Watch this week's video on YouTube
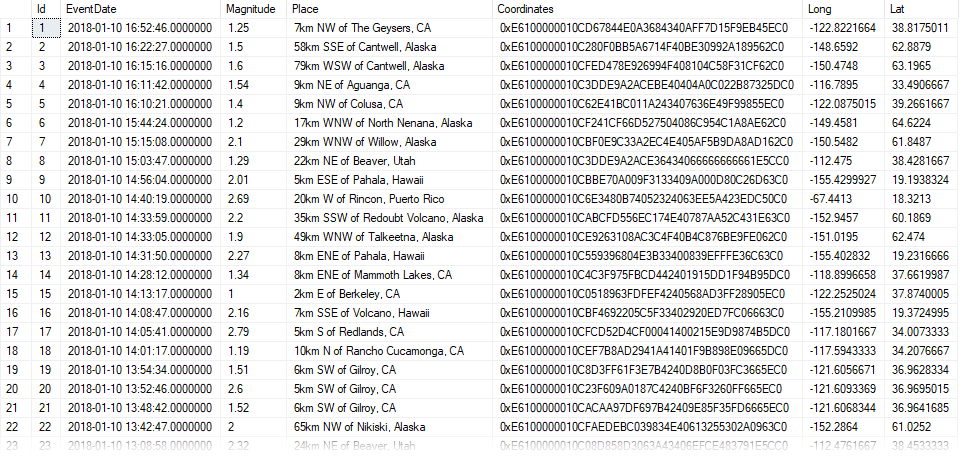
Computed column indexes make querying JSON data fast and efficient, especially when the schema of the JSON data is the same throughout a table.
It's also possible to break out a well-known complex JSON structure into multiple SQL Server tables.
However, what happens if you have different JSON structures being stored in each row of your database and you want to write efficient search queries against all of the rows of your complex JSON strings?
Complex JSON
Let's start out by creating a staging table that contains various fragments of JSON stored in a nvarchar column:
DROP TABLE IF EXISTS dbo.ImportedJson;
GO
CREATE TABLE dbo.ImportedJson
(
Id int IDENTITY,
JsonValue nvarchar(max)
);
GO
INSERT INTO dbo.ImportedJson (JsonValue) VALUES (N'{
"Property1" : "Value1",
"Property2" : [1,2,3]
}');
INSERT INTO dbo.ImportedJson (JsonValue) VALUES (N'{
"Property1" : "Value2",
"Property3" : [1,2,3],
"Property4" : ["A","B","C",null],
"Property5" : {
"SubProp1": "A",
"SubProp2": {
"SubSubProp1":"B",
"SubSubProp2": 1.2,
"SubSubProp3" : true
}
},
"Property6" : [{"ArrayProp":"A"},{"ArrayProp":"B"}],
"Property7" : 123,
"Property8" : null
}');
INSERT INTO dbo.ImportedJson (JsonValue) VALUES (N'{
"Property8" : "Not null",
"Property9" : [4,5,6]
}');
SELECT * FROM dbo.ImportedJSON;
And the results:

Search Queries
If I want to search these values I have a few options.
First, I could write something like:
SELECT * FROM dbo.ImportedJSON WHERE JsonValue LIKE '%Property4" : "["A%';
But that technique is difficult to use on data that I'm not familiar with, and it will run slowly because it won't be able to seek to the data in any indexes.
A second option is to create something like a full text index, but unlike full text indexes on XML columns, I will have to fight with all of the quotes and colons and curly braces since there is no support for JSON. Yuck.
Option 3: Search Table
Option 3 is my favorite: normalize the data into a key and value columns that are easy to search:
WITH JSONRoot AS (
SELECT
Id as RowId,
CAST(hierarchyid::GetRoot().ToString() + CAST(ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS NVARCHAR(4000)) + '/' AS NVARCHAR(4000)) as [HierarchyId],
[key],
[value],
CAST([type] AS INT) AS [type]
FROM
dbo.ImportedJson
CROSS APPLY OPENJSON(JsonValue,'$')
UNION ALL
SELECT
RowId,
CAST(JSONRoot.[HierarchyId] + CAST(ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS NVARCHAR(4000)) + '/' AS NVARCHAR(4000)),
CASE WHEN JSONRoot.[type] = 4 THEN JSONRoot.[key]+'['+t.[key]+']' ELSE t.[key] END,
t.[value],
CAST(t.[type] AS INT)
FROM
JSONRoot
CROSS APPLY OPENJSON(JSONRoot.[value],'$') t
WHERE
JSONRoot.[type] > 3 /* Only parse complex data types */
)
SELECT
RowId,
CAST([HierarchyId] AS HierarchyId) AS [HierarchyId],
[key],
[value],
[type]
FROM
JSONRoot
ORDER BY
RowId,
[HierarchyId]
GO
Results:
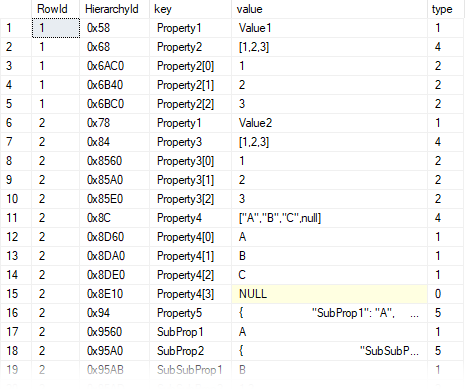
This query parses each property of the original JSON input so that each key-value pair gets put on its row. Complex JSON objects are broken out into multiple rows, and a HierarchyId is included to maintain parent-child relationships if needed.
Having all of this complex JSON parsed out into a key value table now opens up possibilities of what we can do with it.
Process and Indexing
The above query isn't going to run itself. You'll either need to schedule it or incorporate it into an ETL to parse out your staged JSON data on a regular basis (kind of like full text indexing works asyncronously).
Alternatively you can write the logic into a trigger that fires on new row inserts into your staging table if you need this data in real-time. As with all triggers though, I wouldn't recommend this if your staging table is getting rows added at a high rate.
Once you decide how to store your parsed JSON data, add some indexes that will help your search queries run nice and fast (CREATE NONCLUSTERED INDEX IX_Value_Include ON dbo.ParsedJSON ([value]) INCLUDE ([key],RowId) would probably be a good starting point for many search queries) and you'll be doing a lot better than WHERE JsonValue LIKE '%Property4%'.
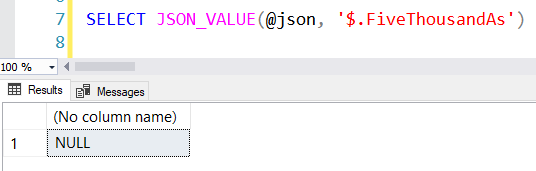




 A significant portion of Yellowstone National Park sits on top of a
A significant portion of Yellowstone National Park sits on top of a