This post is a response to this month's T-SQL Tuesday #114 prompt by Matthew McGiffen. T-SQL Tuesday is a way for the SQL Server community to share ideas about different database and professional topics every month. This month Matthew asks us to write about puzzles, so I decided to recreate a childhood favorite in SQL Server.
Watch this week's video on YouTube
As a kid, I found Magic 8 Balls alluring. There is something appealing about a who-knows-how-many-sides die emerging from the depths of a mysterious inky blue fluid to help answers life's most difficult questions.
I never ended up buying a magic eight ball of my own though, so today I'm going to build and animate one in SQL Server Management Studio.
Fun and Valuable? Signs point to yes.
While building a magic eight ball in SQL Server is not the most useful project in the world it is:
- Fun
- A great way to learn lots of cool SSMS and SQL tips and tricks to use in more useful situations.
Here's an example of the finished project followed by all of the components that make this project work. The full code for this solution can be found at the bottom of this post.
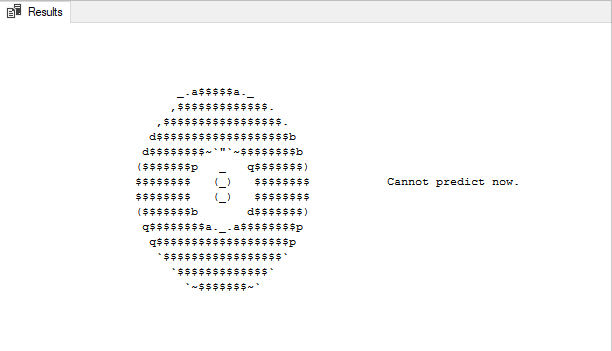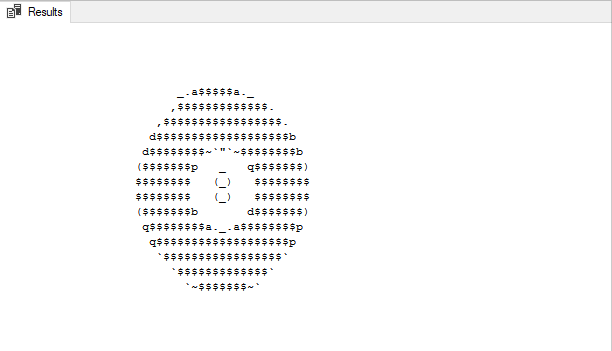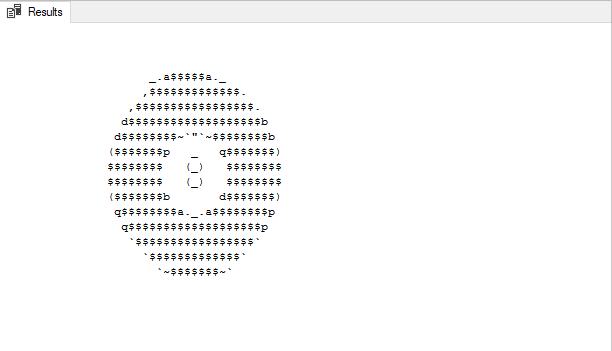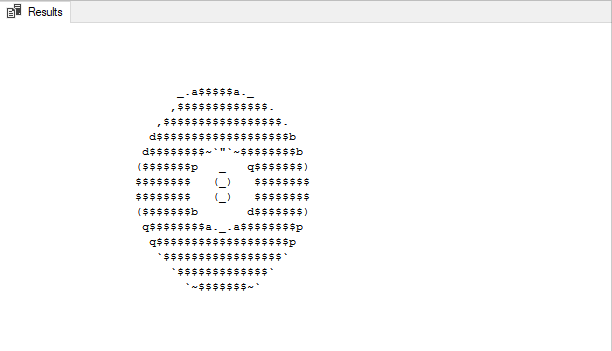
VALUES()
I needed a way to store all of the Magic 8 Ball messages. Some days I like UNIONing together a bunch of SELECT statements, but for these "larger" static datasets I like the syntax of VALUES().
SELECT * FROM
(VALUES
('It is certain.'),
('It is decidedly so.'),
('Without a doubt.'),
('Yes - definitely.'),
('You may rely on it.'),
('As I see it, yes.'),
('Most likely.'),
('Outlook good.'),
('Yes.'),
('Signs point to yes.'),
('Reply hazy, try again.'),
('Ask again later.'),
('Better not tell you now.'),
('Cannot predict now.'),
('Concentrate and ask again.'),
('Don''t count on it.'),
('My reply is no.'),
('My sources say no.'),
('Outlook not so good.'),
('Very doubtful.')
) T(Response)
ORDER BY NEWID()
After we create our data set of static messages, we need to randomly return 1 message for every shake of the eight ball. My favorite way to return one random record is to order the data by NEWID() (creating a random order for values) and then using TOP 1 to return only the first random record:
DECLARE @Message varchar(100) = '';
WITH MagicResponses AS (
...<VALUES() query from above>...
)
SELECT TOP 1 @Message = Response FROM MagicResponses ORDER BY NEWID();
Table Driven Animation
While I never have used this technique for animating an image before, I have used a control table to drive what data should get processed in an ETL.
In today's case, instead of saving the values of what data was last manipulated in an SSIS package, I'll be storing what each action each frame of animation should display, as well as how much delay to put in between each frame:
CREATE TABLE dbo.AnimationControl
(
Id int IDENTITY PRIMARY KEY,
ActionToTake varchar(20),
DelayToTake varchar(20),
ActionTakenDate datetime2
);
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeLeft','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeRight','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeLeft','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeRight','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeLeft','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeRight','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('Reveal','00:00:00.500');
WAITFOR DELAY
I wanted there to be a different delay between certain animation frames (I believe the final message reveal deserves a slightly more dramatic pause), so I'm using WAITFOR DELAY to achieve that.
WAITFOR DELAY @DelayToTake;
The goal here is to print this ascii 8 ball shaking left and right before displaying the message. We do this using good old fashioned PRINT(). After printing a particular frame we update our control table to indicate that particular frame has been drawn.
IF @CurrentActionType = 'ShakeLeft'
BEGIN
PRINT('
_.a$$$$$a._
,$$$$$$$$$$$$$.
,$$$$$$$$$$$$$$$$$.
d$$$$$$$$$$$$$$$$$$$b
d$$$$$$$$~`"`~$$$$$$$$b
($$$$$$$p _ q$$$$$$$)
$$$$$$$$ (_) $$$$$$$$
$$$$$$$$ (_) $$$$$$$$
($$$$$$$b d$$$$$$$)
q$$$$$$$$a._.a$$$$$$$$p
q$$$$$$$$$$$$$$$$$$$p
`$$$$$$$$$$$$$$$$$`
`$$$$$$$$$$$$$`
`~$$$$$$$~`
')
END
GO
You might be wondering why I decided to use a control table to dictate what images to animate. The trouble was that in order to get the PRINT to actually display our ascii images on screen in SSMS, the batch needed to finish submitting. So each frame we print needs to be part of its own batch.
Since we have 7 frames in our animation, we need to execute our procedure 7 times.
Alternatively we can use GO 7, but then we get that ugly batch execution completed message which I don't think there is anyway to hide:
EXEC dbo.USP_ShakeThe8Ball;
GO 7
-- OR
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
Completely Useless? I guess not
I've always been a fan of occasionally taking a break to build things for pure fun. It's a good way to apply lesser known features to your code, stretch your creativity for solving problems, and of course push software functionality to their limits through feature abuse.
Here is the full set of code if you want to run it for yourself (note, this works on a 1920x1080 resolution monitor with SSMS at full screen...your results may vary):
CREATE OR ALTER PROCEDURE dbo.USP_ShakeThe8Ball
AS
BEGIN
/* Hide extra output to the messages window that will ruin our animation */
SET NOCOUNT ON;
SET ANSI_WARNINGS OFF;
/* Set up a table to keep track of our animation frames and insert into it */
IF OBJECT_ID('dbo.AnimationControl') IS NULL
BEGIN
CREATE TABLE dbo.AnimationControl
(
Id int IDENTITY PRIMARY KEY,
ActionToTake varchar(20),
DelayToTake varchar(20),
ActionTakenDate datetime2
);
END;
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeLeft','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeRight','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeLeft','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeRight','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeLeft','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('ShakeRight','00:00:00.100');
INSERT INTO dbo.AnimationControl (ActionToTake,DelayToTake) VALUES ('Reveal','00:00:00.500');
DECLARE @CurrentActionId int = 1;
DECLARE @CurrentActionType varchar(20) = 'ShakeLeft';
DECLARE @DelayToTake varchar(20) = '00:00:00.100';
/* If more than 1 second elapsed, clear the control table */
DECLARE @LastRunDate datetime2;
SELECT @LastRunDate = MAX(ActionTakenDate) FROM dbo.AnimationControl;
IF DATEDIFF(millisecond,@LastRunDate,GETDATE()) > 1000
BEGIN
UPDATE dbo.AnimationControl SET ActionTakenDate = NULL;
END
/* Which action/frame are we currently on? */
SELECT @CurrentActionId = MIN(Id) FROM dbo.AnimationControl WHERE ActionTakenDate IS NULL;
SELECT @CurrentActionType = ActionToTake,
@DelayToTake = DelayToTake
FROM dbo.AnimationControl WHERE Id = @CurrentActionId
WAITFOR DELAY @DelayToTake;
/* Since we can't clear the Messages window, we need to fill it with
blank space between animation frames to achieve the desired effect */
PRINT('
');
IF @CurrentActionType = 'ShakeLeft'
BEGIN
PRINT('
_.a$$$$$a._
,$$$$$$$$$$$$$.
,$$$$$$$$$$$$$$$$$.
d$$$$$$$$$$$$$$$$$$$b
d$$$$$$$$~`"`~$$$$$$$$b
($$$$$$$p _ q$$$$$$$)
$$$$$$$$ (_) $$$$$$$$
$$$$$$$$ (_) $$$$$$$$
($$$$$$$b d$$$$$$$)
q$$$$$$$$a._.a$$$$$$$$p
q$$$$$$$$$$$$$$$$$$$p
`$$$$$$$$$$$$$$$$$`
`$$$$$$$$$$$$$`
`~$$$$$$$~`
')
END
If @CurrentActionType = 'ShakeRight'
BEGIN
PRINT('
_.a$$$$$a._
,$$$$$$$$$$$$$.
,$$$$$$$$$$$$$$$$$.
d$$$$$$$$$$$$$$$$$$$b
d$$$$$$$$~`"`~$$$$$$$$b
($$$$$$$p _ q$$$$$$$)
$$$$$$$$ (_) $$$$$$$$
$$$$$$$$ (_) $$$$$$$$
($$$$$$$b d$$$$$$$)
q$$$$$$$$a._.a$$$$$$$$p
q$$$$$$$$$$$$$$$$$$$p
`$$$$$$$$$$$$$$$$$`
`$$$$$$$$$$$$$`
`~$$$$$$$~` ')
END
IF @CurrentActionType = 'Reveal'
BEGIN
DECLARE @Message varchar(100) = '';
WITH MagicResponses AS (
SELECT * FROM
(VALUES
('It is certain.'),
('It is decidedly so.'),
('Without a doubt.'),
('Yes - definitely.'),
('You may rely on it.'),
('As I see it, yes.'),
('Most likely.'),
('Outlook good.'),
('Yes.'),
('Signs point to yes.'),
('Reply hazy, try again.'),
('Ask again later.'),
('Better not tell you now.'),
('Cannot predict now.'),
('Concentrate and ask again.'),
('Don''t count on it.'),
('My reply is no.'),
('My sources say no.'),
('Outlook not so good.'),
('Very doubtful.')
) T(Response)
)
SELECT TOP 1 @Message = Response FROM MagicResponses ORDER BY NEWID();
BEGIN
PRINT('
_.a$$$$$a._
,$$$$$$$$$$$$$.
,$$$$$$$$$$$$$$$$$.
d$$$$$$$$$$$$$$$$$$$b
d$$$$$$$$~`"`~$$$$$$$$b
($$$$$$$p _ q$$$$$$$)
$$$$$$$$ (_) $$$$$$$$ ' + @Message + '
$$$$$$$$ (_) $$$$$$$$
($$$$$$$b d$$$$$$$)
q$$$$$$$$a._.a$$$$$$$$p
q$$$$$$$$$$$$$$$$$$$p
`$$$$$$$$$$$$$$$$$`
`$$$$$$$$$$$$$`
`~$$$$$$$~` ')
END
END
PRINT('
');
UPDATE dbo.AnimationControl SET ActionTakenDate = GETDATE() WHERE Id = @CurrentActionId;
END;
GO
/*
CTRL+T first to show Results as Text
Then highlight and execute the following:
EXEC dbo.USP_ShakeThe8Ball;
GO 7
-- OR
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
EXEC dbo.USP_ShakeThe8Ball;
GO
*/