For the past couple weeks I've been writing about how to protect your database from a SQL injection attack. Today, we will keep the trend going by looking at how implicit unicode conversions can leave your data vulnerable.
Watch this week's video on YouTube
What's a homoglyph?
A homoglyph is a character that looks like another character. l (lowercase "L") and 1 (the number) are considered homoglyphs. So are O (the letter) and 0 (the number).
Homoglpyhs can exist within a character set (like the Latin character set examples above) or they can exist between character sets. For example, you may have the unicode apostrophe ʼ, which is a homoglyph to the Latin single quote character ' .
How does SQL Server handle unicode homoglyphs?
Funny you should ask. If you pass in a unicode character to a non-unicode datatype (like char), SQL implicitly converts the unicode character to its closest resembling non-unicode homoglyph.
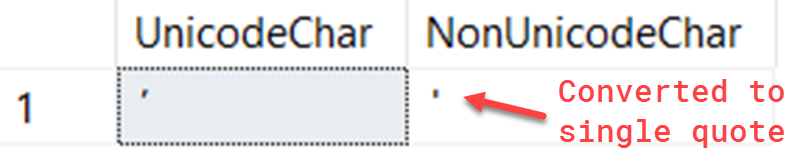
To see this in action, we can use the unicode apostrophe from the example above:
SELECT
CAST(N'ʼ' AS nchar) AS UnicodeChar,
CAST(N'ʼ' AS char) AS NonUnicodeChar
You can see in the second column SQL automatically converted the apostrophe to a single quote:
Although this implicit character conversion can be convenient for when you want to display unicode characters in a non-unicode character set, it can spell disaster for your SQL Server security.
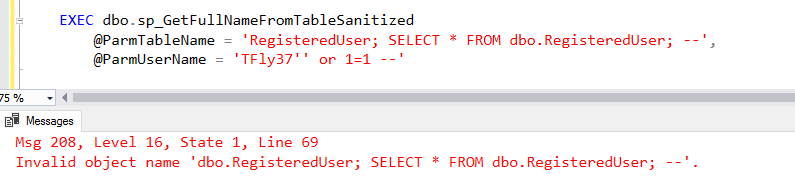
Unicode Homoglyph SQL Injection
If you are already using sp_executesql or QUOTENAME() when building your dynamic SQL queries then you are safe from this type of SQL injection.
I know you aren't the kind of person who would ever write your own security functions when solid, safe, and tested functions like the above are available. However, just this one time let's pretend you think you can outsmart a hacker by writing your own quote delimiting code.
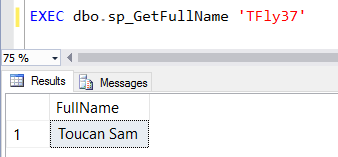
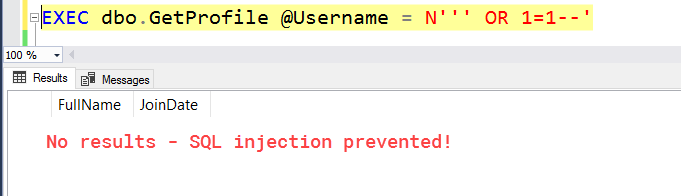
Using the same dataset as last week, let's create a new stored procedure that is going to return some data from a user's profile:
DROP PROCEDURE IF EXISTS dbo.GetProfile
GO
CREATE PROCEDURE dbo.GetProfile
@Username nvarchar(100)
AS
BEGIN
-- Add quotes to escape injection...or not?
SET @Username = REPLACE(@Username, '''','''''')
DECLARE @Query varchar(max)
SET @Query = 'SELECT
FullName,
JoinDate
FROM
dbo.RegisteredUser
WHERE
UserName = ''' + @Username + '''
'
EXEC(@Query)
END
GO
Instead of using sp_executesql or QUOTENAME(), let's try to write our own clever REPLACE() function that will replace single quotes with two sets of single quotes. This should, in theory, prevent SQL injection.
If we test out a "normal" attempt at SQL injection, you'll notice this logic works great. Give yourself a pat on the back!
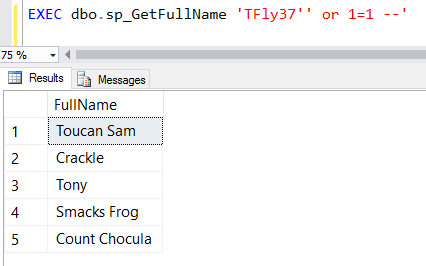
However, if we pass in a unicode apostrophe...:
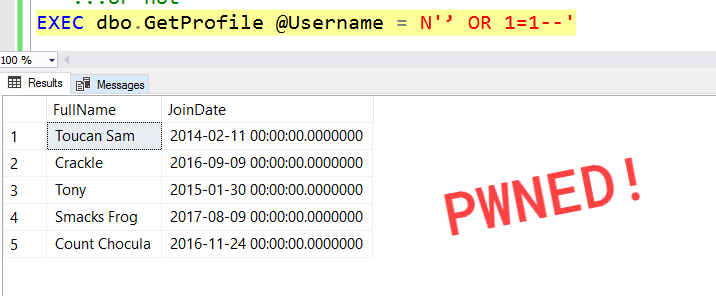
The reason this happens is because we declared our @Query parameter as varchar instead of the unicode nvarchar. When we build our dynamic SQL statement, SQL implicitly converts the nvarchar @Username parameter to the non-unicode varchar:

So if I replace apostrophes will that make me safe?
No.
I know it seems like black listing/replacing the unicode apostrophe would solve all of our problems.
And it would...in this scenario only. There are more unicode homoglpyhs than just an apostrophe though.
Out of curiosity I wrote a script to search through the unicode character space to see what other homoglyphs exist:
DECLARE @FirstNumber INT=0;
-- number of possible characters in the unicode space
DECLARE @LastNumber INT=1114112;
WITH Numbers AS (
SELECT @FirstNumber AS n
UNION ALL
SELECT n+1 FROM Numbers WHERE n+1<=@LastNumber
), UnicodeConversion AS (
SELECT
n AS CharacterNumber,
CASE CAST(NCHAR(n) as CHAR(1))
WHEN '''' THEN NCHAR(n)
WHEN ';' THEN NCHAR(n)
END AS UnicodeCharacter,
CAST(NCHAR(n) as CHAR(1)) AS ASCIICharacter
FROM Numbers
)
SELECT
*
FROM
UnicodeConversion
WHERE
UnicodeCharacter IS NOT NULL
OPTION (MAXRECURSION 0)
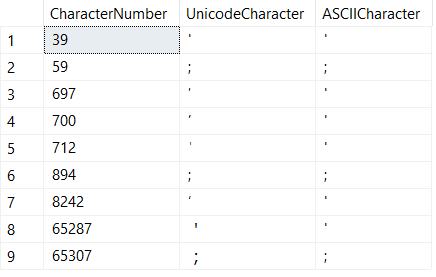
Although the characters in the above screen shot might look similar, they are actually homoglyphs.
I decided to only search for single quotes and semi-colons since they are frequently used in SQL injection attacks, but this by no means is an extensive list of all of the characters you would want to blacklist.
Not only would it be very difficult to confidently blacklist every dangerous homoglyph, but new characters are being added to unicode all of the time so maintaining a black list would be a maintenance nightmare. Especially if the person maintaining this code in the future isn't familiar with these types of injection attacks.
And don't be cheeky thinking you can filter out dangerous SQL keywords either - even if you REPLACE(@Username,'SELECT',''), just remember someone can come by and pass in a value like 'ŚεℒℇℂƮ'.
Conclusion
Don't write your own security functions - they will fail.
Your best protection against SQL injection is to not use dynamic SQL. If you have to use dynamic SQL, then use either sp_executesql and QUOTENAME().