing against the more established spaghetti sauce brands like Ragu. Prego tasted the same as all of the other brands so capturing loyal customers from other brands was a challenge.
Struggling to become competitive, Prego brought on board Howard Moskowitz. Today some consider Moskowitz the godfather of food-testing and market research, but during the 1970s Moskowitz's beliefs on product-design were contrary to the mainstream establishment. Moskowitz believed that using the average preferences of focus groups to develop a product lead to an average tasting spaghetti sauce: acceptable by most, loved by none.
Instead of giving focus groups similar tasting sauces, Moskowitz decided to test the extremes: have groups compare smooth pureed sauces with sauces that have chunks of vegetables in them, compare mild tasting sauces with ones with lots of spice, and so forth.
The results of this type of testing may seem obvious today, but at the time they were unheard of: people prefer different kinds of spaghetti sauce. It was better for a food company to have a portfolio of niche flavors rather than try to make one product that appealed to everybody.

After all of this initial research Prego made Extra-Chunky spaghetti sauce, which instantly became a hit with all of the people who prefer a thicker type of tomato sauce. In the years since, spaghetti sauce manufactures have caught on to the technique and supermarket shelves today are lined with regular, thick and chunky, three-cheese, garlic, and many other types of sauces that appeal to a wide-array of consumer flavor preferences.
Coffee's Variety Problem
Coffee today has the same problem that spaghetti sauce did a quarter-century ago.
The average supermarket's coffee aisle may look like it has a wide variety of choices: whole beans versus ground coffee versus coffee pods, arabica versus robusta beans, caffeinated versus decaf, medium versus dark roast, etc…
However, once you take a look at what coffee a particular individual may drink — let's say whole bean, medium-roast caffeinated arabica beans -the amount of variety found at a super market is surprisingly small, maybe only 2 or 3 different types.

Additionally, it is nearly impossible to know how long the coffee has been sitting unsold on the shelves, it's difficult to find a variety of coffee from different geographic regions around the world, and only if you are extremely lucky can you find a coffee that has been lightly roasted.
Independent coffee shops, especially those that roast their own coffee, offer slightly better options in terms of variety, however they come at a steep price: it is not unusual to see these coffees selling for \$16-\$28 per pound.
I understand these small-batch roasters experience higher costs due to lack of scale, availability of beans, and a slowly developing market to third-wave premium coffee, however paying \$20 for a pound of coffee beans (or even worse, the standard 12oz bag) is not something I can justify doing regularly.
This is what caused me to set out on my quest to get premium quality coffee beans at an affordable price.
The Internet Cafe
While the internet offers advantages in buying premium roasted coffee beans, there are still issues with unknown freshness and high prices, especially when the cost of shipping is included.
Shipping costs and price per pound can be reduced when buying in bulk, but buying in bulk means I'll have roasted beans sitting around for a long time before being consumed, therefore affecting freshness and taste. Short of finding friends who want to split a large coffee order, buying roasted coffee beans online isn't a great option.
What is a great option is buying green, or un-roasted, coffee beans. The shelf life of green beans is up to one year if stored properly and green beans are significantly cheaper than roasted beans because there is less processing involved.

Not only are green beans fresher and cheaper, there is significantly more variety available. Commercial roasters need to buy beans in large quantities in order to be able to sell to coffee shops and supermarkets. This means they are sourcing coffee beans from large commercial farms that are able to supply such a large amount of coffee beans.
If we buy green beans for personal consumption at home, the number of farms that we can buy from is hugely expanded since we only need to buy in small quantities. A farm that only produces a few hundred pounds of beans each year is now within our grasp since commercial roasters would never be able to purchase from them.
There are many retailers online that cater to the home roasting market. My favorite is http://sweetmarias.com and they always have a huge selection of premium beans from all over the world, many for under \$6/pound.
Home Roasting
Roasting beans at home used to be the norm in the early nineteenth century. Roasting coffee beans is similar to making popcorn and can be done over a fire, in a stove, or in the oven. While these methods work, they are messy and involved. Fortunately, cleaner and more scientific options exist.
Commercially available home roasters are one such option, however they cost several hundred to thousands of dollars — well out of my price range.
The most easily obtainable and easy to use home coffee roaster is an electric air-powered popcorn popper. These retail for between \$15–\$25 new. If you decide to try this route, get one without a mesh screen on the bottom.
Once you have an air popcorn popper, roasting coffee beans is as easy as pouring them in, turning on the heat, and waiting until they turn the brown color you are accustomed to seeing.
Although roasting beans can be as easy as turning on the popcorn popper and waiting until the beans reach a desired color, there is a scientific rabbit hole that roasting geeks like me eventually wander down…
Home Roasting 2.0: Web Roast
When I first started roasting coffee beans at home, I started with the air popper method. I soon wanted to start experimenting more with how to make the process more automated, as well as how I could become more precise and play with different variables in order to change the flavors of my roasted coffee.
There are some mods you can make to a regular air popcorn popper to give you more control in how your roast your beans, but ultimately I wanted more control.
I present to you, Web Roast:

The finished project with all code can be found on my project's GitHub page: https://github.com/bertwagner/Coffee-Roaster/
Essentially, this is still an air popper but with much more control. The key features include:
- Air temperature probe
- Ability to switch the fan and heat source on/off independently
- Holding a constant temperature
- Automatic graphing of roast profiles
- Ability to run saved roast profiles
Now instead of standing at my kitchen counter turning the air popper on and off, holding a digital temperature probe, and shaking the whole roaster to circulate and cool the beans between "on" cycles, I can simply control all of these conditions from my iPhone.
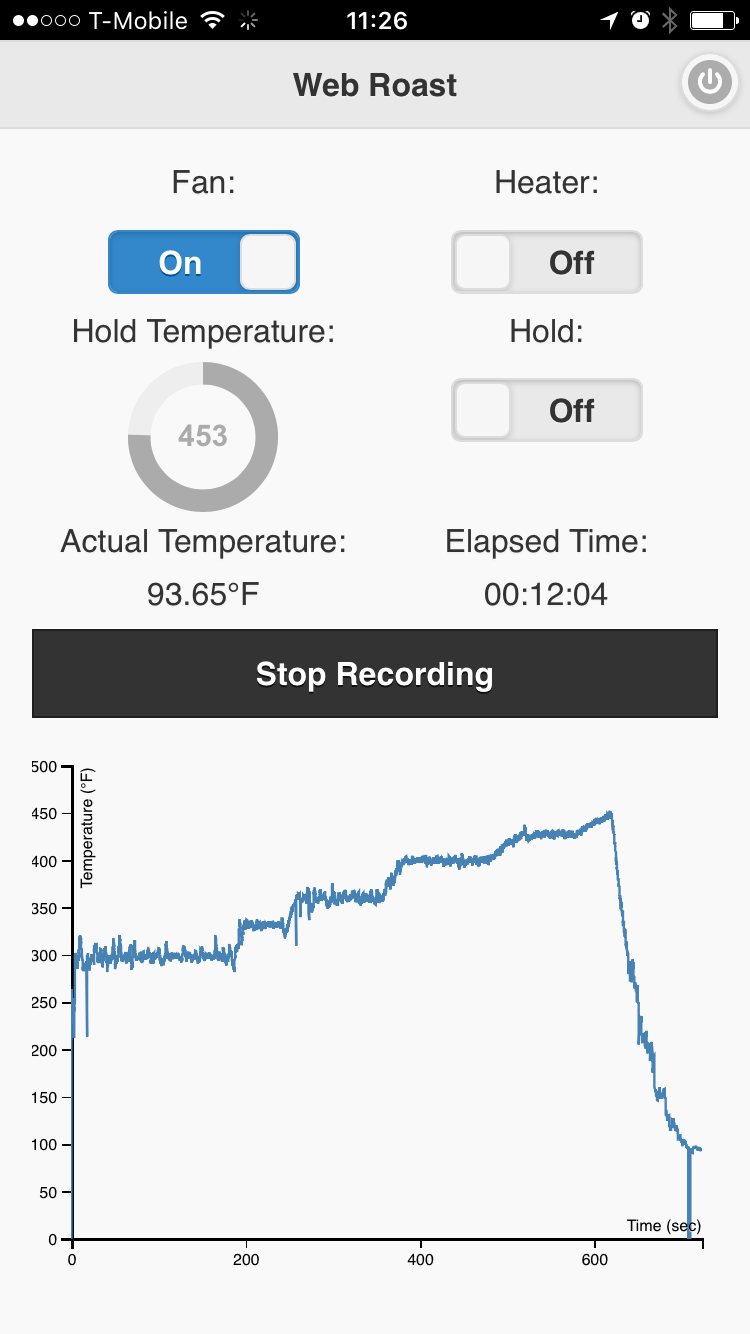
From my phone I decide when to heat the beans, when to maintain a certain temperature, how quickly or slowly to hit certain roasting stages or "cracks", and logging to make sure I can reproduce results in future runs.
Beans develop different flavors based on how quickly or slowly they go through different phases of roasting. Some beans might be better suited for quick roasts that will maintain acidic fruit flavors. Other beans might need to be roasted more slowly to bring out nutty and cocoa flavors. The moisture content of a bean will also have an effect on roasting times, as well as beans that are sourced from different regions of the world.
Next Steps
Although I'm extremely satisfied with how my roaster has turned out, there's still a lot on the to-do list.
I'm currently adding functionality to save roast profiles, so after an initial run of desired results, reproducing those results for the same batch of green beans is easy.
In the future, I'd like to build a second, bigger drum-style roaster for being able to roast larger batches at a time.
Follow my Github coffee roaster project page to keep up with any future updates. Also I would love to hear from anyone who has built similar projects of their own.
Good luck and happy roasting!