Watch this week's video on YouTube
- Part 1: Introduction to Execution Plans
- Part 2: Overview of Statistics
- Part 3: Reading an Execution Plan
- Part 4: Commonly Troublesome Operators
- Part 5: Troubleshooting Execution Plans
When examining a query's execution plan, certain operators tend to crop up over and over again as the culprits of many performance problems.
Today I want to share which execution plan operators I typically look at first when checking for performance issues. While seeing these operators in your plans isn't necessarily a bad thing, they are always worth a double check to see if they are the cause of your query performance bottlenecks.
This is part 4 of a series on execution plans. Need to catch up? Check out part 1's introduction to execution plans, part 2's overview of statistics, and part 3's explanation of how to read an execution plan.
Index Seek and Index Scan
Some of the first execution plan operators that many people learn to look for are clustered and non-clustered index seeks and scans. General wisdom says that seeks are good for performance because they represent SQL Server navigating directly to the rows of data it needs, while scans are bad because they represent SQL Server reading down the index to extract many rows, leading to a slower operation.
In general, this is a pretty good generalization. However, it's often important to check what your seek and scan operators are doing because it might not always be what you expect.
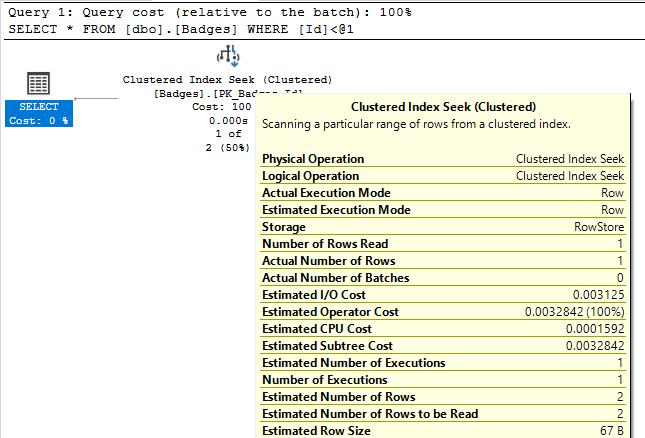
For example, look at the Actual Number of Rows property for these two index seek operations:
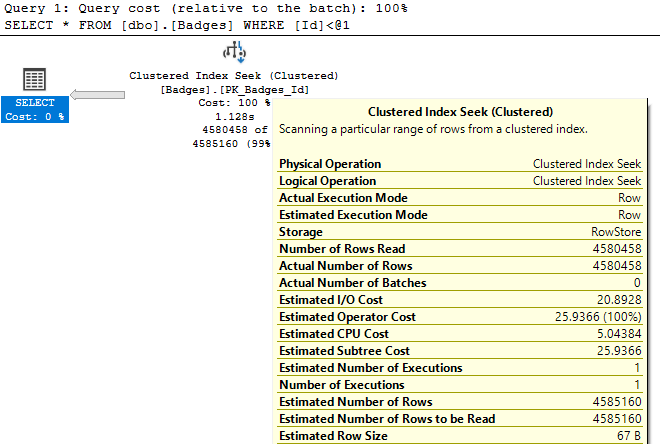
In the first result set, we see the index seek returns 1 row based on our query's WHERE clause. This is the kind of performance we like to see! In the second query however, SQL Server "seeks" 4 million rows. While having an index seek return 4 million rows isn't necessarily a bad thing if that's what we actually need the query to do, it does show that not all seek operations are highly targeted, fast retrievals that you might expect when seeing the index seek operator.
And seeing an index scan doesn't immediately mean bad performance either:
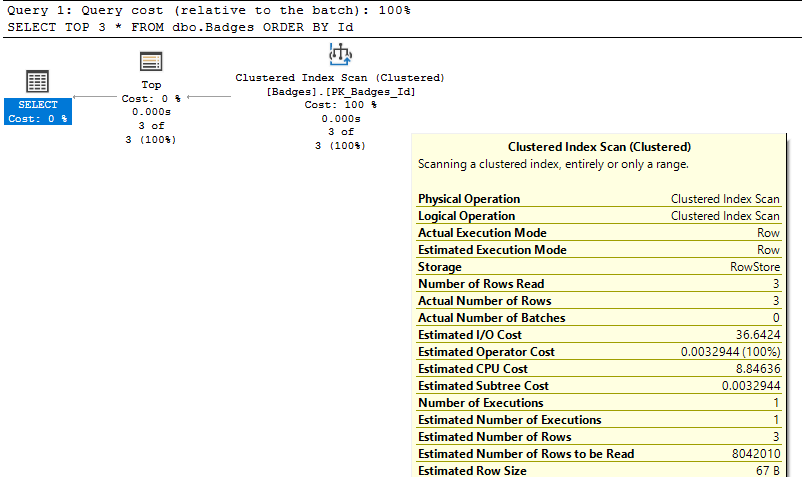
In this case, the index scan only returns 3 records. You won't be able to get much better performance than what you already have, even if you try to refactor your query/indexes to get this to become an Index Seek operation.
RID Lookup and Key Lookup
Another duo of operators I look for when troubleshooting performance in query plans are the RID and Key Lookup operators.
RID Lookup is an easy fix - if you see this operator, it means you are missing a clustered index on your table. At the very least you should add a clustered index and immediately get some improved performance for most if not all of your queries.
Key lookups are more nuanced. SQL Server uses a Key Lookup when it knows it can use a nonclustered index to retrieve data efficiently, but then has to go out to the clustered index to look up the remaining values for the rows that weren't present in the nonclustered index.
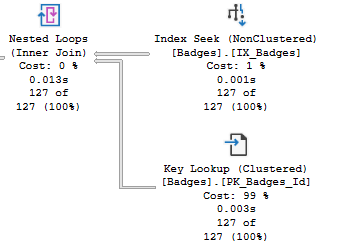
Key lookups aren't necessarily always bad. Having SQL Server go out to the clustered index to retrieve the missing values it needs is pretty efficient compared to having to create and maintain whole new indexes.
However, if all SQL Server is retrieving from the Key Lookup operation is a single column of data, it might be just as easy to add that one column to your existing nonclustered index. Yes, the index size will be bigger by that one column, but if SQL Server can avoid having to go to two indexes to return all the data it needs, it will probably be more efficient overall.
Sort

Sort operators are simple in what they do: they change the order of the rows of data that are flowing through it.
Sorting is one of the most expensive operations that can occur in an execution plan though, so it is best to avoid them as much as possible.
One of the easiest ways to avoid a sort operator is to have the data stored in that pre-ordered format. This can be accomplished by creating an index with the key columns listed in the same order as what the sort operator is doing.
If SQL Server is having to sort the same data in the same order multiple times as part of your execution plan, another possibility is to break the query up into multiple steps with indexed temporary tables used to stage the data in between each step. While replacing a single sort operator with an indexed temp table won't benefit performance, if you can reuse that temporary table multiple times as part of your query execution then you will obtain a net performance savings.
Spools

Spools come in a variety of types, but most of them can be summarized as operators that store an intermediary result table in tempdb.
SQL Server often uses spools to process complex queries, transforming the data into a tempdb worktable to allow further data operations. The downside to this however is the need to write the data to disk in tempdb.
When I see a spool, I first often try to think if there is a way to rewrite the query to avoid the spool in the first place. If that fails, using the divide and conquer temp table technique can also replace a spool, giving you more control over how SQL Server is writing and indexing the data in tempdb.
Joins

I've written about nested loops joins, merge joins, and hash match joins before, but it's worth mentioning them in this post as well.
Merge joins are interesting to spot because of how rarely I see them in real-world queries; they cause celebration instead of concern however because they typically are the most efficient of the logical join operators.
Nested loops joins on the other hand I see often. I don't usually focus on these too much unless something else seems suspicious in the area surrounding them. Nested loops joins do a pretty good job of efficiently joining relatively small sets of data.
Hash match joins I almost always inspect closer. These join operators are typically chosen by the query optimizer for one of two reasons:
- The datasets being joined are so large that they can only be handled by a hash match join.
- The datasets are not ordered on their join columns and SQL Server thinks calculating hashes and looping through will be faster than sorting the data.
For the first scenario, there is not much you can do besides figuring out a way to join less data.
The second scenario is worth looking at a little more closely. If there is some way to get the data in ordered before joining, like predefining the sort order in an index, then it's possible SQL Server will choose a faster join algorithm instead.
Parallelism
Parallelism operators are typically viewed as good things: SQL Server chunks your data into multiple parts to be processed asynchronously on multiple CPUs, reducing the total wall clock time that it takes for your query to finish.

However, parallelism can be a bad thing if ALL (or most) queries utilize parallelism. Parallelism isn't magic, the CPUs are still doing the same amount of work (and taking away resources from other queries that could be running), plus the overhead that you have to account for of SQL Server dividing up and then rejoining all of the data from multiple CPU threads.
I typically become suspicious of parallelism if it seems like most queries I troubleshoot on a server are producing parallel plans. If that's the case, I may consider revisiting the cost threshold for parallelism setting to see if it is set too low.
More operators
This post is not a definitive list of all execution plan operators; I tried to cover the ones I see causing me problems the most often.
If you are interested in learning about more operators, you can visit the official documentation or Hugo's wonderful SQL Server Execution Plan Reference's Operator List.