Watch this week's video on YouTube
- Part 1: Introduction to Execution Plans
- Part 2: Overview of Statistics
- Part 3: Reading an Execution Plan
- Part 4: Commonly Troublesome Operators
- Part 5: Troubleshooting Execution Plans
Last week we looked at what execution plans are and how you can view them.
This week I want to discuss what data the query optimizer uses to make cost-based calculations when generating execution plans. Understanding the meta-data SQL Server uses to generate query plans will later help us correct poorly performing queries.
Statistics
Statistics are the primary meta data used by the query optimizer to help estimate the costs of retrieving data for a specific query plan.
The reason SQL Server uses statistics is to avoid having to calculate information about the data during query plan generation. For example, you don't want to have the optimizer scan a billion row table to learn information about it, only to then scan it again when executing the actual query.
Instead, it's preferable to have those summary statistics pre-calculated ahead of time. This allows the query optimizer to quickly generate and compare multiple candidate plans before choosing one to actually execute.
Creating and Viewing Statistics
Statistics are automatically maintained when the Auto Create Statistics and Auto Update Statistics database properties are on (in general, you want to leave these on):
Now, anytime an index is created or enough data in that index has changed (see thresholds for the amount of data in the SQL Server documentation), the statistics information will be updated and maintained as well.
To view the statistics for an index or column, you can run DBCC SHOW_STATISTICS:
DBCC SHOW_STATISTICS('dbo.Users','PK_Users_Id')
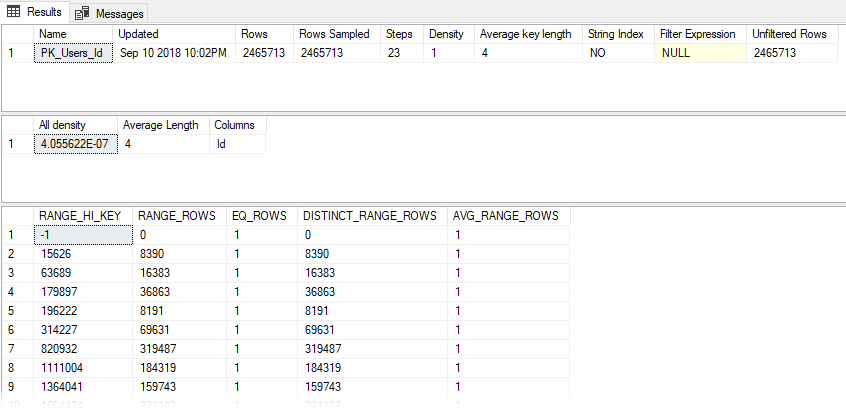
Statistics Data
The data returned by DBCC SHOW_STATISTICS is what SQL Server uses to interpret what the data in your index looks like.
I don't to turn this into a deep dive on statistics , but here are a few key things you should be aware of in this statistics output: - Rows: the number of rows in the table. - Rows Sampled: how many rows were used to calculate these statistics. This can be a subset or all of the rows of your table. - All Density: a measure of how many distinct values are in your data. - Histogram: shows frequencies for up to 200 ranges of values in your index.
Altogether, this information helps paint a picture of your data for the SQL Server query optimizer to use for deciding how it should retrieve your data.
When this picture is accurate, the query optimizer makes decisions that allow your queries execute relatively efficiently. If it has correct estimates about the number of rows it needs to process and the uniqueness of values within those rows, then the query optimizer will most likely allocate appropriate amounts of memory, choose efficient join algorithms, and make other performance choices that will make your query run efficiently.
When the statistics don't accurately represent the data, the query optimizer still tries to do the best with the information it has available but often ends up making some less-than-optimal choices.
We'll save troubleshooting statistics information for another post, but for now be aware that if your statistics are inaccurate, there is a pretty good change SQL Server won't generate efficient execution plans.
Cardinality Estimators
Having high level statistics about your data is only the first part of the equation. SQL Server needs to use those statistics alongside some assumptions to estimate how expensive it will be to retrieve that data.
The assumptions SQL Server makes about data are contained within the Cardinality Estimator. The Cardinality Estimator is a model that makes assumptions about things like data correlation, distribution, and more.
There are two cardinality estimating models currently available in SQL Server: the Legacy Cardinality Estimator available from SQL Server 7.0 to SQL Server 2012, and the New Cardinality Estimator introduced in SQL Server 2014. Each of these Cardinality Estimators makes different assumptions about your data and can therefore produce different results. General guidance suggests to use the New Cardinality Estimator for new work, however sometimes it can be beneficial to use the Legacy Cardinality Estimator if its assumptions more closely align with your data.
Once again, I don't want to go too deep on the differences between cardinality estimators, but it's worth knowing that if you are getting bad estimates from the New Cardinality Estimator, you can easily revert to the Legacy Cardinality Estimator by appending the following hint to the end of your query:
OPTION (USE HINT ('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
Conclusion
SQL Server pre-calculates statistics data on indexes and columns to provide the Query Optimizer information about the data it needs to retrieve. When these statistics accurately reflect what the data actually looks like, SQL Server will typically generate execution plans that perform well. When this data is outdated or missing, SQL Server makes an uninformed guess about how to retrieve the data, potentially causing serious performance issues.