Photo by James Sutton on Unsplash
Photo by James Sutton on Unsplash
Note: the problem described below applies to all SELECT queries, not just those adorned with NOLOCK hints. The fact that it applies to NOLOCK queries was a huge surprise to me though, hence the title.
Lots of people don't like NOLOCK (i.e. the read uncommitted isolation level) because it can return inaccurate data. I've seen plenty of arguments cautioning developers from retrieving uncommitted reads because of how they can return dirty data, phantom reads, and non-repeatable reads.
I've known about all of those above problems, but there's one problem that I've never heard of until recently: NOLOCK can block other queries from running.
Watch this week's video on YouTube
Let's step back and understand why I've so often used NOLOCK in the past. A fairly typical instance of when I use NOLOCK is when I want to let a query run overnight to return some large set of data. I'm okay with some inconsistencies in the data (from dirty reads, etc...). My primary concern is that I don't want the long running query to get in the way of other processes.
I always thought NOLOCK was a perfect solution for this scenario because it never locks the data that it reads - the results might not be perfect, but at least the query won't negatively impact any other process on the server.
This is where my understanding of NOLOCK was wrong: while NOLOCK won't lock row level data, it will take out a schema stability lock.
A schema stability (Sch-S) lock prevents the structure of a table from changing while the query is executing. All SELECT statements, including those in the read uncommitted/NOLOCK isolation level, take out a Sch-S lock. This makes sense because we wouldn't want to start reading data from a table and then have the column structure change half way through the data retrieval.
However, this also means there might be some operations that get blocked by a Sch-S lock. For example, any command requesting a schema modification (Sch-M) lock gets blocked in this scenario.
What commands request Sch-M locks?
Things like an index REBUILD or sp_recompile table. These are the types of commands running in my nightly maintenance jobs that I was trying to avoid hurting by using NOLOCK in the first place!
To reiterate, I used to think that using the NOLOCK hint was a great way to prevent blocking during long running queries. However, it turns out that my NOLOCK queries were actually blocking my nightly index jobs (all SELECT queries block in this example, but I find the NOLOCK to be particularly misleading), which then caused other SELECT statements to get blocked too!
Let's take a look at this in action. Here I have a query that creates a database, table, and then runs a long running query with NOLOCK:
DROP DATABASE IF EXISTS [Sandbox]
GO
CREATE DATABASE [Sandbox]
GO
USE [Sandbox]
GO
DROP TABLE IF EXISTS dbo.Test
CREATE TABLE dbo.Test
(
c0 int IDENTITY PRIMARY KEY,
c1 varchar(700) default REPLICATE('a',700)
)
CREATE NONCLUSTERED INDEX IX_Id ON dbo.Test (c1);
GO
INSERT INTO dbo.Test DEFAULT VALUES;
GO 1000
-- Read a billion records
SELECT *
FROM
dbo.Test t1 (NOLOCK)
CROSS JOIN dbo.Test t2 (NOLOCK)
CROSS JOIN dbo.Test t3 (NOLOCK)
Now, while that billion row read is occurring, we can verify that the query took out a Sch-S lock by looking at sys.dm_tran_locks:
SELECT *
FROM sys.dm_tran_locks
WHERE resource_type = 'OBJECT'
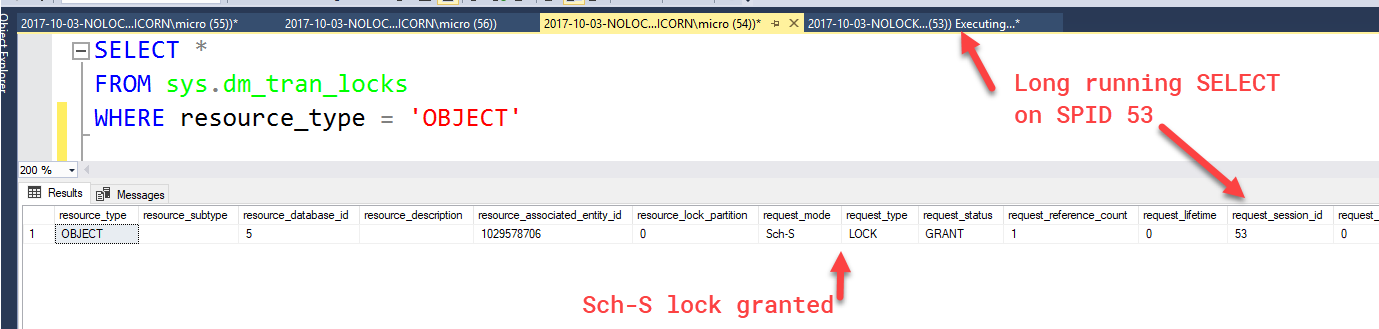
While that's running, if we try to rebuild an index, that rebuild is blocked (shown as a WAIT):
USE [Sandbox]
GO
ALTER INDEX IX_Id ON dbo.Test REBUILD
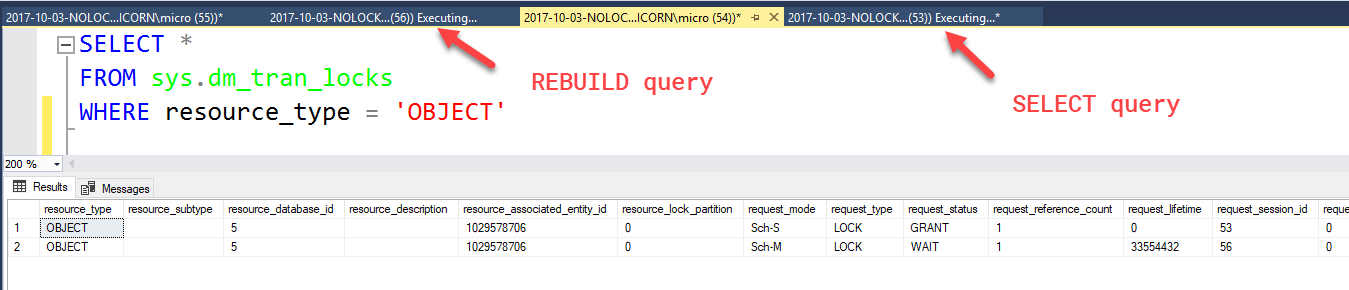
Our index rebuild query will remain blocked until our billion row NOLOCK SELECT query finishes running (or is killed). This means the query that I intended to be completely unobtrusive is now blocking my nightly index maintenance job from running.
Even worse, any other queries that try to run after the REBUILD query (or any other commands that request a Sch-M lock) are going to get blocked as well! If I try to run a simple COUNT(*) query:
USE [Sandbox]
GO
SELECT COUNT(*) FROM dbo.Test
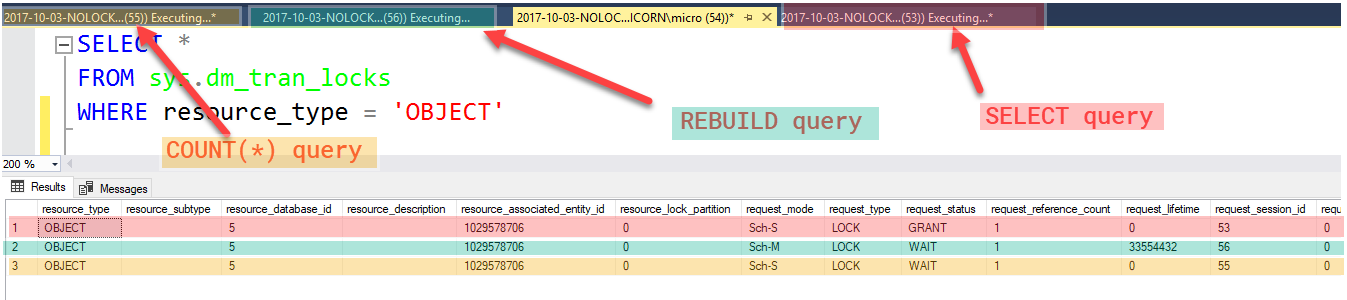
Blocked! This means that not only is my initial NOLOCK query causing my index REBUILD maintenance jobs to wait, the Sch-M lock placed by the REBUILD maintenance job is causing any subsequent queries on that table to get blocked and be forced to wait as well. I just derailed the timeliness of my maintenance job and subsequent queries with a blocking NOLOCK statement!
Solutions
Unfortunately this is a tough problem and there's no one-size-fits-all remedy.
Solution #1: Don't run long running queries
I could avoid running long queries at night when they might run into my index maintenance jobs. This would prevent those index maintenance jobs and subsequent queries from getting delayed, but it means my initial billion row select query would then have to run earlier, negatively impacting server performance during a potentially busier time of day.
Solution #2: Use WAIT_AT_LOW_PRIORITY
Starting in 2014, I could do an online index rebuild with the WAIT_AT_LOW_PRIORITY option set:
ALTER INDEX IX_Id ON dbo.Test REBUILD
WITH (ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 1 MINUTES , ABORT_AFTER_WAIT = BLOCKERS)))
This query basically gives any blocking SELECT queries currently running 1 minute to finish executing or else this query will kill them and then execute the index rebuild. Alternatively we could have also set ABORT_AFTER_WAIT = SELF and the rebuild query would kill itself, allowing the NOLOCK billion row SELECT to finish running and not preventing any other queries from running.
This is not a great solution because it means either the long running query gets killed or the index REBUILD gets killed.
Solution #3: REBUILD if no Sch-S, REORGANIZE otherwise
A programmatic solution can be written that tries to REBUILD the index, but falls back to REORGANIZE if it knows it will have to wait for a Sch-M lock.
I've created the boiler plate below as a starting point, but the sky is the limit with what you can do with it (e.g. create a WHILE loop to check for the lock every x seconds, create a timeout for when the script should stop trying to REBUILD and just REORGANIZE instead, etc...)
-- Idea for how to rebuild/reorganize based on a schema stability lock.
-- More of a starting point than fully functional code.
-- Not fully tested, you have been warned!
DECLARE
@TableName varchar(128) = 'Test',
@HasSchemaStabilityLock bit = 0
SELECT TOP 1 @HasSchemaStabilityLock =
CASE WHEN l.request_mode IS NOT NULL THEN 1 ELSE 0 END
FROM
sys.dm_tran_locks as l
WHERE
l.resource_type = 'OBJECT'
AND l.request_mode = 'Sch-S'
AND l.request_type = 'LOCK'
AND l.request_status = 'GRANT'
AND OBJECT_NAME(l.resource_associated_entity_id) = @TableName
IF @HasSchemaStabilityLock = 0
BEGIN
-- Perform a rebuild
ALTER INDEX IX_Id ON dbo.Test REBUILD
PRINT 'Index rebuilt'
END
ELSE
BEGIN
-- Perform a REORG
ALTER INDEX IX_Id ON dbo.Test REORGANIZE
PRINT 'Index reorganized'
END
This solution is my favorite because:
- Ad hoc long running queries don't get killed (all of that time spent processing doesn't go to waste)
- Other select queries are not blocked by the Sch-M lock attempt by REBUILD
- Index maintenance still occurs, even if it ends up being a REORGANIZE instead of a REBUILD
 Photo by
Photo by