Watch this week's video on YouTube
A long time ago I built an application that captured user input. One feature of the application was to compare the user's input against a database of values.
The app performed this text comparison as part of a SQL Server stored procedure, allowing me to easily update the business logic in the future if necessary.
One day, I received an email from a user saying that the value they were typing in was matching with a database value that they knew shouldn't match. That is the day I discovered SQL Server's counter intuitive equality comparison when dealing with trailing space characters.
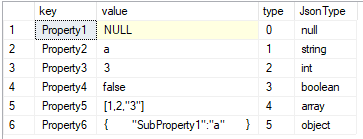
Padded white space
You are probably aware that the CHAR data type pads the value with spaces until the defined length is reached:
DECLARE @Value CHAR(10) = 'a'
SELECT
@Value AS OriginalValue,
LEN(@Value) AS StringLength,
DATALENGTH(@Value) AS DataLength,
CAST(@Value AS BINARY) AS StringToHex;
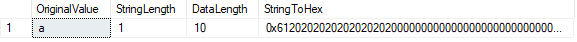
The LEN() function shows the number of characters in our string, while the DATALENGTH() function shows us the number of bytes used by that string.
In this case, DATALENGTH is equal to 10. This result is due to the padded spaces occurring after the character "a" in order to fill the defined CHAR length of 10. We can confirm this by converting the value to hexadecimal. We see the value 61 ("a" in hex) followed by nine "20" values (spaces).
If we change our variable's data type to VARCHAR, we'll see the value is no longer padded with spaces:
DECLARE @Value VARCHAR(10) = 'a'
SELECT
@Value AS OriginalValue,
LEN(@Value) AS StringLength,
DATALENGTH(@Value) AS DataLength,
CAST(@Value AS BINARY) AS StringToHex;

Given that one of these data types pads values with space characters while the other doesn't, what happens if we compare the two?
DECLARE
@CharValue CHAR(10) = '',
@VarcharValue VARCHAR(10) = ''
SELECT
IIF(@CharValue=@VarcharValue,1,0) AS ValuesAreEqual,
DATALENGTH(@CharValue) AS CharBytes,
DATALENGTH(@VarcharValue) AS VarcharBytes
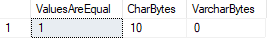
In this case SQL Server considers both values equal, even though we can confirm that the DATALENGTHs are different.
This behavior doesn't only occur with mixed data type comparisons however. If we compare two values of the same data type, with one value containing several space characters, we experience something...unexpected:
DECLARE
@NoSpaceValue VARCHAR(10) = '',
@MultiSpaceValue VARCHAR(10) = ' '
SELECT
IIF(@NoSpaceValue=@MultiSpaceValue,1,0) AS ValuesAreEqual,
DATALENGTH(@NoSpaceValue) AS NoSpaceBytes,
DATALENGTH(@MultiSpaceValue) AS MultiSpaceBytes

Even though our two variables have different values (a blank compared to four space characters), SQL Server considers these values equal.
If we add a character with some trailing whitespace we'll see the same behavior:
DECLARE
@NoSpaceValue VARCHAR(10) = 'a',
@MultiSpaceValue VARCHAR(10) = 'a '
SELECT
IIF(@NoSpaceValue=@MultiSpaceValue,1,0) AS ValuesAreEqual,
DATALENGTH(@NoSpaceValue) AS NoSpaceBytes,
DATALENGTH(@MultiSpaceValue) AS MultiSpaceBytes

Both values are clearly different, but SQL Server considers them to be equal to each other. Switching our equal sign to a LIKE operator changes things slightly:
DECLARE
@NoSpaceValue VARCHAR(10) = 'a',
@MultiSpaceValue VARCHAR(10) = 'a '
SELECT
IIF(@NoSpaceValue LIKE @MultiSpaceValue,1,0) AS ValuesAreEqual,
DATALENGTH(@NoSpaceValue) AS NoSpaceBytes,
DATALENGTH(@MultiSpaceValue) AS MultiSpaceBytes

Even though I would think that a LIKE without any wildcard characters would behave just like an equal sign, SQL Server doesn't perform these comparisons the same way.
If we switch back to our equal sign comparison and prefix our character value with spaces we'll also notice a different result:
DECLARE
@NoSpaceValue VARCHAR(10) = 'a',
@MultiSpaceValue VARCHAR(10) = ' a'
SELECT
IIF(@NoSpaceValue=@MultiSpaceValue,1,0) AS ValuesAreEqual,
DATALENGTH(@NoSpaceValue) AS NoSpaceBytes,
DATALENGTH(@MultiSpaceValue) AS MultiSpaceBytes

SQL Server considers two values equal regardless of spaces occurring at the end of a string. Spaces preceding a string however, no longer considered a match.
What is going on?
ANSI
While counter intuitive, SQL Server's functionality is justified. SQL Server follows the ANSI specification for comparing strings, adding white space to strings so that they are the same length before comparing them. This explains the phenomena we are seeing.
It does not do this with the LIKE operator however, which explains the difference in behavior.
Comparisons when extra spaces matter
Let's say we want to do a comparison where the difference in trailing spaces matters.
One option is to use the LIKE operator as we saw a few examples back. This is not the typical use of the LIKE operator however, so be sure to comment and explain what your query is attempting to do by using it. The last thing you want is some future maintainer of your code to switch it back to an equal sign because they don't see any wild card characters.
Another option that I've seen is to perform a DATALENGTH comparison in addition to the value comparison:
DECLARE
@NoSpaceValue VARCHAR(10) = 'a',
@MultiSpaceValue VARCHAR(10) = 'a '
SELECT
IIF(@NoSpaceValue = @MultiSpaceValue AND DATALENGTH(@NoSpaceValue) = DATALENGTH(@MultiSpaceValue),1,0) AS ValuesAreEqual,
DATALENGTH(@NoSpaceValue) AS NoSpaceBytes,
DATALENGTH(@MultiSpaceValue) AS MultiSpaceBytes

This solution isn't right for every scenario however. For starters, you have no way of knowing if SQL Server will execute your value comparison or DATALENGTH predicate first. This could wreck havoc on index usage and cause poor performance.
A more serious problem can occur if you are comparing fields with different data types. For example, when comparing a VARCHAR to NVARCHAR data type, it's pretty easy to create a scenario where your comparison query using DATALENGTH will trigger a false positive:
DECLARE
@NoSpaceValue VARCHAR(10) = 'a ',
@MultiSpaceValue NVARCHAR(10) = 'a'
SELECT
IIF(@NoSpaceValue = @MultiSpaceValue AND DATALENGTH(@NoSpaceValue) = DATALENGTH(@MultiSpaceValue),1,0) AS ValuesAreEqual,
DATALENGTH(@NoSpaceValue) AS NoSpaceBytes,
DATALENGTH(@MultiSpaceValue) AS MultiSpaceBytes

Here the NVARCHAR stores 2 bytes for every character, causing the DATALENGTHs of a single character NVARCHAR to be equal to a character + a space VARCHAR value.
The best thing to do in these scenarios is understand your data and pick a solution that will work for your particular situation.
And maybe trim your data before insertion (if it makes sense to do so)!