Watch this week's video on YouTube
Want to learn more about using JSON in SQL Server? Watch me present at the online GroupBy conference on June 9, 2017 at 8am.
I've written a few articles this year about how awesome JSON performance is in SQL Server 2016.
The more I continue to use JSON in SQL Server, the more impressed I become with its speed and versatility. Over time I've learned new techniques and realize that JSON in SQL Server is actually much faster than I initially thought.
Today I want to correct some performance tests where I think I unfairly compared SQL Server JSON performance the first time around.
Major thanks to @JovanPop_MSFT for his help with performance testing suggestions.
Performance testing is hard
Before I dive into the performance tests, I want to be clear that these tests are still not perfect.
Performance testing in SQL Server is hard enough. When you start trying to compare SQL Server functions to code in .NET, lots of of other factors come in to play.
I'll try to to highlight where there still might be some problems with my methodology in the tests below, but overall I think these tests are more accurate comparisons of these features.
SQL Server JSON vs. Json.Net
There are two major issues with comparing SQL Server JSON functions to Json.NET functions in C#:
- Queries running in SQL Server Management Studio have significant overhead when rendering results to the results grid.
- The way SQL Server retrieves pages of data from disk or memory is not the same as how C# retrieves data from disk or memory.
The below tests should provide a more accurate comparison between SQL Server and .NET.
I am capturing SQL run times for the below tests using SET STATISTICS TIME ON. All of the test data for the below tests is available here: https://gist.github.com/bertwagner/f0645cf1b244af7d6bb75856db8744e0
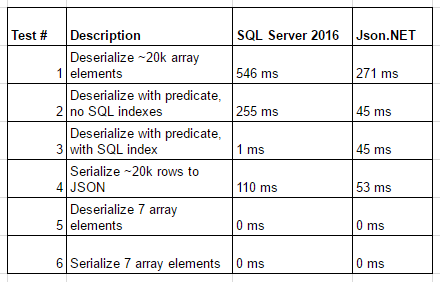
Test #1 — Deserializing 20k JSON elements
For this first test, we will deserialize ~20k rows of car year-make-model data comparing the SQL Server OPENJSON function against Json.NET's DeserializeObject.
Previously this test used JSON_VALUE which was adding unnecessary processing overhead. With the query rewritten to run more efficiently, it looks like this:
SELECT year, make, model
FROM OPENJSON(@cars) WITH (year int, make nvarchar(50), model nvarchar(50));
-- 160ms
Now the problem with this query is that we are still drawing all ~20k rows of data to the screen in SQL Server Management Studio. The best way to avoid this extra processing is to simply convert the query to use COUNT:
SELECT COUNT(*)
FROM OPENJSON(@cars) WITH (year int, make nvarchar(50), model nvarchar(50));
-- 71ms

Looking at the execution plans, the OPENJSON function is still processing all ~20k rows in both queries, only the number of rows being brought back to the SSMS GUI differ.
This still isn't the same as what the C# test below does (all data in the C# example stays in memory at all times) but it is as close of a comparison that I could think of:
var deserializedCars = JsonConvert.DeserializeObject<IEnumerable<Car>>(carsJSON);
// 66ms
(Full C# code available at: https://gist.github.com/bertwagner/8e5e8b6ec977c1704355166f96ae3efa)
And the result of this test? SQL Server was nearly as fast as Json.NET!

Test #2 — Deserializing ~20k rows with a predicate
In this next test we filter and return only a subset of rows.
SQL:
SELECT count(*) FROM OPENJSON(@cars) WITH(model nvarchar(20) ) WHERE model = 'Golf'
// 58ms
C#
var queriedCars = JsonConvert.DeserializeObject<IEnumerable<Car>>(carsJSON).Where(x => x.Model == "Golf");
// 52ms
Result: SQL Server is nearly as fast once again!

One more important thing to note about this specific test — if you add this data into a SQL table and add a computed column index, SQL Server will beat out Json.NET every time.
Test #3 — Serializing ~20 elements into JSON
This scenario is particularly difficult to test. If I want to serialize data in a SQL table to a JSON string, how do I write the equivalent of that in C#? Do I use a DataTable and hope that SQL's data is all in cache? Is the retrieval speed between the SQL Server buffer equivalent to C#'s DataTable? Would a collection of List's in C# be more appropriate than a DataTable?
In the end, I decided to force SQL to read pages from disk by clearing the cache and have C# read the object data from a flat file. This still isn't perfect, but it is as close as I think we can get:
SQL:
DBCC DROPCLEANBUFFERS
SELECT * FROM dbo.Cars FOR JSON AUTO
-- 108ms
C#:
string carsJSONFromFile = File.ReadAllText(@"../../CarData.json");
var serializedCars = JsonConvert.SerializeObject(deserializedCars);
// 63ms
This test still isn't perfect though because SSMS is outputting the JSON string to the screen while C# never has to. I didn't want to play around with outputting the C# version to a form or the console window because it still wouldn't have been an equal comparison.
Result: Json.Net is about twice as fast although this test is by far the most inaccurate. Still, SQL is still much faster than I initially thought.
SQL Server JSON vs. XML
In my previous article comparing SQL Server JSON to SQL Server XML, I focused on tests that were all done within SQL Server.
These tests were incomplete however: most of the time, a developer's app will have to do additional processing to get data into an XML format, while JSON data usually already exists in JSON format (assuming we have Javascript web app).
These two tests examine cases where XML may have been slightly faster than JSON on SQL Server, but if you consider the entire environment (app + database), using JSON wins.
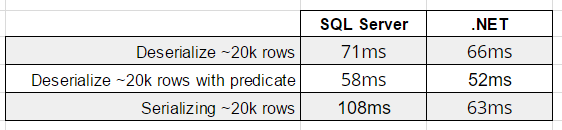
Scenario #1 — XML data needs to be serialized
Although inserting XML data that is already in memory into a SQL Server table is faster than the equivalent operation in JSON, what happens if we need to serialize the data in our app first before sending the data to SQL Server?
// Serialize Car objects to XML
var result1 = SerializeToXML(cars);
// 166ms
// Serialize Car objects to JSON
var result2 = SerializeToJSON(cars);
// 69ms
public static Tuple<long, string> SerializeToXML(List<Car> cars)
{
Stopwatch sw = new Stopwatch();
sw.Start();
StringWriter writer = new StringWriter();
XmlSerializer serializer = new XmlSerializer(typeof(List<Car>));
serializer.Serialize(writer, cars);
string result = writer.ToString();
sw.Stop();
return new Tuple<long, string>(sw.ElapsedMilliseconds, result);
}
public static Tuple<long, string> SerializeToJSON(List<Car> cars)
{
Stopwatch sw = new Stopwatch();
sw.Start();
var json = JsonConvert.SerializeObject(cars);
sw.Stop();
return new Tuple<long, string>(sw.ElapsedMilliseconds, json);
}
Using the most common libraries available to serializing data to XML and JSON, serializing data to JSON is twice as fast as serializing to XML (and as mentioned before, a lot of the time apps already have JSON data available — no need to serialize). This means the app serialization code will run faster and allow for the data to make it to SQL Server faster.
Scenario #5 — Transferring XML and JSON to SQL Server
Finally, after we have our serialized XML and JSON data in C#, how long does it take to transfer that data to SQL Server?
// Write XML string to SQL XML column
var result3 = WriteStringToSQL(
result1.Item2,
"INSERT INTO dbo.XmlVsJson (XmlData) VALUES (@carsXML)",
new SqlParameter[]
{
new SqlParameter("carsXML", result1.Item2)
});
// 142ms, 1.88mb of data
// Write JSON string to SQL
var result4 = WriteStringToSQL(
carsJSON,
"INSERT INTO dbo.XmlVsJson (JsonData) VALUES (@carsJSON)",
new SqlParameter[]
{
new SqlParameter("carsJSON", carsJSON)
});
// 20ms, 1.45mb of data
// Write XML string to nvarchar SQL column. Taking the difference between this and result3, 100ms+ of time is spent converting to XML format on insert.
var result5 = WriteStringToSQL(
result1.Item2,
"INSERT INTO dbo.XmlVsJson (JSONData) VALUES (@carsXML)",
new SqlParameter[]
{
new SqlParameter("carsXML", result1.Item2)
});
// 29ms, 1.88mb of data
Result: Writing JSON data to a nvarchar SQL Server column is much faster than writing XML data to an XML typed (or even an nvarchar typed) column.
Not only does SQL server need to parse the XML data upon insert, the physical size of the XML data being sent over TCP is larger due to the repetitive nature of XML syntax.
Conclusion
JSON performance in SQL Server is still awesome. In fact, it's even better than I had previously thought.
These tests are not meant to be conclusive; think of them more as errata for my previous JSON performance posts.
However, I think that these comparisons show that SQL Server's JSON functions are competitive with other languages' performance of handling JSON data.
Additionally, if serializing/deserializing reduces the amount of data transferred over TCP, using the JSON functions in SQL Server will most likely give you better total app/environment performance.