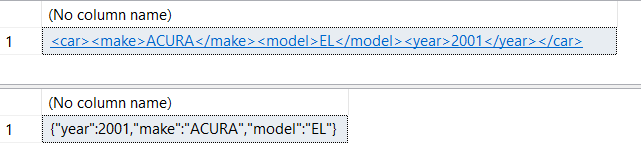
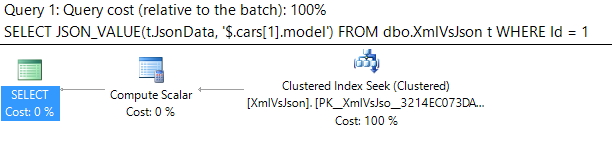
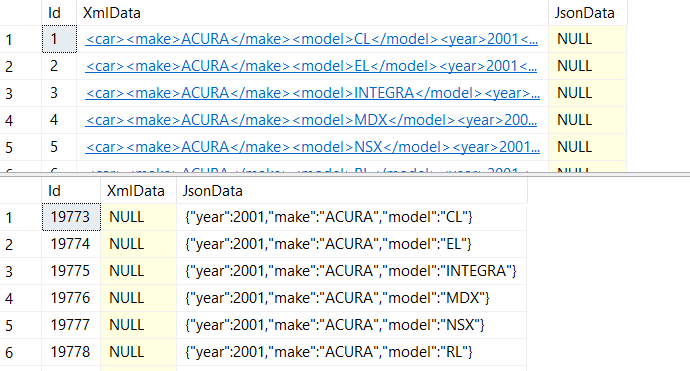
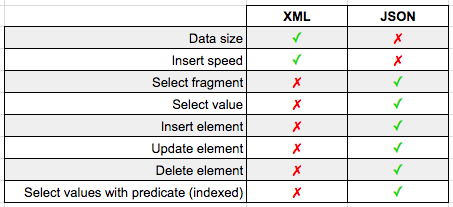
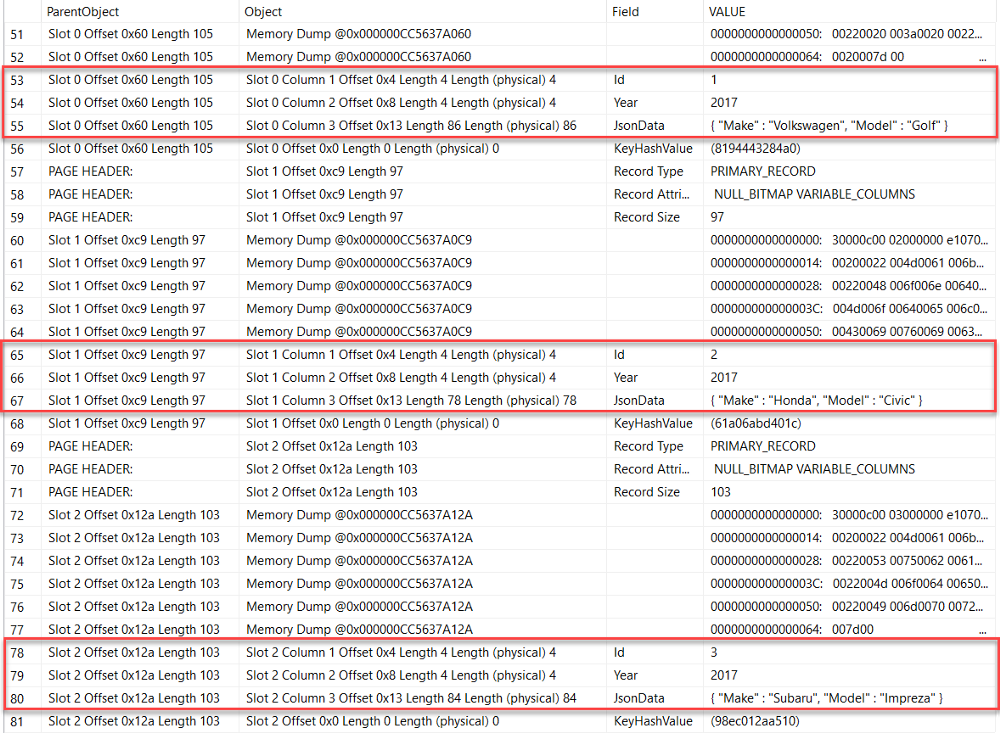
Recently I was discussing with Peter Saverman whether it would be possible to take some database tables that look like this:
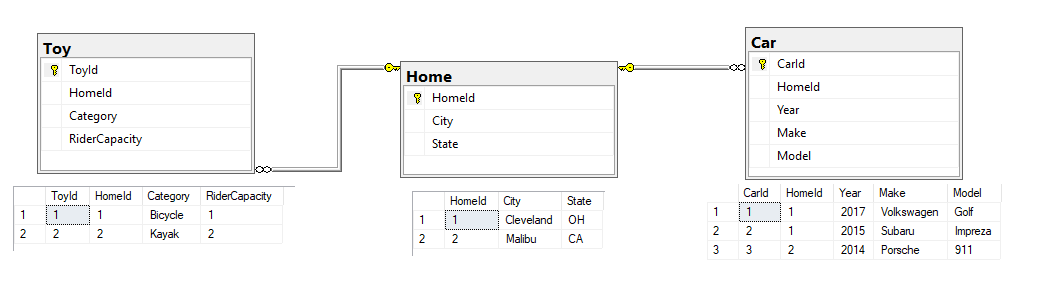
And output them so that the Cars and Toys data would map to a multi-object JSON array like so:

Watch this week's video on YouTube
Why would you ever need this?
If you are coming from a pure SQL background, at this point you might be wondering why you would ever want create an object array that contains mixed object types. Well, from an application development standpoint this type of scenario can be fairly common.
In a database, it makes sense to divide Home and Car and Toy into separate tables. Sure, we could probably combine the latter two with some normalization, but imagine we will have many different types of entities that will be more difficult to normalize - sometimes it just makes sense to store this information separately.
Not to mention that performing analytical type queries across many rows of data will typically be much faster stored in this three table format.
The three table layout, while organized from a database standpoint, might not be the best way to organize the data in an object-oriented application. Usually in a transaction oriented application, we want our data to all be together as one entity. This is why NoSQL is all the rage among app developers. Having all of your related data all together makes it easy to manage, move, update, etc... **This is where the array of multi-type objects comes in - it'd be pretty easy to use this structure as an array of dynamic or inherited objects inside of our application.
Why not just combine these Car and Toy entities in app?
Reading the data into the app through multiple queries and mapping that data to objects is usually the first way you would try doing something like this.
However, depending on many different variables, like the size of the data, the number of requests, the speed of the network, the hardware the app is running on, etc... mapping your data from multiple queries might not be the most efficient way to go.
On the other hand, if you have a big beefy SQL Server available that can do those transformations for you, and you are willing to pay for the processing time on an \$8k/core enterprise licensed machine, then performing all of the these transformations on your SQL Server is the way to go.
The solution
UPDATE: Jovan Popovic suggested an even cleaner solution using CONCAT_WS. See the update at the bottom of this post.
First, here's the data if you want to play along at home:
DROP TABLE IF EXISTS ##Home;
GO
DROP TABLE IF EXISTS ##Car;
GO
DROP TABLE IF EXISTS ##Toy;
GO
CREATE TABLE ##Home
(
HomeId int IDENTITY PRIMARY KEY,
City nvarchar(20),
State nchar(2)
);
GO
CREATE TABLE ##Car
(
CarId int IDENTITY PRIMARY KEY,
HomeId int,
Year smallint,
Make nvarchar(20),
Model nvarchar(20),
FOREIGN KEY (HomeId) REFERENCES ##Home(HomeId)
);
GO
CREATE TABLE ##Toy
(
ToyId int IDENTITY PRIMARY KEY,
HomeId int,
Category nvarchar(20),
RiderCapacity int,
FOREIGN KEY (HomeId) REFERENCES ##Home(HomeId)
);
GO
INSERT INTO ##Home (City,State) VALUES ('Cleveland','OH')
INSERT INTO ##Home (City,State) VALUES ('Malibu','CA')
INSERT INTO ##Car (HomeId,Year, Make, Model) VALUES ('1','2017', 'Volkswagen', 'Golf')
INSERT INTO ##Car (HomeId,Year, Make, Model) VALUES ('2','2014', 'Porsche', '911')
INSERT INTO ##Toy (HomeId,Category, RiderCapacity) VALUES ('1','Bicycle', 1)
INSERT INTO ##Toy (HomeId,Category, RiderCapacity) VALUES ('2','Kayak', 2)
SELECT * FROM ##Home
SELECT * FROM ##Car
SELECT * FROM ##Toy
And here's the query that does all of the transforming:
SELECT
h.HomeId,
h.City,
h.State,
GarageItems = JSON_QUERY('[' + STRING_AGG( GarageItems.DynamicData,',') + ']','$')
FROM
##Home h
INNER JOIN
(
SELECT
HomeId,
JSON_QUERY(Cars,'$') AS DynamicData
FROM
##Home h
CROSS APPLY
(
SELECT
(
SELECT
*
FROM
##Car c
WHERE
c.HomeId = h.HomeId
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
) AS Cars
) d
UNION ALL
SELECT
HomeId,
JSON_QUERY(Cars,'$') AS DynamicData
FROM
##Home h
CROSS APPLY
(
SELECT
(
SELECT
*
FROM
##Toy c
WHERE
c.HomeId = h.HomeId
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
) AS Cars
) d
) GarageItems
ON h.HomeId = GarageItems.HomeId
GROUP BY
h.HomeId,
h.City,
h.State
There are a couple of key elements that make this work.
CROSS APPLY
When using FOR JSON PATH , ALL rows and columns from that result set will get converted to a single JSON string.
This creates a problem if, for example, you want to have a column for your JSON string and a separate column for something like a foreign key (in our case, HomeId). Or if you want to generate multiple JSON strings filtered on a foreign key.
The way I chose to get around this is to use CROSS APPLY with a join back to our Home table - this way we get our JSON string for either Cars or Toys created but then output it along with some additional columns.
WITHOUT_ARRAY_WRAPPER
When using FOR JSON PATH to turn a result set into a JSON string, SQL Server will automatically add square brackets around the JSON output as if it were an array.
This is a problem in our scenario because when we use FOR JSON PATH to turn the Car and Toy table into JSON strings, we eventually want to combine them together into the same array instead of two separate arrays. The solution to this is using the WITHOUT_ARRAY_WRAPPER option to output the JSON string without the square brackets.
Conclusion
Your individual scenario and results may vary. This solution was to solve a specific scenario in a specific environment.
Is it the right way to go about solving your performance problems all of the time? No. But offloading these transformations onto SQL Server is an option to keep in mind.
Just remember - always test to make sure your performance changes are actually helping.
UPDATED Solution Using CONCAT_WS:
This solution recommended by Jovan Popovic is even easier than above. It requires using CONCAT_WS, which is available starting in SQL Server 2017 (the above solution requires STRING_AGG which is also in 2017, but it could be rewritten using FOR XML string aggregation if necessary for earlier versions)
SELECT h.*,
'['+ CONCAT_WS(',',
(SELECT * FROM ##Car c WHERE c.HomeId = h.HomeId FOR JSON PATH, WITHOUT_ARRAY_WRAPPER),
(SELECT * FROM ##Toy t WHERE t.HomeId = h.HomeId FOR JSON PATH, WITHOUT_ARRAY_WRAPPER)
)
+ ']'
FROM ##Home h