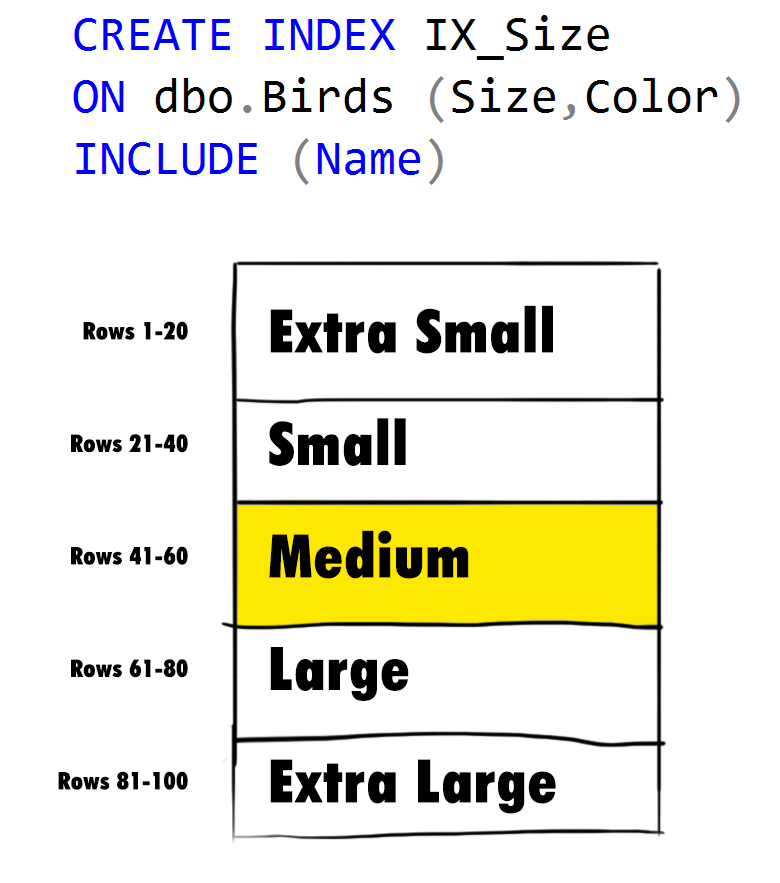
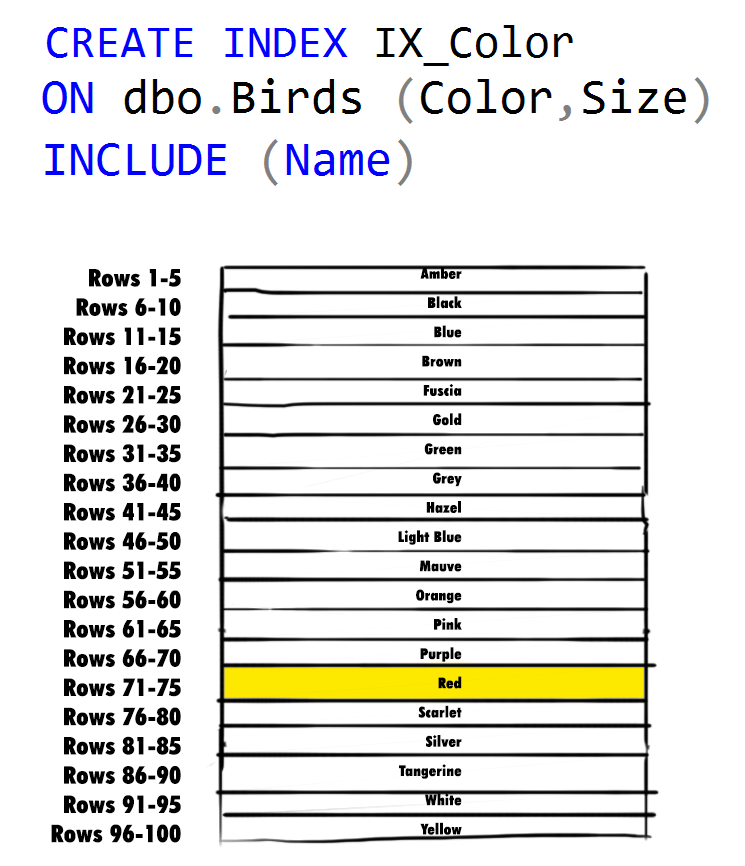
This post is a response to this month's T-SQL Tuesday #111 prompt by Andy Leonard. T-SQL Tuesday is a way for the SQL Server community to share ideas about different database and professional topics every month.
This post is a response to this month's T-SQL Tuesday #111 prompt by Andy Leonard. T-SQL Tuesday is a way for the SQL Server community to share ideas about different database and professional topics every month.
In this month's topic Andy asks why do we do what we do?
Two years ago, I was
bored.
I'd come home from work, spend my free time watching Netflix and surfing the internet, occasionally tinker with some random side projects, and eventually going to bed. Rinse and repeat, day in and day out.
I felt unfulfilled. While I value free time and relaxation, I had an overabundance of it. I felt like I should be doing something more productive with at least some of that time. I wanted to work on my "professional development" somehow, but it was extremely difficult to get motivated to work on boring career stuff.
I decided what I needed was a long-term project that would allow me to have fun and be creative, while also having some positive personal and professional development benefits; what I was looking for was the ULTIMATE side project.
After spending some time thinking about different ideas, I decided to make videos about SQL Server. Not only would I enjoy learning more about how SQL Server works (fun), but I could get practice writing and speaking (career) as well as get to incorporate my other hobby of film making into the mix (creative).
At first it felt forced; while I enjoyed learning new things about SQL Server, it was not easy thinking of topics. Writing and editing was strenuous, but coming up with jokes and visual ways to convey ideas was fun. Filming (and lighting and audio recording) was hard, but editing has always been pure pleasure for me.
So while at times coming up with a weekly bit of content was challenging, I kept at it because not only was it good for me, but I incorporated enough fun and creative elements into the process to look forward to it and keep going with it.
Fast forwarding to today, the process still isn't perfect but things have gotten better: I have enough ideas to probably last me a few years (and generating more all the time), writing is still tough but I've seen noticeable progress so I'm motivated to keep at it, I still don't like being in front of a camera but I have a dramatically easier time speaking about technical topics so the practice has paid off there, and while every episode isn't as creative as I'd like, I have a lot of fun being weird and coming up with new ideas for weekly videos.
Not only that, I now have new motivating factors that I didn't have from day one. I've made friends with a lot of people in the SQL Server community, and they are fantastic and supportive. Many of them even want to collaborate and make fun videos which is something I always look forward to. The audience that consumes the content is wonderful as well; every time I receive a thank you email or comment, I am filled with joy. And obviously all of the skills I have learned - technical, presenting, and networking - have helped immensely in my day-to-day.
In conclusion, the reasons that caused me to start creating SQL Server videos still apply, however over time that list of motivators has grown and helps me continue to remain excited about what I do, even when the challenges feel greater some weeks than others.