Protecting against SQL Injection Part 2

Watch this week's video on YouTube
Last week we talked about building dynamic SQL queries and how doing so might leave you open to SQL injection attacks.
In that post we examined how using sp_executesql to parameterize our dynamic SQL statements protects us.
Today, we are going to look at where sp_executesql falls short.
The problem with sp_executesql
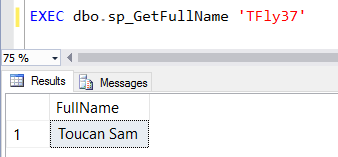
Let's modify last week's final query to make our table name dynamic:
CREATE PROCEDURE dbo.sp_GetFullNameFromTable
@ParmTableName varchar(100),
@ParmUserName varchar(100)
AS
BEGIN
DECLARE @FullQuery nvarchar(1000)
SET @FullQuery = N'SELECT FullName FROM dbo.@TableName WHERE UserName = @UserName'
DECLARE @ParmDefinition nvarchar(100) = N'@TableName varchar(100), @UserName varchar(100)';
EXEC sp_executesql @FullQuery, @ParmDefinition,
@UserName = @ParmUserName,
@TableName = @ParmTableName;
END
(there's an entirely different discussion to be had about whether you should allow table and column names to be dynamic, but we'll assume we need a dynamic table name for the rest of this post)
If we pass in a table name parameter value and execute this query, we'll be greeted with this error:

Yeah, sp_executesql doesn't like parameterizing a table names.
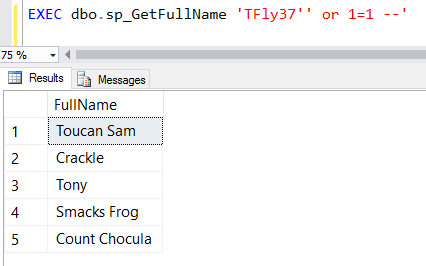
So how do we make table name dynamic and safe?
Unfortunately we have to fall back on SQL's EXEC command.
However, like we discussed last week, we need to be vigilant about what kind of user input we allow to be built as part of our query.
Assuming our app layer is already sanitizing as much of the user input as possible, here are some precautions we can take on the SQL side of the equation:
QUOTENAME()
If we wrap our user input parameters with QUOTENAME(), we'll achieve safety:
CREATE PROCEDURE dbo.sp_GetFullNameFromTableSanitized
@ParmTableName varchar(100),
@ParmUserName varchar(100)
AS
BEGIN
DECLARE @FullQuery nvarchar(1000)
SET @FullQuery = N'SELECT FullName FROM dbo.' + QUOTENAME(@ParmTableName) + ' WHERE UserName = @UserName'
DECLARE @ParmDefinition nvarchar(100) = N'@UserName varchar(100)';
EXEC sp_executesql @FullQuery, @ParmDefinition,
@UserName = @ParmUserName
END
This results in:
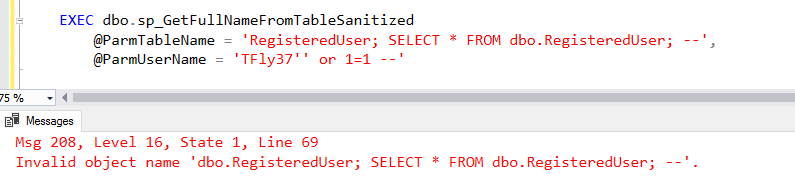
Although QUOTENAME() works well by adding brackets (by default) to sanitize quotes, it's downside is that it will only output strings up to 128 characters long. If you are expecting parameters with values longer than that, you will have to use something like REPLACE(@TableName,'''','''''') instead to delimit single quotes (however, rolling your own logic like this is really hard to do securely and not recommended).
EXECUTE AS
The account running any dynamic SQL queries should be locked down so that it won't be able to perform any operations you don't want it to do.
Taking this idea one step further, you can create another account with very limited permissions, and add EXECUTE AS to your stored procedure to run that code under the very limited account.
CREATE PROCEDURE dbo.sp_GetFullNameFromTableSanitized
@ParmTableName varchar(100),
@ParmUserName varchar(100)
WITH EXECUTE AS 'LimitedUser'
AS
BEGIN
...
This won't prevent injection, but it will limit what the malicious user is able to do.