Unexpected SQL Server Performance Killers #3

Watch this week's video on YouTube
In this series I explore scenarios that hurt SQL Server performance and show you how to avoid them. Pulled from my collection of "things I didn't know I was doing wrong for years."
Looking for a script to find non-SARGable queries on your server? Scroll to the bottom of this post.
What is a "SARGable" query?
Just because you add an index to your table doesn't mean you get immediate performance improvement. A query running against that table needs to be written in such a way that it actually takes advantage of that index.
SARGable, or "Search Argument-able", queries therefore are queries that are capable of utilizing indexes.
Examples please!
Okay let's see some examples of SARGable and non-SARGable queries using my favorite beverage data.
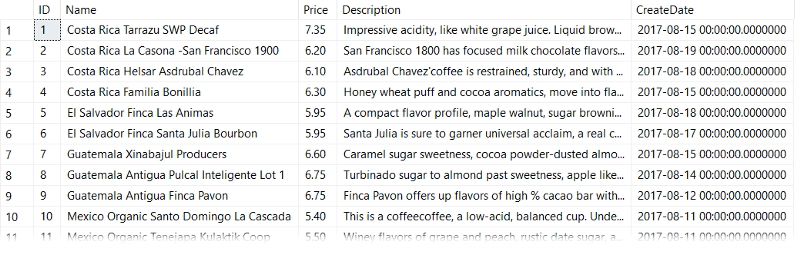
First, let's look at a non-SARGable query:
SELECT Name
FROM dbo.CoffeeInventory
WHERE CONVERT(CHAR(10),CreateDate,121) = '2017-08-19'
Although this query correctly filters our rows to a specific date, it does so with this lousy execution plan:

SQL Server has to perform an Index Scan, or in other words has to check every single page of this index, to find our '2017–08–19' date value.
SQL Server does this because it can't immediately look at the value in the index and see if it is equal to the '2017–08–19' date we supplied — we told it first to convert every value in our column/index to a CHAR(10) date string so that it can be compared as a string.
Since the SQL Server has to first convert every single date in our column/index to a CHAR(10) string, that means it ends up having to read every single page of our index to do so.
The better option here would be to leave the column/index value as a datetime2 datatype and instead convert the right hand of the operand to a datetime2:
SELECT Name
FROM dbo.CoffeeInventory
WHERE CreateDate = CAST('2017-08-19' AS datetime2)
Alternatively, SQL Server is smart enough to do this conversion implicitly for us if we just leave our '2017–08–19' date as a string:
SELECT Name
FROM dbo.CoffeeInventory
WHERE CreateDate = '2017-08-19'

In this scenario SQL gives us an Index Seek because it doesn't have to modify any values in the column/index in order to be able to compare it to the datetime2 value that '2017–08–19' got converted to.
This means SQL only has to read what it needs to output to the results. Much more efficient.
One more example
Based on the last example we can assume that any function, explicit or implicit, that is running on the column side of an operator will result in a query that cannot make use of index seeks, making it non-SARGable.
That means that instead of doing something non-SARGable like this:
SELECT Name, CreateDate
FROM dbo.CoffeeInventory
WHERE DAY(CreateDate) = 19
We want to make it SARGable by doing this instead:
SELECT Name, CreateDate
FROM dbo.CoffeeInventory
WHERE
CreateDate >= '2017-08-19 00:00:00'
AND CreateDate < '2017-08-20 00:00:00'
In short, keep in mind whether SQL Server will have to modify the data in a column/index in order to compare it — if it does, your query probably isn't SARGable and you are going to end up scanning instead of seeking.
OK, non-SARGable queries are bad…how do I check if I have any on my server?
The script below looks at cached query plans and searches them for any table or index scans. Next, it looks for scalar operators, and if it finds any it means we have ourselves a non-SARGable query. The fix is then to rewrite the query to be SARGable or add a missing index.
-- From https://github.com/bertwagner/SQLServer/blob/master/Non-SARGable%20Execution%20Plans.sql
-- This script will check the execution plan cache for any queries that are non-SARGable.
-- It does this by finding table and index scans that contain a scalar operators
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
DECLARE @dbname SYSNAME
SET @dbname = QUOTENAME(DB_NAME());
WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
stmt.value('(@StatementText)[1]', 'varchar(max)') AS [Query],
query_plan AS [QueryPlan],
sc.value('(.//Identifier/ColumnReference/@Schema)[1]', 'varchar(128)') AS [Schema],
sc.value('(.//Identifier/ColumnReference/@Table)[1]', 'varchar(128)') AS [Table],
sc.value('(.//Identifier/ColumnReference/@Column)[1]', 'varchar(128)') AS [Column] ,
CASE WHEN s.exist('.//TableScan') = 1 THEN 'TableScan' ELSE 'IndexScan' END AS [ScanType],
sc.value('(@ScalarString)[1]', 'varchar(128)') AS [ScalarString]
FROM
sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp
CROSS APPLY query_plan.nodes('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple') AS batch(stmt)
CROSS APPLY stmt.nodes('.//RelOp[TableScan or IndexScan]') AS scan(s)
CROSS APPLY s.nodes('.//ScalarOperator') AS scalar(sc)
WHERE
s.exist('.//ScalarOperator[@ScalarString]!=""') = 1
AND sc.exist('.//Identifier/ColumnReference[@Database=sql:variable("@dbname")][@Schema!="[sys]"]') = 1
AND sc.value('(@ScalarString)[1]', 'varchar(128)') IS NOT NULL
I've found this script useful for myself, but if you find any issues with it please let me know, thanks!