Watch this week's video on YouTube
WITH SCHEMABINDING optimizations were added all the way back in SQL Server 2005. So why bother talking about them in 2018?
Because no one is taking advantage of them!
Ok, maybe that's a little unfair. I'm sure some people advantage of the optimizations, but most code I see posted online that could benefit doesn't include it. So let's talk about an easy way for some of our non-data-accessing scalar functions to get a performance boost.
WITH SCHEMABINDING
When you create a function or view, you can add the WITH SCHEMABINDING option to prevent any database objects that the view/function uses from being modified. This is a pretty cool feature which prevents you from making a table or column change that would cause a view/function to break.
And while that's pretty cool functionality on its own, what's even better is that the SQL Server optimizer can do some pretty cool things when it knows one of your non-data accessing scalar functions is schema bound.
For example, let's say we have these two functions. You'll notice the second one includes the WITH SCHEMABINDING syntax:
DROP FUNCTION IF EXISTS dbo.UDF_RemoveSpaces_NotSchemaBound;
GO
CREATE FUNCTION dbo.UDF_RemoveSpaces_NotSchemaBound(@input VARCHAR(100))
RETURNS VARCHAR(100)
BEGIN
RETURN REPLACE(@input,' ','')
END;
GO
DROP FUNCTION IF EXISTS dbo.UDF_RemoveSpaces_SchemaBound;
GO
CREATE FUNCTION dbo.UDF_RemoveSpaces_SchemaBound(@input VARCHAR(100))
RETURNS VARCHAR(100) WITH SCHEMABINDING
BEGIN
RETURN REPLACE(@input,' ','')
END;
GO
When SQL Server executes a function, by default it checks whether the function has any database objects it needs to access. For our example functions above, this is a waste of time since neither function accesses any data.
The WITH SCHEMABINDING option forces SQL Server to take note at function creation time whether any data access is occurring. This allows SQL Server to skip that check at run time and allowing the function to execute significantly faster:
SET STATISTICS IO, TIME ON;
SELECT dbo.UDF_RemoveSpaces_NotSchemaBound('Oh yeah') AS CleanValue
INTO #Temp1
FROM
(SELECT * FROM master..spt_values WHERE number < 500) t1
CROSS JOIN (SELECT * FROM master..spt_values WHERE number < 500) t2;
/*
SQL Server Execution Times:
CPU time = 1594 ms, elapsed time = 1977 ms.
*/
SELECT dbo.UDF_RemoveSpaces_SchemaBound('Oh yeah') AS CleanValue
INTO #Temp2
FROM
(SELECT * FROM master..spt_values WHERE number < 500) t1
CROSS JOIN (SELECT * FROM master..spt_values WHERE number < 500) t2;
/*
SQL Server Execution Times:
CPU time = 62 ms, elapsed time = 59 ms.
*/
Take a look at those CPU times: 1594ms vs 62ms! Since SQL Server saves a LOT of time by not having to verify the underlying data sources (for a more in-depth explanation of how SQL Server checks whether a function accesses data, I highly recommend reading this StackOverflow answer by Paul White).
WITH SCHEMABDINING also has performance optimization for queries that would normally need to implement Halloween Protection as well. Halloween Protection essentially prevents SQL Server from modifying the same records more than once and usually implemented by the addition of an spool operator to the execution plan:
UPDATE #Temp1 SET CleanValue = dbo.UDF_RemoveSpaces_NotSchemaBound('Oh yeah');
UPDATE #Temp2 SET CleanValue = dbo.UDF_RemoveSpaces_SchemaBound('Oh yeah');

In this example, you'll notice our non-schema-bound function introduces a Table Spool while our second schema-bound function forgoes this addition since SQL Server knows there won't be any potential for conflict.
In conclusion, if you have a non-data-accessing scalar function you should always add WITH SCHEMABINDING to reap the benefits of SQL Server's optimizations when available.
 Imagine a stack of loose leaf pages. This collection of pages is our table.
Imagine a stack of loose leaf pages. This collection of pages is our table. To make searching through our pages easier, we sort all of the pages by bird name and glue on a binding. This book binding now keeps all of our pages in alphabetical order by bird name.
To make searching through our pages easier, we sort all of the pages by bird name and glue on a binding. This book binding now keeps all of our pages in alphabetical order by bird name. Let's say we want a lighter-weight version of our book that contains the most relevant information (bird name, color, description).
Let's say we want a lighter-weight version of our book that contains the most relevant information (bird name, color, description).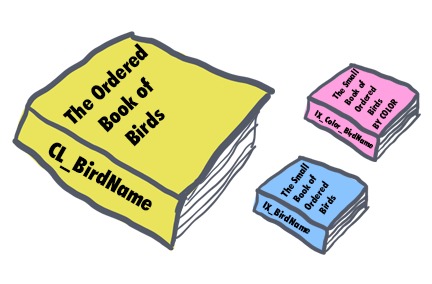 Instead of having a nonclustered index sorted by bird name, what we really need is a way to filter down to the list of potential birds quickly.
Instead of having a nonclustered index sorted by bird name, what we really need is a way to filter down to the list of potential birds quickly. I wish all of my execution plans were this simple.
I wish all of my execution plans were this simple. This execution plan looks the same, but you'll notice the smaller, more data dense index is being used.
This execution plan looks the same, but you'll notice the smaller, more data dense index is being used.