Watch this week's video on YouTube
While I know I don't utilize most of the features available in SQL Server, I like to think I'm at least aware that those features exist.
This week I found a blind-spot in my assumption however. Even though it shipped in SQL Server 2012, the SQL Server CHOOSE function is a feature that I think I'm seeing for the first time this past week.
CHOOSE is CASE
CHOOSE returns the n-th item from a comma-delimited list.
Whenever learning a new feature in SQL Server I try to think of a good demo I could build to test out the functionality. In this case the immediate example that came to mind was building something that would provide a lookup of values:
SELECT
[key],
[value],
[type],
CHOOSE(type+1,'null','string','int','boolean','array','object') AS JsonType
FROM
OPENJSON(N'{
"Property1":null,
"Property2":"a",
"Property3":3,
"Property4":false,
"Property5":[1,2,"3"],
"Property6":{
"SubProperty1":"a"
}
}');
In this case, the OPENJSON function returns a "type" field that indicates the datatype of that particular JSON property's value. The issue is that the "type" column is numeric and I can never remember what type of data each number represents.
The above query solves this by using CHOOSE to create a lookup of values. Since OPENJSON returns results starting with 0, we need to use type+1 in order to get the 1-based CHOOSE function to work correctly:
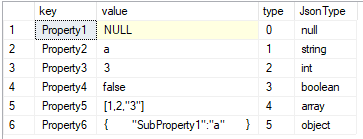
If we look at the CHOOSE function's scalar operator properties in the execution plan, we'll see that this function is just a fancy alias for a more verbose CASE statement:
[Expr1000] = Scalar Operator(
CASE WHEN (CONVERT_IMPLICIT(int,OPENJSON_DEFAULT.[type],0)+(1))=(1)
THEN 'null'
ELSE
CASE WHEN (CONVERT_IMPLICIT(int,OPENJSON_DEFAULT.[type],0)+(1))=(2)
THEN 'string'
ELSE
CASE WHEN (CONVERT_IMPLICIT(int,OPENJSON_DEFAULT.[type],0)+(1))=(3)
THEN 'int'
ELSE
CASE WHEN (CONVERT_IMPLICIT(int,OPENJSON_DEFAULT.[type],0)+(1))=(4)
THEN 'boolean'
ELSE
CASE WHEN (CONVERT_IMPLICIT(int,OPENJSON_DEFAULT.[type],0)+(1))=(5)
THEN 'array'
ELSE
CASE WHEN (CONVERT_IMPLICIT(int,OPENJSON_DEFAULT.[type],0)+(1))=(6)
THEN 'object'
ELSE NULL END
END
END
END
END
END
)
The Set-Based Way
I think one of the reasons I've never used CHOOSE is because I would hate typing up all of those lookup values and trapping them in a SELECT statement, never to be used again.
Previously, I would have stored the lookup values in table and joined them with the OPENJSON results to accomplish the same end result:
DROP TABLE IF EXISTS #JsonType;
CREATE TABLE #JsonType
(
Id tinyint,
JsonType varchar(20),
CONSTRAINT PK_JsonTypeId PRIMARY KEY CLUSTERED (Id)
);
INSERT INTO #JsonType VALUES (0,'null');
INSERT INTO #JsonType VALUES (1,'string');
INSERT INTO #JsonType VALUES (2,'int');
INSERT INTO #JsonType VALUES (3,'boolean');
INSERT INTO #JsonType VALUES (4,'array');
INSERT INTO #JsonType VALUES (5,'object');
SELECT
j.[key],
j.[value],
j.[type],
t.JsonType
FROM
OPENJSON(N'{
"Property1":null,
"Property2":"a",
"Property3":3,
"Property4":false,
"Property5":[1,2,"3"],
"Property6":{
"SubProperty1":"a"
}
}') j
INNER JOIN #JsonType t
ON j.[type] = t.Id
While more initial setup is involved with this solution, it's more flexible long-term. With a centralized set of values, there's no need to update the CHOOSE function in all of your queries when you can update the values in a single lookup table.
And while I didn't bother performance testing it, by virtue of being a scalar function, CHOOSE will probably perform worse in many real-world scenarios when compared to the table-based lookup approach (eg. large datasets, parallel plans, etc...).
CHOOSE What Works For You
I'm not surprised that it took me this long to learn about the CHOOSE function: while a simplified way to write certain CASE statements, I can't think of many (any?) scenarios where I would prefer to use it over a CASE or a lookup-table solution.