Watch this week's video on YouTube
SQL Server Spool operators are a mixed bag. On one hand, they can negatively impact performance when writing data to disk in tempdb. On the other hand, they allow filtered and transformed result sets to be temporarily staged, making it easier for that data to be reused again during that query execution.
The problem with the latter scenario is that SQL Server doesn't always decide to use a spool; often it's happy to re-read (and re-process) the same data repeatedly. When this happens, one option you have is to explicitly create your own temporary staging table that will help SQL Server cache data it needs to reuse.
This post is a continuation of my series to document ways of refactoring queries for improved performance. I'll be using the StackOverflow 2014 data dump for these examples if you want to play along at home.
No spools
Let's start by looking at the following query:
WITH January2010Badges AS (
SELECT
UserId,
Name,
Date
FROM
dbo.Badges
WHERE
Date >= '2010-01-01'
AND Date <= '2010-02-01'
), Next10PopularQuestions AS (
SELECT TOP 10 * FROM (SELECT UserId, Name, Date FROM January2010Badges WHERE Name = 'Popular Question' ORDER BY Date OFFSET 10 ROWS) t
), Next10NotableQuestions AS (
SELECT TOP 10 * FROM (SELECT UserId, Name, Date FROM January2010Badges WHERE Name = 'Notable Question' ORDER BY Date OFFSET 10 ROWS) t
), Next10StellarQuestions AS (
SELECT TOP 10 * FROM (SELECT UserId, Name, Date FROM January2010Badges WHERE Name = 'Stellar Question' ORDER BY Date OFFSET 10 ROWS) t
)
SELECT UserId, Name FROM Next10PopularQuestions
UNION ALL
SELECT UserId, Name FROM Next10NotableQuestions
UNION ALL
SELECT UserId, Name FROM Next10StellarQuestions
Note: This is not necessarily the most efficient way to write this query, but it makes for a good demo.
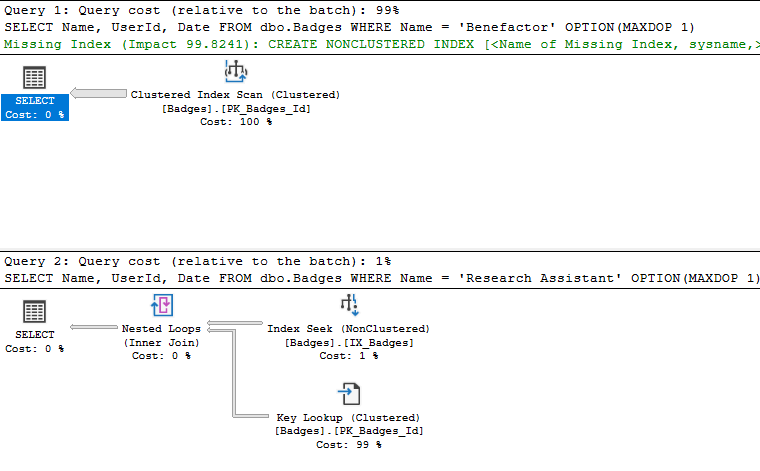
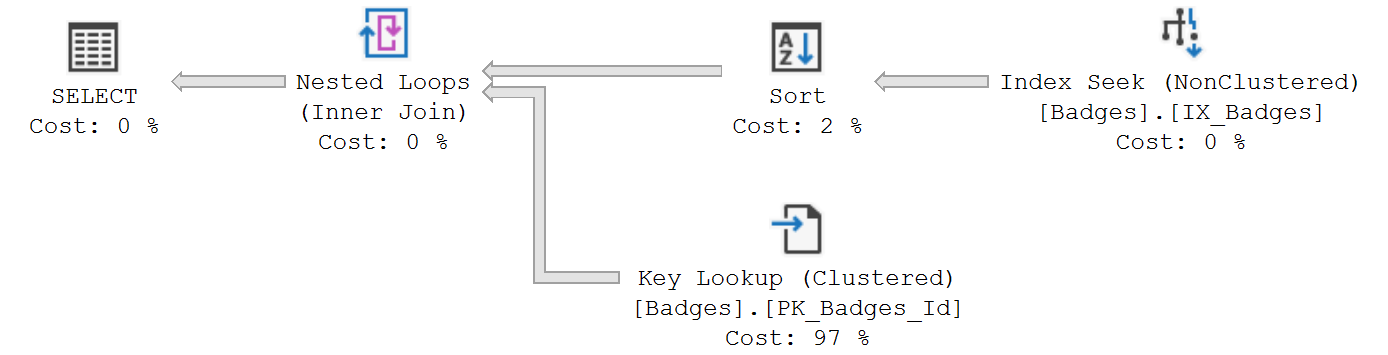
This query is returning offset results for different badges from one month of data in the dbo.Badges table. While the query is using a CTE to make the logic easy to understand (i.e. filter the data to just January 2010 results and then calculate our offsets based on those results), SQL Server isn't actually saving the results of our January2010Badges expression in tempdb to get reused. If we view the execution plan, we'll see it reading from our dbo.Badges clustered index three times:
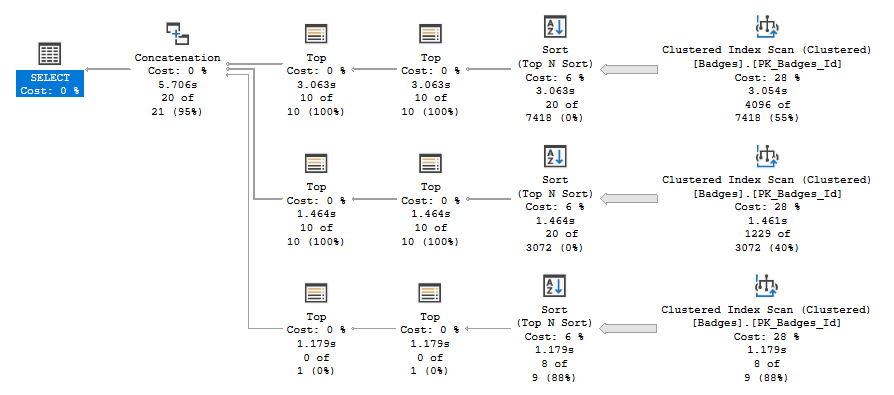
Table 'Badges'. Scan count 27, logical reads 151137, ...
That means every time SQL Server needs to run our offset logic in each "Next10..." expression, it needs to rescan the entire clustered index to first filter on the Date column and then the Name column. This results in about 150,000 logical reads.
Divide and Conquer
One potential solution would be to add a nonclustered index that would allow SQL Server to avoid scanning the entire clustered index three times. But since this series is about improving performance without adding permanent indexes (since sometimes you are stuck in scenarios where you can't easily add or modify an index), we'll look at mimicking a spool operation ourselves.
We'll use a temporary table to stage our filtered January 2010 results so SQL Server doesn't have to scan the clustered index each time it needs to perform logic on that subset of data. For years I've referred to this technique as "temporary staging tables" or "faking spools", but at a recent SQL Saturday Jeff Moden told me he refers to it as "Divide and Conquer". I think that's a great name, so I'll use it going forward. Thanks Jeff!
First let's divide our query so that we insert our January 2010 data into its own temporary table:
DROP TABLE IF EXISTS #January2010Badges;
CREATE TABLE #January2010Badges
(
UserId int,
Name nvarchar(40),
Date datetime
CONSTRAINT PK_NameDateUserId PRIMARY KEY CLUSTERED (Name,Date,UserId)
);
INSERT INTO #January2010Badges
SELECT
UserId,
Name,
Date
FROM
dbo.Badges
WHERE
Date >= '2010-01-01'
AND Date <= '2010-02-01';
You'll notice I added a clustered primary key which will index the data in an order that will make filtering easier.
Next, we conquer by changing the rest of our query to read from our newly created temp table:
WITH Next10PopularQuestions AS (
SELECT TOP 10 * FROM (SELECT UserId, Name, Date FROM #January2010Badges WHERE Name = 'Popular Question' ORDER BY Date OFFSET 10 ROWS) t
), Next10NotableQuestions AS (
SELECT TOP 10 * FROM (SELECT UserId, Name, Date FROM #January2010Badges WHERE Name = 'Notable Question' ORDER BY Date OFFSET 10 ROWS) t
), Next10StellarQuestions AS (
SELECT TOP 10 * FROM (SELECT UserId, Name, Date FROM #January2010Badges WHERE Name = 'Stellar Question' ORDER BY Date OFFSET 10 ROWS) t
)
SELECT UserId, Name FROM Next10PopularQuestions
UNION ALL
SELECT UserId, Name FROM Next10NotableQuestions
UNION ALL
SELECT UserId, Name FROM Next10StellarQuestions
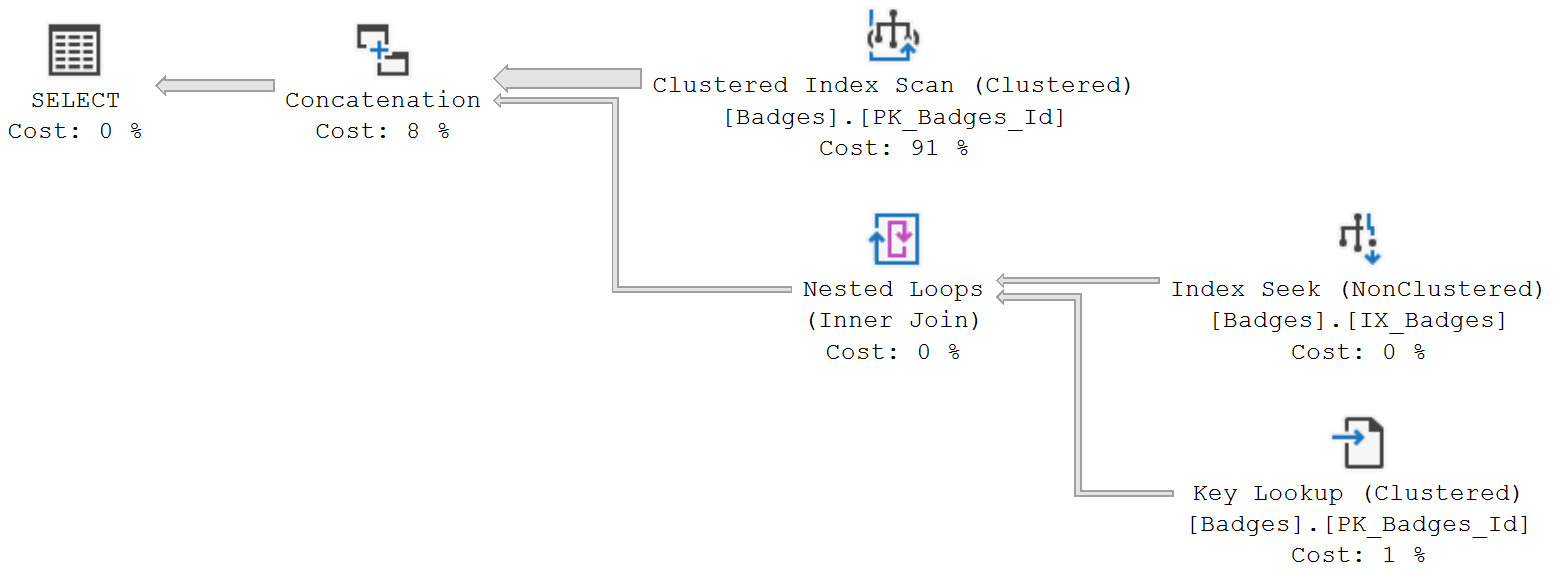
Running this all together, we get the following plans and logical read counts:

Table 'Badges'. Scan count 9, logical reads 50379, ...
(42317 rows affected)
(20 rows affected)
Table '#January2010Badges______________________________00000000003B'. Scan count 3, logical reads 12, ...
In this version of the query, SQL Server scans the clustered index a single time and saves that data to a temporary table. In the subsequent SELECTs, it seeks from this much smaller temporary table instead of going back to the clustered index, reducing the total amount of reads to 50379 + 12 = 50392: about a third of what the original query was doing.
Temporary Staged Data
At the end of day, you can hope that SQL Server creates a spool to temporarily stage or data, or you can be explicit about it and do it yourself. Either option is going to increase usage on your tempdb database, but at least by defining the temporary table yourself you can customize and index it to achieve maximum reuse and performance for your queries.
It's important to note that this is not a technique you want to abuse: writing and reading too much data from tempdb can cause contention problems that can make you worse off than having allowed SQL Server to scan your clustered index three times. However, when implemented sparingly and for good reasons, this technique can greatly improve the performance of certain queries.