Watch this week's video on YouTube
The execution plan cache is a great feature: after SQL Server goes through the effort of generating a query plan, SQL Servers saves that plan in the plan cache to be reused again at a later date.
One downside to SQL Server caching almost all plans by default is that some of those plans won't ever get reused. Those single use plans will exist in the plan cache, inefficiently tying up a piece of the server's memory.
Today I want to look at a feature that will keep these one-time use plans out of the plan cache.
Plan Stubs
Instead of filling the execution plan cache with plans that will never get reused, the optimize for ad hoc workloads option will cache a plan stub instead of the full plan. The plan stub is significantly smaller in size and is only replaced with the full execution plan when SQL Server recognizes that the same query has executed multiple times.
This reduces the amount of size one-time queries take up in t he cache, allowing more reusable plans to remain in the cache for longer periods of time.
Enabling this server-level feature is as easy as (a database scoped versions :
sp_configure 'show advanced options',1
GO
reconfigure
GO
sp_configure 'optimize for ad hoc workloads',1
GO
reconfigure
go
Once enabled you can watch the plan stub take up less space in the cache:
-- Run each of these queries once
DECLARE @Username varchar = 'A'
SELECT UserName
FROM IndexDemos.dbo.[User]
WHERE UserName like @Username+'%';
GO
DECLARE @Username varchar = 'B'
SELECT UserName
FROM IndexDemos.dbo.[User]
WHERE UserName like @Username+'%';
GO
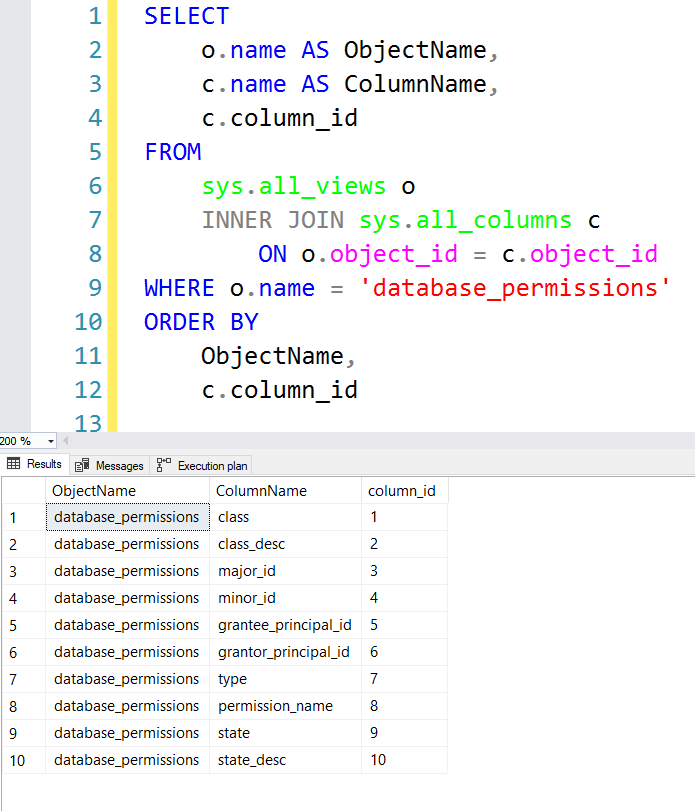
SELECT
cp.cacheobjtype,
cp.objtype,
cp.plan_handle,
cp.size_in_bytes,
qp.query_plan,
st.text
FROM
sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) qp
INNER JOIN sys.dm_exec_query_stats qs
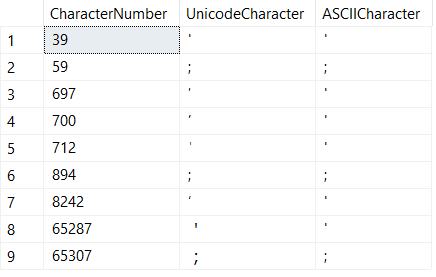
ON cp.plan_handle = qs.plan_handle
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
WHERE
st.text like 'DECLARE @Username varchar =%';

Now if we run our second query filtering on UserName LIKE 'B%' again and then check the plan cache, we'll notice the stub is replaced with an actual compiled plan:

The downside to plan stubs is that they add some cpu load to our server: each query gets compiled twice before it gets reused from cache. However, since plan stubs reduce the size of our plan cache, this allows more reusable queries to be cached for longer periods of time.
Great! All my cache problems will be solved
Not necessarily.
If your workload truly involves lots of ad hoc queries (like many analysts all working on different problems or dynamic SQL that's generating completely different statements on every execution), enabling Optimize for Ad hoc Workloads may be your best option (Kimberly Tripp also has a great alternative: clearing single use plans automatically on a schedule).
However, often times single-use query plans have a more nefarious origin: unparameterized queries. In this case, enabling Optimize for Ad hoc Workloads may not negatively impact your server, but it certainly won't help. Why? Because those original queries will still be getting generated.
Brent Ozar has a good overview of why this happens, but the short answer is to force parameterization on your queries. When you enable force parameterization, SQL Server will ~~not~~ automatically parameterize your queries if they aren't already, reducing the number of one off query plans in your cache.
Whether you are dealing with too many single use queries on your server or some other problem, just remember to find the root cause of the problem instead of just treating the symptoms.
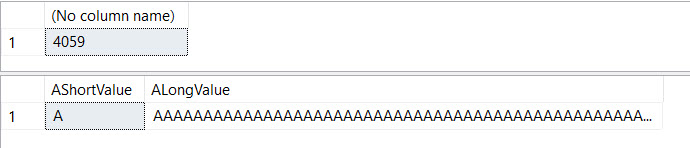 A homage to one of my favorite
A homage to one of my favorite  Need a ultra HD wide display to fit this all on one screen.
Need a ultra HD wide display to fit this all on one screen.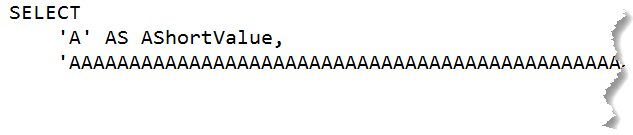
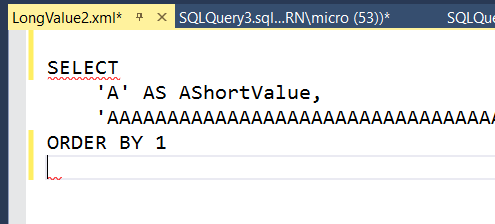 IntelliSense complains but I'm OK with it
IntelliSense complains but I'm OK with it
 FOR XML PATH is one of the most abused SQL Server functions.
FOR XML PATH is one of the most abused SQL Server functions.