
This post is a response to this month's T-SQL Tuesday #118 prompt by Kevin Chant. T-SQL Tuesday is a way for the SQL Server community to share ideas about different database and professional topics every month.
This month's topic asks about our fantasy SQL Server feature.
Watch this week's video on YouTube
Data About The Data
Have you ever wondered who was the last person (or process) to modify a piece of data in your database?
SQL Server offers plenty of system views and functions that provide insight into how your server is running and how your queries are performing. However, it doesn't offer much information about who last modified your data.
That's why my ideal SQL Server feature would be to have a built-in way to audit who last modified a row of data and at what time.
Current Workarounds
Today, this sort of logging can be implemented in the application layer but that requires extra coding and time.
In SQL Server, temporal tables offer part of this functionality with their GENERATED ALWAYS FOR ROW START/END properties, but these only log a row created/row last modified date. There is no built-in way to log which user modified the data. The remaining temporal table functionality also adds unnecessary overhead if you don't actually need to keep track of all of the data history.
Default constraints exist for helping insert default values for when a row was created and who the user was that created the row, but restricting unauthorized access to those fields as well as handling instances where data is updated is not as straight forward.
The closest thing to get this type of automatic logging in SQL Server today is to implement the functionality with triggers. Reinterpreting some of my code I wrote when discussing how to fake temporal tables with triggers, we come up with this:
DROP TABLE dbo.TestData;
CREATE TABLE dbo.TestData (
Id int IDENTITY CONSTRAINT PK_Id PRIMARY KEY,
ColA int,
ColB int,
ColC int,
LastModifiedDate datetime2,
LastModifiedUser nvarchar(30)
);
GO
CREATE TRIGGER AutoLogger ON dbo.TestData
AFTER INSERT,UPDATE
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@CurrentDateTime datetime2 = SYSUTCDATETIME(),
@CurrentUser nchar(30) = SYSTEM_USER
UPDATE t
SET
LastModifiedDate = @CurrentDateTime,
LastModifiedUser = @CurrentUser
FROM
dbo.TestData t
INNER JOIN inserted i
ON t.Id = i.Id;
END
GO
Now, any time a record is created or modified, we log the datetime and the user that performed the modification:
-- Regular insert
INSERT INTO dbo.TestData (ColA,ColB,ColC) VALUES (1,2,3);
-- Regular update
UPDATE dbo.Test SET ColA = 4 WHERE Id = 1;
SELECT * FROM dbo.TestData;
-- Questionable motive insert
INSERT INTO dbo.TestData (ColA,ColB,ColC,LastModifiedDate,LastModifiedUser) VALUES (1,2,3,'9999-12-31','NotMe');
-- Questionable motive update
UPDATE dbo.TestData SET LastModifiedDate = '9999-12-31', LastModifiedUser='NotMe' WHERE Id = 1;
SELECT * FROM dbo.TestData;
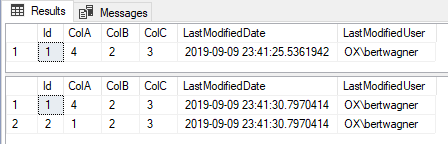
While this solution provides some of the functionality I want, it has many downsides. First, it utilizes a trigger which often gets overlooked (at least initially) when debugging issues, causing confusion and maintenance headaches.
Secondly, there is some overhead in having a trigger run after each and every insert and update. Transaction throughput gets limited since every INSERT/UPDATE on this table will trigger a follow up UPDATE.
Additionally, this solution is not automatic: it must be created individually on every table you want logging on.
Finally, this table now contains extra columns on the clustered index, columns that I don't necessarily always want to be impacting my performance.
The Ideal Feature
I wish there was a database level option that allowed logging of who modified what row of data when. When turned on, it would automatically handle this logging logic (and maybe some more, like specifically what column in addition to what row was modified) without the need to set it up on individual tables or by using triggers.
Additionally, I would love if this data were not persisted on the table's clustered index itself. If there were a way to store the data in a nonclustered index for that table only (kind of like a non-persisted computed column value gets stored) that would be ideal.
Finally, I would love if this meta data were populated asynchronously to not impact the performance of inserts/updates/deletes on the main table of data.

 This post is a response to this month's
This post is a response to this month's 