
Watch this week's video on YouTube
Recently I've been working with JSON in SQL Server 2016 a lot.
One of the hesitations many people have with using JSON in SQL Server is that they think that querying it must be really slow — SQL is supposed to excel at relational data, not string parsing right?
It turns out that performance is pretty good with the standalone SQL Server JSON functions. Even better is that it's possible to make queries against JSON data run at ludicrous speeds by using indexes on JSON parsed computed columns. In this post I want to take a look at how SQL is able to parse* with such great performance.
*"Parse" here is actually a lie —it's doing something else behind the scenes. You'll see what I mean, keep reading!
Computed Columns in SQL Server
The only way to get JSON indexes working on SQL server is to use a computed column. A computed column is basically a column that performs a function to calculate its values.
For example, let's say we have a table with some car JSON data in it:
DROP TABLE IF EXISTS dbo.DealerInventory;
CREATE TABLE dbo.DealerInventory
(
Id int IDENTITY(1,1) PRIMARY KEY,
Year int,
JsonData nvarchar(300)
);
INSERT INTO dbo.DealerInventory (Year, JsonData) VALUES (2017, '{ "Make" : "Volkswagen", "Model" : "Golf" }');
INSERT INTO dbo.DealerInventory (Year, JsonData) VALUES (2017, '{ "Make" : "Honda", "Model" : "Civic" }');
INSERT INTO dbo.DealerInventory (Year, JsonData) VALUES (2017, '{ "Make" : "Subaru", "Model" : "Impreza" }');
SELECT * FROM dbo.DealerInventory;
/* Output:
Id Year JsonData
----- -------- ---------------------------------------------
1 2017 { "Make" : "Volkswagen", "Model" : "Golf" }
2 2017 { "Make" : "Honda", "Model" : "Civic" }
3 2017 { "Make" : "Subaru", "Model" : "Impreza" }
*/
We can add a new computed column to the table, "Make", which parses and extracts the Make property from each row's JSON string:
ALTER TABLE dbo.DealerInventory
ADD Make AS JSON_VALUE(JsonData, '$.Make');
SELECT * FROM dbo.DealerInventory;
/* Output:
Id Year JsonData Make
-- ----- ------------------------------------------- ----------
1 2017 { "Make" : "Volkswagen", "Model" : "Golf" } Volkswagen
2 2017 { "Make" : "Honda", "Model" : "Civic" } Honda
3 2017 { "Make" : "Subaru", "Model" : "Impreza" } Subaru
*/
By default, the above Make computed column is non-persisted, meaning its values are never stored to the database (persisted computed columns can also be created, but that's a topic for a different time). Instead, every time a query runs against our dbo.DealerInventory table, SQL Server will calculate the value for each row.
The performance of this isn't great — it's essentially a scalar function running for each row of our output :(. However, when you combine a computed column with an index, something interesting happens.
Time to dive in with DBCC Page
DBCC Page is an undocumented SQL Server function that shows what the raw data stored in a SQL page file looks like. Page files are how SQL Server stores its data.
In the rest of this post we'll be looking at how data pages (where the actual table data in SQL is stored) and index pages (where our index data is stored) are affected by non-persisted computed columns — and how they make JSON querying super fast.
First, let's take a look at the existing data we have. We do this by first turning on trace flag 3604 and using DBCC IND to get the page ids of our data. Additional details on the column definitions in DBCC IND and DBCC PAGE can be found in Paul Randal's blog post on the topic.
DBCC TRACEON(3604);
-- "Sandbox" is the name of my database
DBCC IND('Sandbox','dbo.DealerInventory',-1);

If you look at the results above, row 2 contains our data page (indicated by PageType = 1) and the PagePID of that page is 305088 (if you are playing along at home, your PagePID is most likely something else). If we then look up that PagePID using DBCC PAGE we get something like this:
DBCC PAGE('Sandbox',1,305088,3) WITH TABLERESULTS
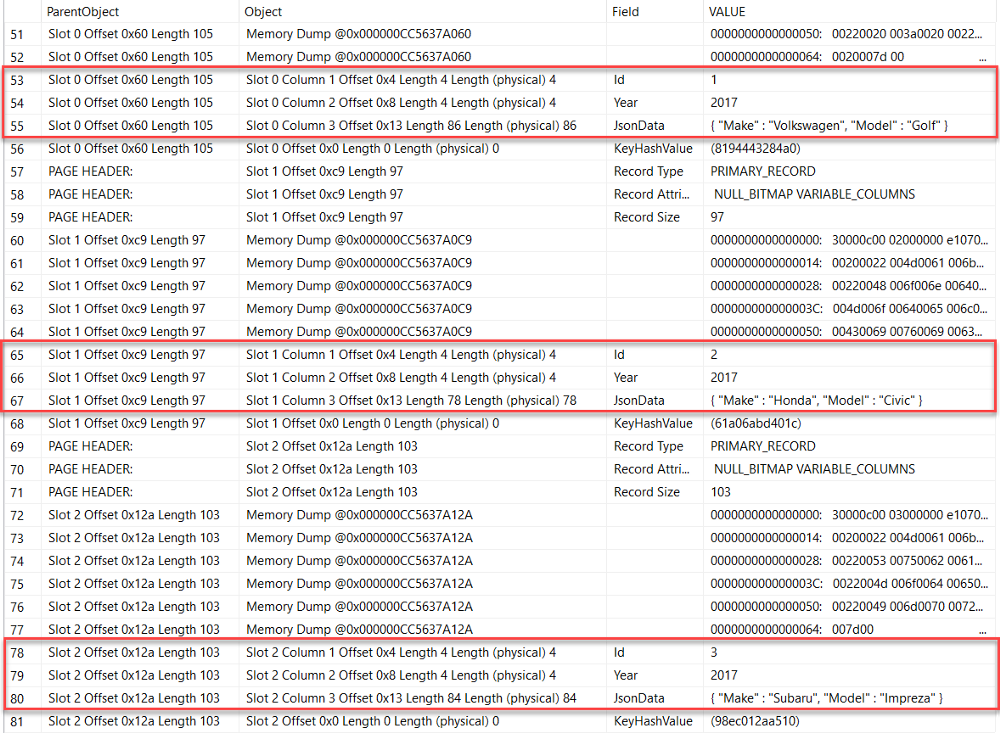
You can see our three rows of data highlighted in red. The important thing to note here is that our computed column of the parsed "Make" value is truly non-persisted and no where to be found, meaning it has to get generated for every row during query execution.
Now, what if we add an index to our non-persisted computed column and then run DBCC IND again:
CREATE NONCLUSTERED INDEX IX_ParsedMake ON dbo.DealerInventory (Make)
DBCC IND('Sandbox','dbo.DealerInventory',-1);

You'll now notice that in addition to data page 305088 (PageType = 1), we also have an index page 305096 (PageType = 2). If we examine both the data page and the index page we see something interesting:
DBCC PAGE('Sandbox',1,305088,3) WITH TABLERESULTS
DBCC PAGE('Sandbox',1,305096,3) WITH TABLERESULTS
Nothing has changed with our data page:
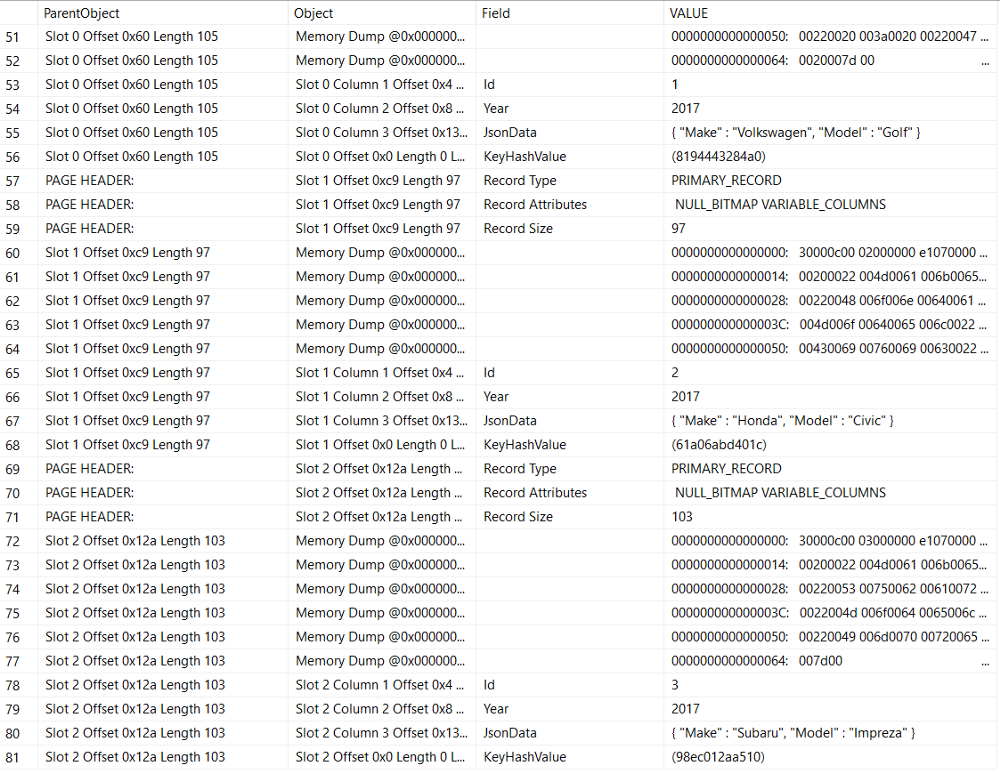
But our index page contains the parsed values for our "Make" column:

What does this mean? I thought non-persisted computed columns aren't saved to disk!
Exactly right: our non-persisted computed column "Make" isn't saved to the data page on the disk. However if we create an index on our non-persisted computed column, the computed value is persisted on the index page!
This is basically a cheat code for indexing computed columns.
SQL will only compute the "Make" value on a row's insert or update into the table (or during the initial index creation) — all future retrievals of our computed column will come from the pre-computed index page.
This is how SQL is able to parse indexed JSON properties so fast; instead of needing to do a table scan and parsing the JSON data for each row of our table, SQL Server can go look up the pre-parsed values in the index and return the correct data incredibly fast.
Personally, I think this makes JSON that much easier (and practical) to use in SQL Server 2016. Even though we are storing large JSON strings in our database, we can still index individual properties and return results incredibly fast.