This month's T-SQL Tuesday topic asked "What code would you hate to live without?" Turns out you like using script and code to automate boring, repetitive, and error-prone tasks.
This month's T-SQL Tuesday topic asked "What code would you hate to live without?" Turns out you like using script and code to automate boring, repetitive, and error-prone tasks.
Thank you to everyone who participated; I was nervous that July holidays and summer vacations would stunt turnout, however we wound up with 42 posts!
Watch tsqltuesday.com for next month's topic and consider signing up to host.
Watch this week's video on YouTube
Without further ado, here are this month's entries sorted in random order:
- Stuart Moore shares the history behind needing to automate restore testing and writing the SqlAutoRestores PowerShell module to help. Nowadays his commands are found in dbatools. Great example of how a project can evolve through the community.
- Arthur Daniels shares his script to identify the key and included columns of indexes in a given table.
- Glenn Berry shares his DMV Diagnostic Queries and the story behind how he started developing them back in 2006.
- Jason Brimhall links to multiple scripts he's shared in the past as well as a new script for remotely auditing server access to catch infilitraters red-handed.
- Doug Purnell talks about how he uses database snapshots and shares some code for how he manages them.
- Jay Robinson shares two C# extensions (shout to my fellow devs!): one to check an enum for a value and a second to cleanly handle the lengthy DBNull.Value syntax.
- Drew Furgiuele shares how he scripts out his indexes to re-apply after snapshot replication. He then writes very similar functionality using PowerShell in only 6 lines!
- Tim Weigel shares which community scripts he uses regularly, as well as sharing his own scripts around replication, stored procedure execution information, and file manipulation.
- Hugo Kornelis submitted two posts. The first post shares sp_metasearch which helps with performing impact analysis and the second post follows up with an enhancement he's made to Ola Hallengren's database maintenance scripts to ignore backup BizTalk databases.
- Andy Mallon shares his comprehensive script for checking database, file, data, log, etc... sizes. Great explanations of his reasoning for writing the queries the way he did.
- Dan Clemens shares his database search script with a switch that includes searching across agent jobs.
- Jess Pomfret wrote a script that shows compression stats for database objects. Wanting to run it against a whole instance (or across mulitple servers), she wrote a dbatools command to automate the process.
- Kenneth Fisher shows us how he organizes his toolbox using an SSMS solution.
- Rob Farley shares code he's written to demonstrate the pain of using NOLOCK.
- Steve Jones shares a procedure from Microsoft that he uses for transferring logins and passwords between instances.
- Kevin Hill shares two scripts he uses for finding low-hanging index optimization fruit: one that finds queries performing heap or clustered index scans, and another that returns the top 5 missing indexes per database.
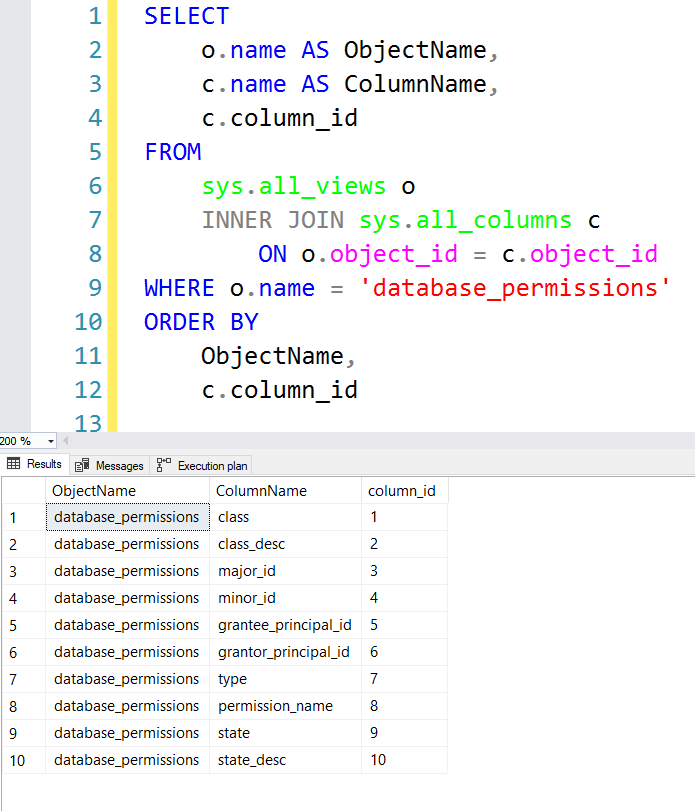
- Michael Villegas learned that Azure SQL doesn't allow you to graphically show user roles and permissions, so he wrote a script to query those details (works for on-premise SQL Server as well).
- Nate Johnson shares scripts that identify if tables are being replicated, whether SSRS subscriptions executed, and how much space certain objects and files are consuming.
- William Andrus shares how he uses his search script to find similarly named fields or all instances of a piece of text within a database.
- Bert Wagner (me!) I share my template for generating dynamic table-driven code, making queries more adaptable to future changes.
- Rudy Rodarte shows us a script he uses for iterating over a date range to use for executing date based queries.
- Brent Ozar admits he can't live without sp_Blitz, but this month he shares a script for checking how much plan cache history exists on a server.
- Jeff Mlakar offers a solution for taking all databases on an instance offline (and then back online) again.
- Erik Darling offers a solution for constructing dynamic SQL so that his MAX variables don't get truncated. He also links to a script for printing long strings in SSMS.
- Chrissy LeMaire takes the hard work out of instance to instance migrations by sharing her single-line dbatools command that will do it all for you. She also shares how dbachecks automates manual checklist work.
- Glenda Gable mentions two procedures, one that is a high performance cursor rewrite and one that is a robust log shipping solution.
- Aaron Bertrand shows us how he discovers undocumented SQL Server features by comparing new builds to the previous versions.
- Ryan Desmond writes about his post-install confirguration process and shares code he runs to customize Ola Hallengren's maintenance scripts for his environments.
- Josh Simar shares his database file size code that is optimized for "very large databases" that span multiple files and filegroups.
- Sander Stad discusses the importance of sharing code and offers a few dbatools commands that he's contributed to or authored around backup testing, log shipping, and SQL Server Agent manipulation.
- Andy Levy wrote an SSMS snippet to generate a cursor. Before you chew him out though, he has some really good uses cases for needing to use them.
- Andy Yun reveals what's in his T-SQL toolbox and explains his organization strategies for 10+ years of scripts he's collected.
- Eduardo Pivaral shares a script he uses to output query results into an HTML table, making it easy to copy into an email.
- Raul Gonzalez shows us a versatile script for searching database tables and returning information on attributes such as column name, size, key definitions, and more.
- Matthew McGiffen wanted to find the most expensive queries on an instance using Query Store instead of the traditional DMVs, so he wrote a script to do just that.
- Daniel Hutmacher shares his beefed up version of sp_help. Includes ASCII art dependency graphs and database search.
- Christian Gräfe provides a function he wrote for padding the left-side of a value with zeros.
- Adrian Buckman shares his SQLUndercover Inspector HTML reporting tool, as well as scripts for helping to alter AG groups, checking for running jobs, and auditing failed logins.
- Louis Davidson shares his technique for using relative positioning in date tables to make querying custom periods (eg. your company's fiscal month) easier.
- Lance England shares a PowerShell script to automate generating upsert merge statements for his ETLs.