Watch this week's video on YouTube
When building indexes for your queries, the order of your index key columns matters. SQL Server can make the most effective use of an index if the data in that index is stored in the same order as what your query requires for a join, where predicate, grouping, or order by clause.
But if your query requires multiple key columns because of multiple predicates (eg. WHERE Color = 'Red' AND Size= 'Medium'), what order should you define the columns in your index key column definition?
Cardinality
In SQL Server,
cardinality refers to the number of distinct elements in a column. All other considerations aside, when you are
defining the key columns for your index, the column with the highest
cardinality, or most distinct number of values, should go first.
To understand why, let's go back to our
example columns of Color and Size. If we
have a table of data indicating the colors and sizes of various birds, it may
look something like this:

If we were to count
the number of distinct values in each of our Color and Size columns, we would
find out we have 20 distinct colors, but only 5 distinct sizes:
SELECT
COUNT(DISTINCT Color) AS DistinctColors,
COUNT(DISTINCT Size) AS DistinctSizes
FROM
dbo.Birds
(to make things
easier for this example, the data in this table is perfectly evenly distributed
across all 20 colors and 5 sizes – meaning each color is represented by one of
each of the five sizes, making for a total of 100 rows)
If we were to put Size as our leading index key column, SQL Server would immediately be able to narrow down the amount of rows it has to search to match our predicate (WHERE Color = 'Red' and Size = 'Medium') to 20 rows – after all, we can eliminate all rows where the sizes are not equal to Medium:
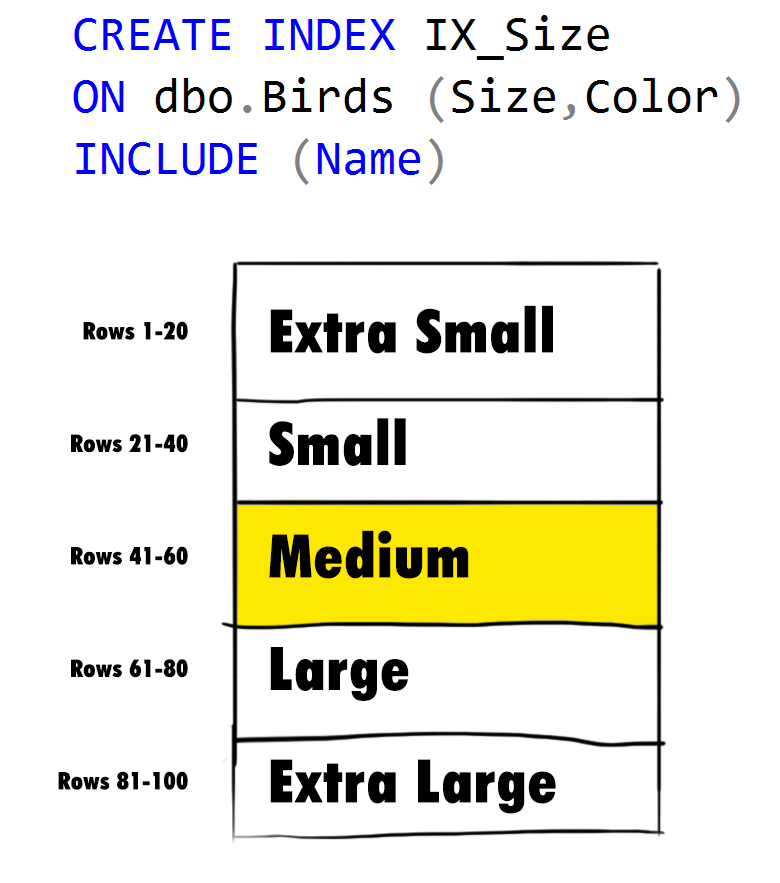
However, if we instead put Color as our first column, we can immediately eliminate 95% of the possibilities in our data set – only 5 rows with a value of 'Red' remain, one for each of our 5 distinct sizes (remember the data is perfectly distributed):
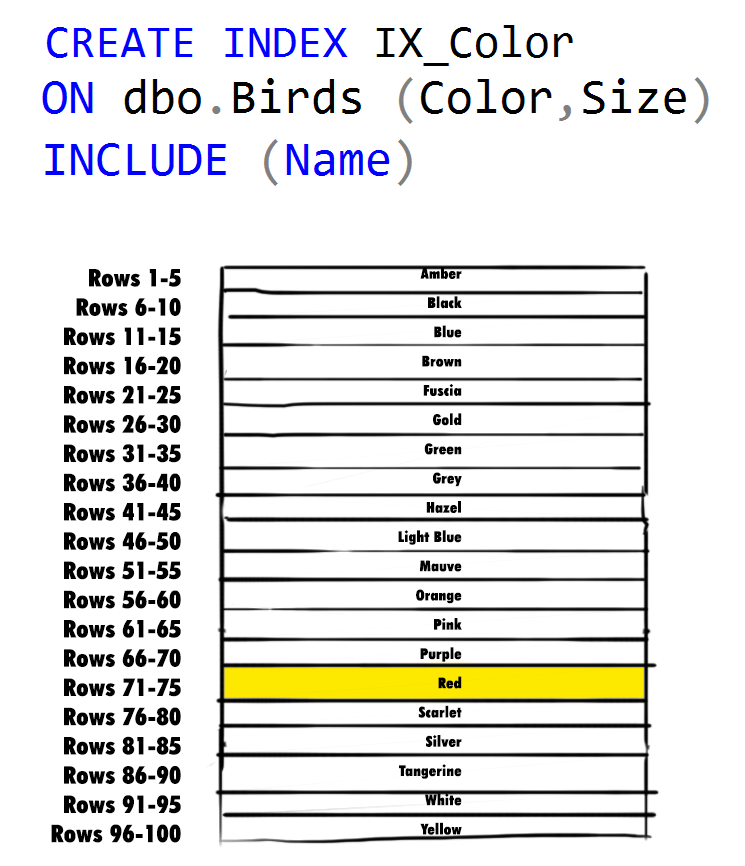
In most scenarios, putting the column with the highest cardinality first will allow SQL Server to filter out most of the data it knows it doesn't need, allowing it to focus on a smaller subset of data that it does still need to compare.
There are instances where you might want to deviate from this general rule though, like when you are trying to maximize an index's use by multiple queries; sometimes it might make sense to not put the columns in highest cardinality order if it means more queries are going to be able to make use of a single index.


 This post is a response to this month's
This post is a response to this month's