This post is a response to this month's T-SQL Tuesday #104 prompt by me! T-SQL Tuesday is a way for SQL Server bloggers to share ideas about different database and professional topics every month.
This month's topic is asking what code would you hate to live without?
Watch this week's video on YouTube
When given the choice between working on new projects versus maintaining old ones, I'm always more excited to work on something new.
That means that when I build something that is going to used for years to come, I try to build it so that it will require as little maintenance as possible in the future.
One technique I use for minimizing maintenance is making my queries dynamic. Dynamic queries, while not right for every situation, do one thing really well: they allow you to modify functionality without needing a complete rewrite when your data changes. The way I look it, it's much easier to add rules and logic to rows in table than having to modify a table's columns or structure.
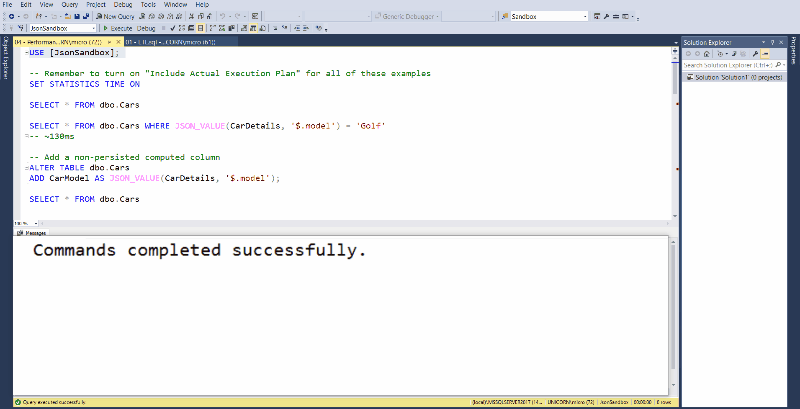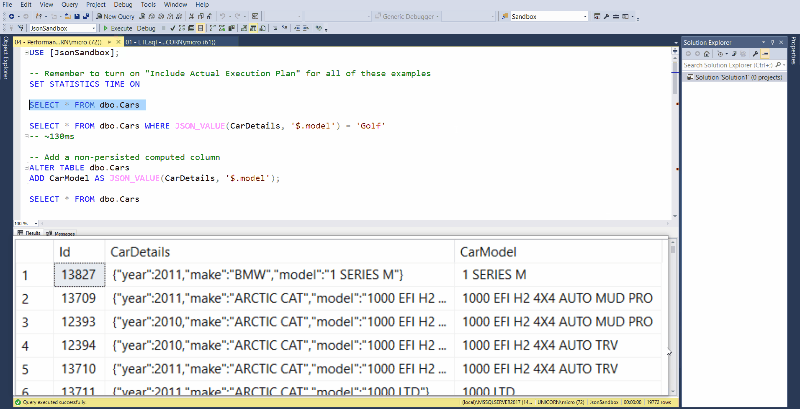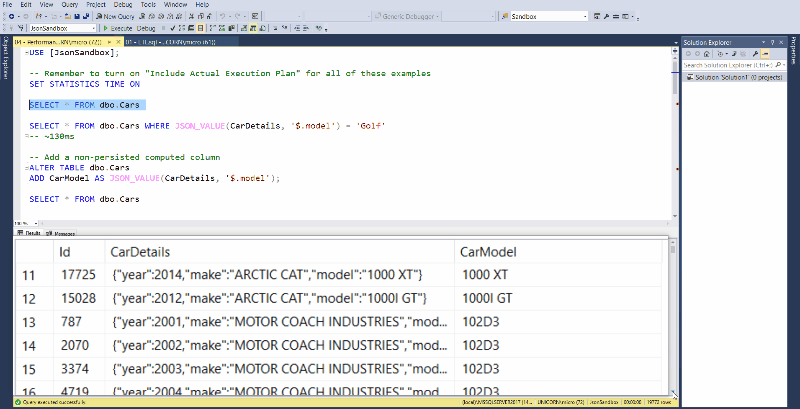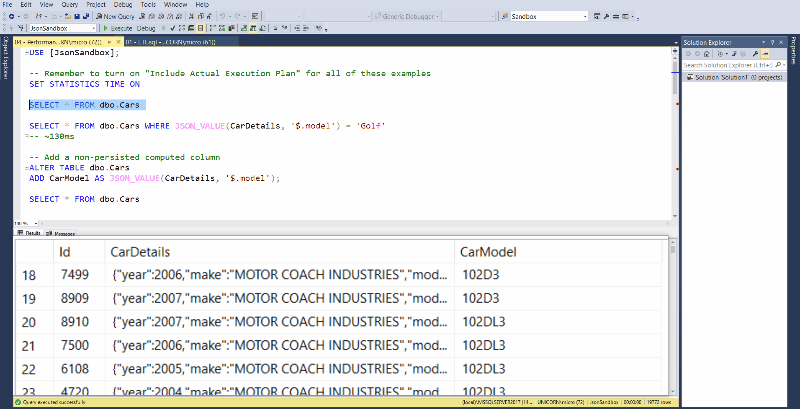
To show you what I mean,let's say I want to write a query selecting data from model.sys.database_permissions:
SELECT class
,class_desc
,major_id
,minor_id
,grantee_principal_id
,grantor_principal_id
,type
,permission_name
,state
,state_desc
FROM model.sys.database_permissions
Writing the query as above is pretty simple, but it isn't flexible in case the table structure changes in the future or if we want to programmatically write some conditions.
Instead of hardcoding the query as above, here is a general pattern I use for writing dynamic table-driven queries. SQL Server has the handy views sys.all_views and sys.all_columns that show information about what columns are stored in each table/view:
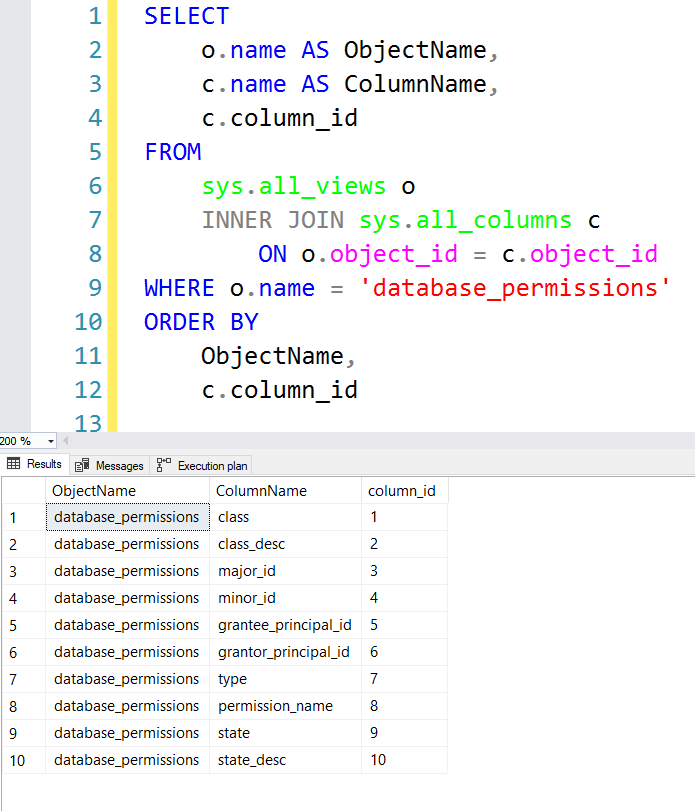
Using these two views, I can use this dynamic SQL pattern to build the same exact query as above:
-- Declare some variables up front
DECLARE
@FullQuery nvarchar(max),
@Columns nvarchar(max),
@ObjectName nvarchar(128)
-- Build our SELECT statment and schema+table name
SELECT
@Columns = COALESCE(@Columns + ', ', '') + '[' + c.[name] + ']',
@ObjectName = QUOTENAME(s.name) + '.' + QUOTENAME(o.name)
FROM
sys.all_views o
INNER JOIN sys.schemas s
ON o.schema_id = s.schema_id
INNER JOIN sys.all_columns c
ON o.object_id = c.object_id
WHERE
o.[name] = 'database_permissions'
ORDER BY
c.column_id
-- Put all of the pieces together an execute
SET @FullQuery = 'SELECT ' + @Columns + ' FROM ' + @ObjectName
EXEC(@FullQuery)
The way building a dynamic statement like this works is that I build my SELECT statement as a string based on the values stored in my all_columns view. If a column is ever added to this view, my dynamic code will handle it (I wouldn't expect this view to change that much in future versions of SQL, but in other real-world tables I can regularly expect changing data).
Yes, writing certain queries dynamically like this means more up front work. It also means some queries won't run to their full potential (not necessarily reusing plans, not tuning every individual query, needing to be thoughtful about SQL injection attacks, etc...). There are A LOT of downsides to building queries dynamically like this.
But dynamically built queries make my systems flexible and drastically reduce the amount of work I have to do down the road. In the next few weeks I hope to go into this type of dynamically built, table-driven process in more detail (so you should see the pattern in the example above get reused soon!).



 Look at those beautifully zoomed in results!
Look at those beautifully zoomed in results!