This post is a response to this month's T-SQL Tuesday prompt created by Arun Sirpal. Adam Machanic created T-SQL Tuesday as a way for SQL users to share ideas about interesting topics. This month's topic is "Your Technical Challenges Conquered".
DBA Skills 101: SQL Logins
While writing last week's post about efficiently scripting database objects, I decided to make progress towards my 2018 learning goals by figuring out what database permissions were needed for running SQL Server Management Studio's "Generate Scripts" tool.
I thought it would be best to start with a clean slate so I created a new SQL login and database user so that I could definitively figure out which permissions are needed.
Normally I use Windows Authentication for my logins, but this time I thought "since I'm getting crazy learning new things, let me try creating a SQL Login instead."
After I created my login, I decided to test connecting to my server before digging into the permissions. Result?
Watch this week's video on YouTube
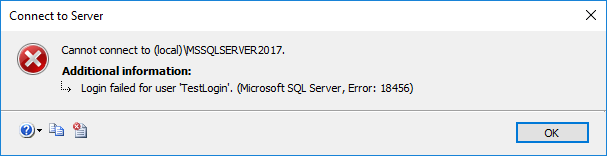
I can't connect!
That's right, I tried to connect and I got this very detailed error message :
"Great," I thought. "I should just switch to a Windows Authentication login, those always work for me."
"BUT NO, THEN I WON'T LEARN ANYTHING!"
On to troubleshooting
First things first, I tried retyping my login and password (I know typing in the password of "password" is really tricky but I've made mistakes doing much simpler things).
No luck. Maybe when I created the login I fat-fingered the password?
I recreated the login, making sure I precisely typed the password. Try to connect again...nope.
Ok, ok. I'm missing something obvious. I have this error message though - maybe the internet will know!
I find the exact error message in a blog post by Aaron Bertrand - he's a credible guy, I bet I'll find the solution there!
Nope.
(Side note: the answer is there, just buried in the comments. In my eager "this will be an easy solution" I didn't bother scrolling down that far).
Ok... how about books online? Even though I created the login through the SSMS GUI, I know the T-SQL command to do the same is CREATE LOGIN. Maybe I'll find the solution in the documentation?
No luck.
(Side note again: in hindsight you can get to the solution from the above link, but it's buried two further links deep. While troubleshooting I was in the mindset of "ain't nobody got time for that" - I wanted a solution given to me immediately without having to do any further research!)
I kept searching online, reading through Stack Overflow answers, not finding what I needed.
(Side note (last one, I promise): anyone else having a harder time searching for relevant Stack Overflow answers? It feels like more and more I find questions/answers that are for older versions and no longer relevant)
At this point I was really frustrated. "CREATING A LOGIN SHOULD BE LIKE THE FIRST THING A DBA LEARNS!! WHY IS THIS SO HARD?!?!?!?!?!?!"
At that point I was tired and disappointed that I had spent more time trying to solve this login problem rather than actually figuring out the permissions that I wanted to include in my blog post.
Sleep
I decided to take a break for the night and revisit the problem the next morning.
As expected, I searched the internet for the answer again and somehow my keyword selection hit the jackpot - I found the Stack Overflow answer telling me I needed to set the server to mixed authentication mode:
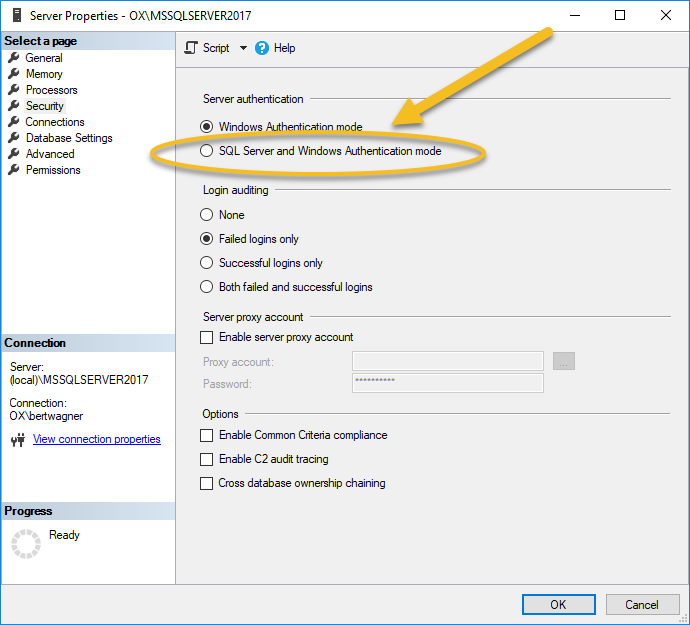
Wow, that was easy.
Takeaway
This wasn't a complex problem. At least, it shouldn't have been a complex problem.
All in all I spent probably 30 minutes trying to figure it out - not the longest amount of time I've sunk into a problem that ended up having a really simple solution.
However, this stuff happens. It's amazing what a fresh (rested) set of eyes can do for solving a problem.
Lesson learned: next time I'm getting frustrated by a problem that I think should be easy to solve, I need to step away from the computer and come back once I have a clearer mindset :).
One Last Technical Challenge (BONUS)
I figured I'd add one more technical challenge to this post: submit a pull request to the sql-docs GitHub.
My rationale was that I couldn't be the only person to have ever been stumped by authentication modes. Maybe I could be helpful to the next person who visits the CREATE LOGIN books online page and give them a hint as to why they can't connect.
Contributing to open source isn't something I've done through Github before, but luckily I had Steve Jones's excellent write up to guide me.
There were no real challenges here since I was just making a simple edit, and low and behold a few days later my PR got merged and is now live in BOL - cool!

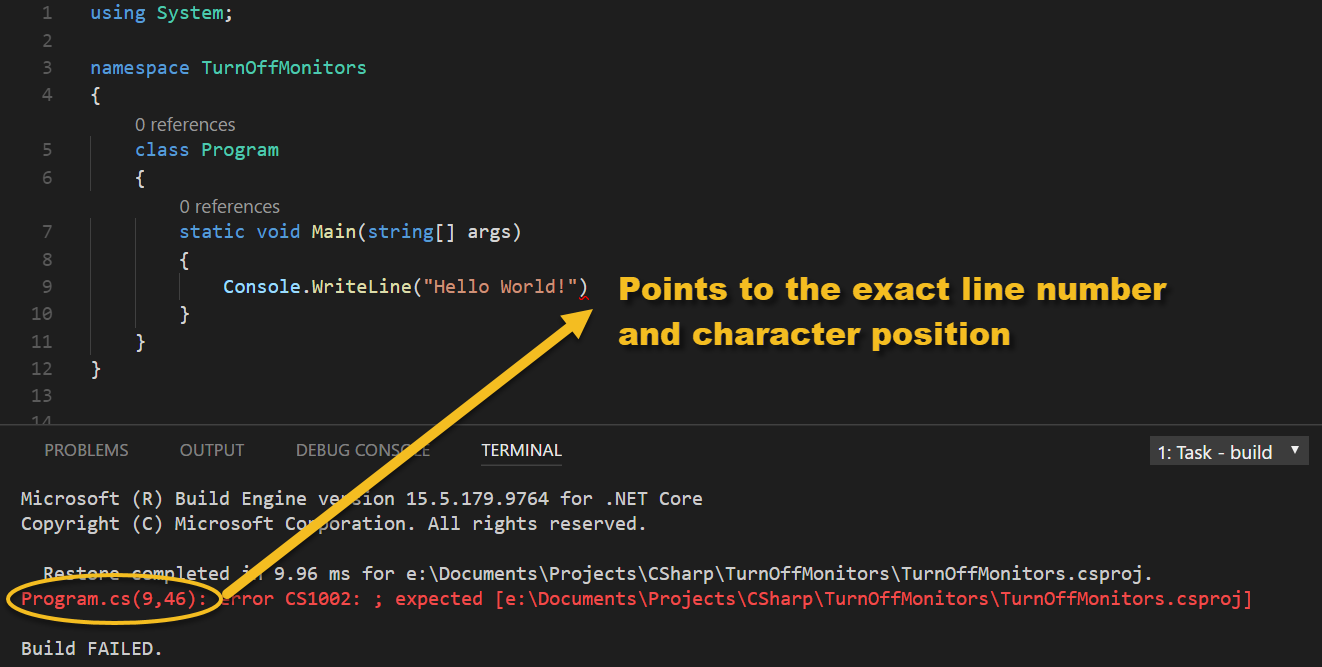 Pinpoint error finding
Pinpoint error finding


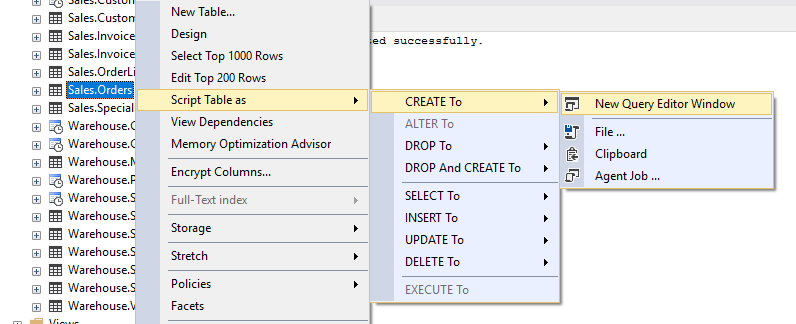 An inefficient way of generating change scripts
An inefficient way of generating change scripts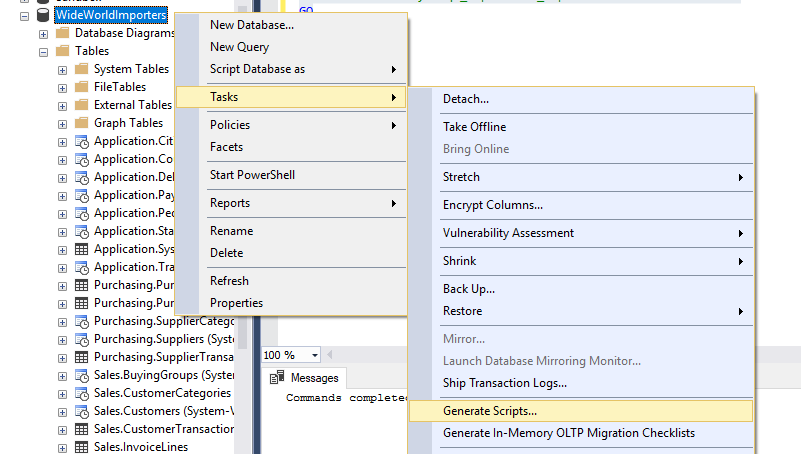
 Look ma, multiple objects at once!
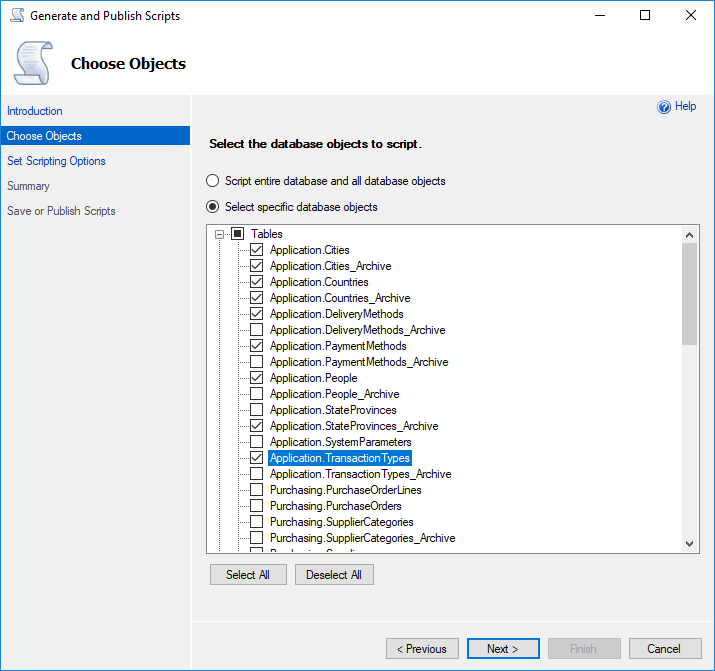
Look ma, multiple objects at once!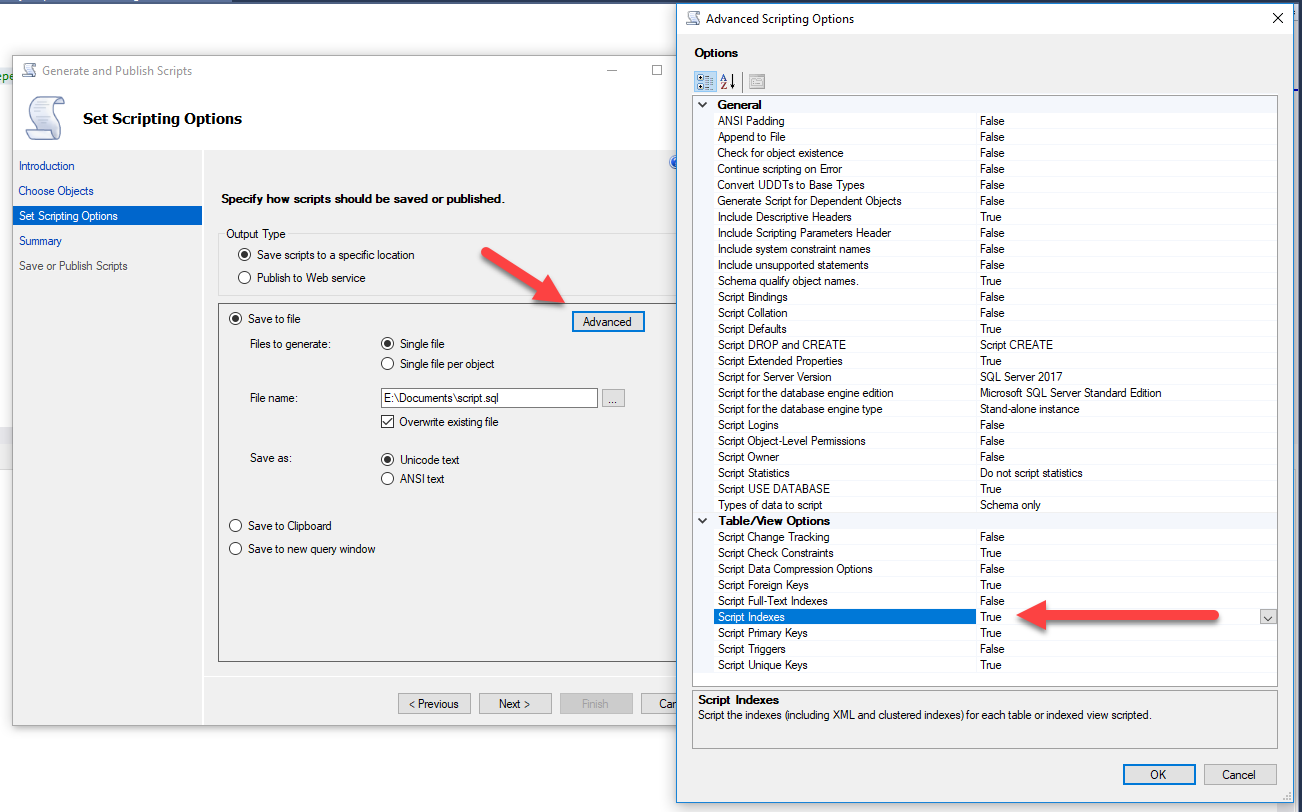 Ooooooo, ahhhh - everything scripted in one fell swoop!
Ooooooo, ahhhh - everything scripted in one fell swoop!