Watch this week's video on YouTube
While the text of this post contains good information on SSMS object filters, I highly recommend watching this week's video on YouTube - I stretched my creativity with filming this week while I was on vacation.
This week I'm sharing a trick I learned at Jess Pomfret's Ohio North SQL Server User Group presentation on data compression. Her presentation on data compression was awesome (check it out if you get the chance), but I was shocked that I have been working with SSMS for so many years and have never known about the following trick I watched her perform in her demos.
An "Organized" Nightmare
I'm guessing you've probably worked in a database that has hundreds or thousands of database objects:
I often come across this in applications where for one reason or another someone decides that there is no need to separate apps into different databases; why bother creating different databases when you can have lots of different schemas to organize your objects instead!? (*cough* vendor applications *cough*).
The problem with these enormous lists of tables, procedures, functions, etc... is that it can get pretty tiring to scroll through them to find what you need.
For years I wore down my mouse's scroll wheel, scrolling between thousands of objects across multiple server instances. As it turns out, SSMS has a much better feature for handling this problem.
Filtering Objects in SSMS
You can apply filters to most objects in SSMS by right clicking and choosing "Filter Settings":
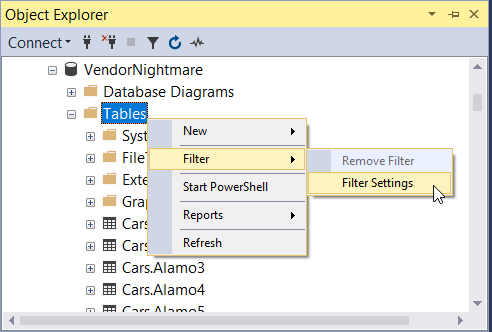
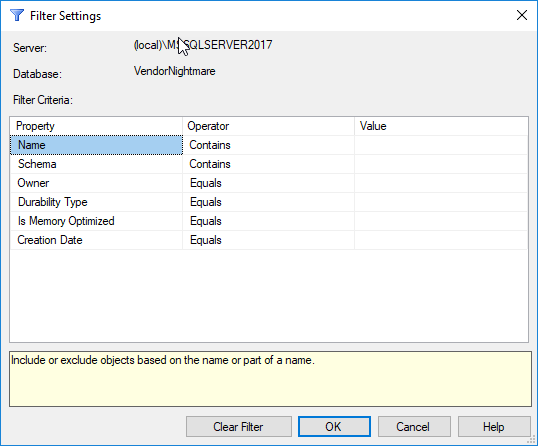
You can filter on attributes such as name, schema, create date, etc...:
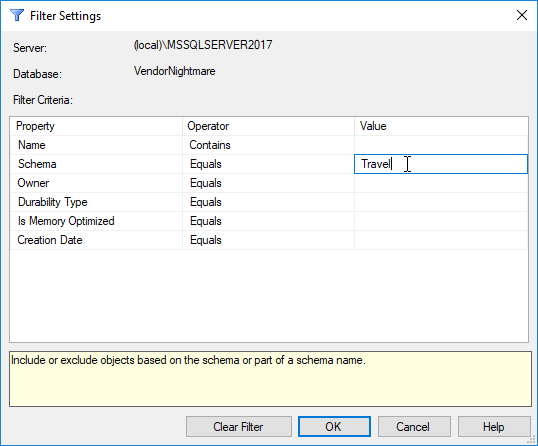
For example, if I want to see only tables that are in the Travel schema, all I have to do is create a filter:
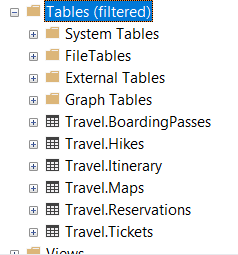
SSMS will even tell me that my list of objects is filtered so I don't go crazy later on wondering where all of my other tables went.
Limitations
There are a few limitations with using SSMS object filters though.
For example, the different filter attributes work together as if they had "AND" operators between them, so you can do something like filter on tables in the Travel schema that contain the letter "a":
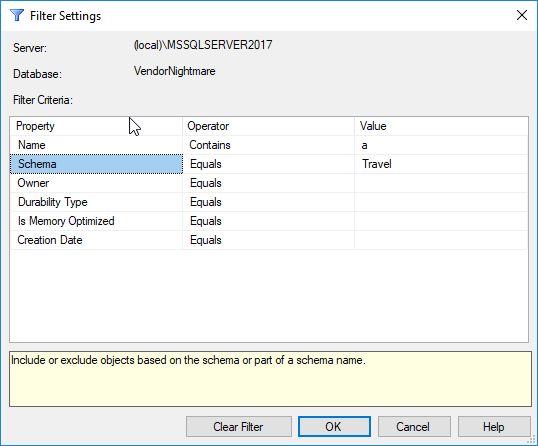
However, there is no way to write multiple conditions with OR logic (eg. you can't filter on the schemas "Travel" OR "Lodging").
And while SSMS will indicate that your objects are filtered, it won't persist that filter after restarting SSMS.
Even with those drawbacks, I've used this filtering feature at least once per week since learning about it; it saves a lot of time and I can't believe I went so long without knowing about it.