Watch this week's video on YouTube
Have you ever needed to look at what data in a table used to look like?
If you have, it probably took a knuckle-cracking filled session of writing group-by statements, nested sub-queries, and window functions to write your time-travelling query.
Sorry for your lost day of productivity — I've been there too.
Fortunately for us, SQL Server 2016 introduces a new feature to make our point-in-time analysis queries easy to write: temporal tables.
Temporal Tables? Are Those The Same As Temporary Tables?
Don't let the similar sounding name fool you: "temporal" <> "temporary".
Temporal tables consist of two parts:
- The temporal table — this is the table that contains the current values of your data.
- The historical table — this table holds all of the previous values that at some point existed in your temporal table.
You might have created a similar setup yourself in previous versions of SQL using triggers. However, using a temporal table is different from this because:
- You don't need to write any triggers/stored procedures! All of the history tracking is done automatically by SQL Server.
- Retrieving the data uses a simple WHERE clause — no complex querying required.
I want to make my life easier by using temporal tables! Take my money and show me how!
I'm flattered by your offer, but since we are good friends I'll let you in on these secrets for free.
First let's create a temporal table. I'm thinking about starting up a car rental business, so let's model it after that:
IF OBJECT_ID('dbo.CarInventory', 'U') IS NOT NULL
BEGIN
-- When deleting a temporal table, we need to first turn versioning off
ALTER TABLE [dbo].[CarInventory] SET ( SYSTEM_VERSIONING = OFF )
DROP TABLE dbo.CarInventory
DROP TABLE dbo.CarInventoryHistory
END
CREATE TABLE CarInventory
(
CarId INT IDENTITY PRIMARY KEY,
Year INT,
Make VARCHAR(40),
Model VARCHAR(40),
Color varchar(10),
Mileage INT,
InLot BIT NOT NULL DEFAULT 1,
SysStartTime datetime2 GENERATED ALWAYS AS ROW START NOT NULL,
SysEndTime datetime2 GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME (SysStartTime, SysEndTime)
)
WITH
(
SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.CarInventoryHistory)
)
The key things to note with our new table above are that
- it contains a
PRIMARY KEY. - it contains two
datetime2fields, marked withGENERATED ALWAYS AS ROW START/END. - It contains the
PERIOD FOR SYSTEM_TIMEstatement. - It contains the
SYSTEM_VERSIONING = ONproperty with the (optional) historical table name (dbo.CarInventoryHistory).
If we query our newly created tables, you'll notice our column layouts are identical:
SELECT * FROM dbo.CarInventory
SELECT * FROM dbo.CarInventoryHistory
Let's fill it with the choice car of car rental agencies all across the U.S. — the Chevy Malibu:
INSERT INTO dbo.CarInventory (Year,Make,Model,Color,Mileage) VALUES(2017,'Chevy','Malibu','Black',0)
INSERT INTO dbo.CarInventory (Year,Make,Model,Color,Mileage) VALUES(2017,'Chevy','Malibu','Silver',0)
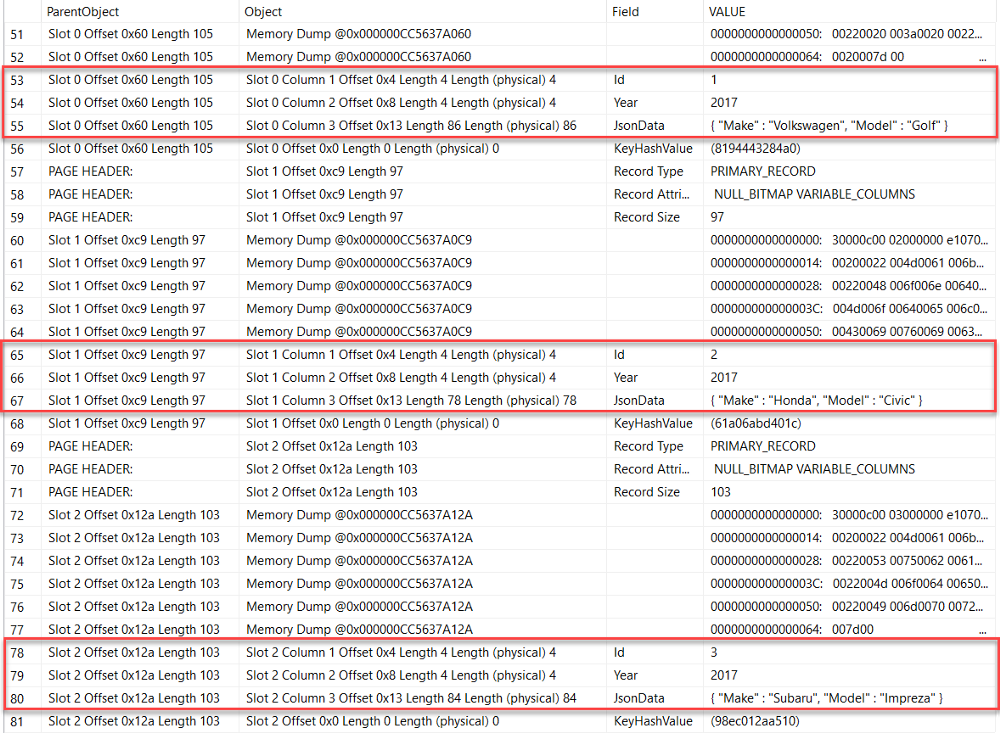
In all of the remaining screen shots, the top result is our temporal table dbo.CarInventory and the bottom result is our historical table dbo.CarInventoryHistory.
You'll notice that since we've only inserted one row for each our cars, there's no row history yet and therefore our historical table is empty.
Let's change that by getting some customers and renting out our cars!
UPDATE dbo.CarInventory SET InLot = 0 WHERE CarId = 1
UPDATE dbo.CarInventory SET InLot = 0 WHERE CarId = 2
Now we see our temporal table at work: we updated the rows in dbo.CarInventory and our historical table was automatically updated with our original values as well as timestamps for how long those rows existed in our table.
After a while, our customers return their rental cars:
UPDATE dbo.CarInventory SET InLot = 1, Mileage = 73 WHERE CarId = 1
UPDATE dbo.CarInventory SET InLot = 1, Mileage = 488 WHERE CarId = 2
Our temporal table show the current state of our rental cars: the customers have returned the cars back to our lot and each car has accumulated some mileage.
Our historical table meanwhile got a copy of the rows from our temporal table right before our last UPDATE statement. It's automatically keeping track of all of this history for us!
Continuing on, business is going well at the car rental agency. We get another customer to rent our silver Malibu:
UPDATE dbo.CarInventory SET InLot = 0 WHERE CarId = 2
Unfortunately, our second customer gets into a crash and destroys our car:
DELETE FROM dbo.CarInventory WHERE CarId = 2
With the deletion of our silver Malibu, our test data is complete.
Now that we have all of this great historically tracked data, how can we query it?
If we want to reminisce about better times when both cars were damage free and we were making money, we can write a query using SYSTEM_TIME AS OF to show us what our table looked like at that point in the past:
SELECT
*
FROM
dbo.CarInventory
FOR SYSTEM_TIME AS OF '2017-05-18 23:49:50'
And if we want to do some more detailed analysis, like what rows have been deleted, we can query both temporal and historical tables normally as well:
-- Find the CarIds of cars that have been wrecked and deleted
SELECT DISTINCT
h.CarId AS DeletedCarId
FROM
dbo.CarInventory t
RIGHT JOIN dbo.CarInventoryHistory h
ON t.CarId = h.CarId
WHERE
t.CarId IS NULL
C̶o̶l̶l̶i̶s̶i̶o̶n̶ Conclusion
Even with my car rental business not working out, at least we were able to see how SQL Server's temporal tables helped us keep track of our car inventory data.
I hope you got as excited as I did the first time I saw temporal tables in action, especially when it comes to querying with FOR SYSTEM_TIME AS OF. Long gone are the days of needing complicated queries to rebuild data for a certain point in time.