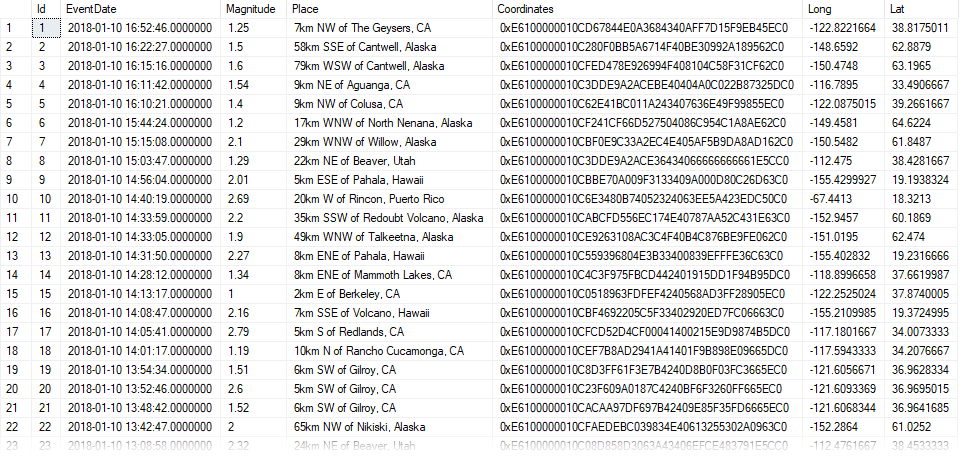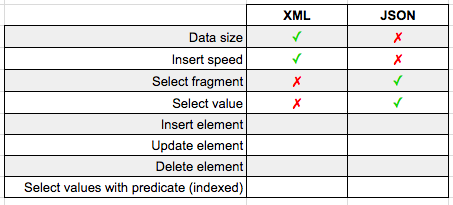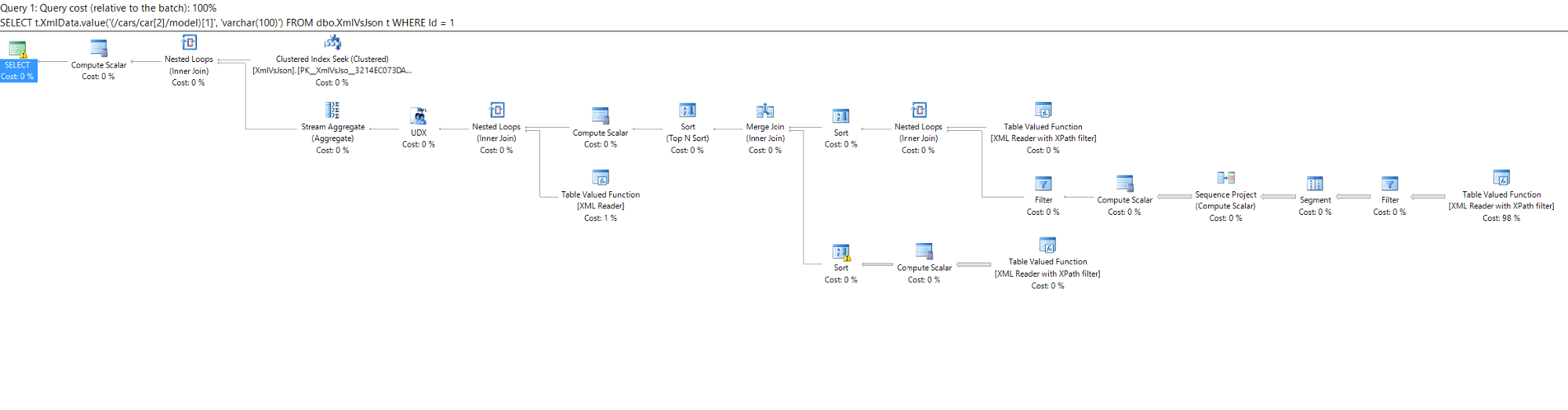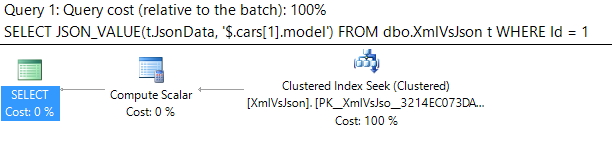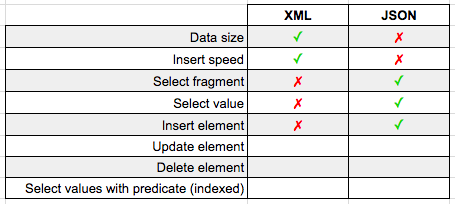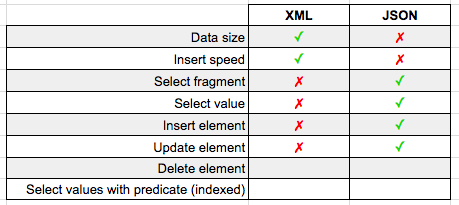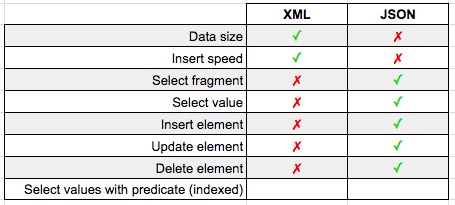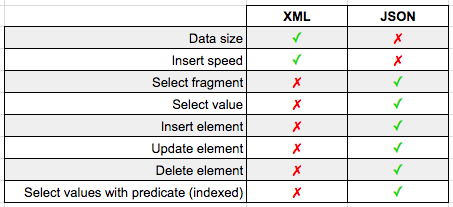
Last week we looked at how easy it is to import GeoJSON data into SQL Server's geography datatype.
Sometimes your source data won't be perfectly formatted for SQL Server's spatial datatypes though.
Today we'll examine what to do when our geographical polygon is showing us inverted results.
Watch this week's video on YouTube
Colorado Is A Rectangle
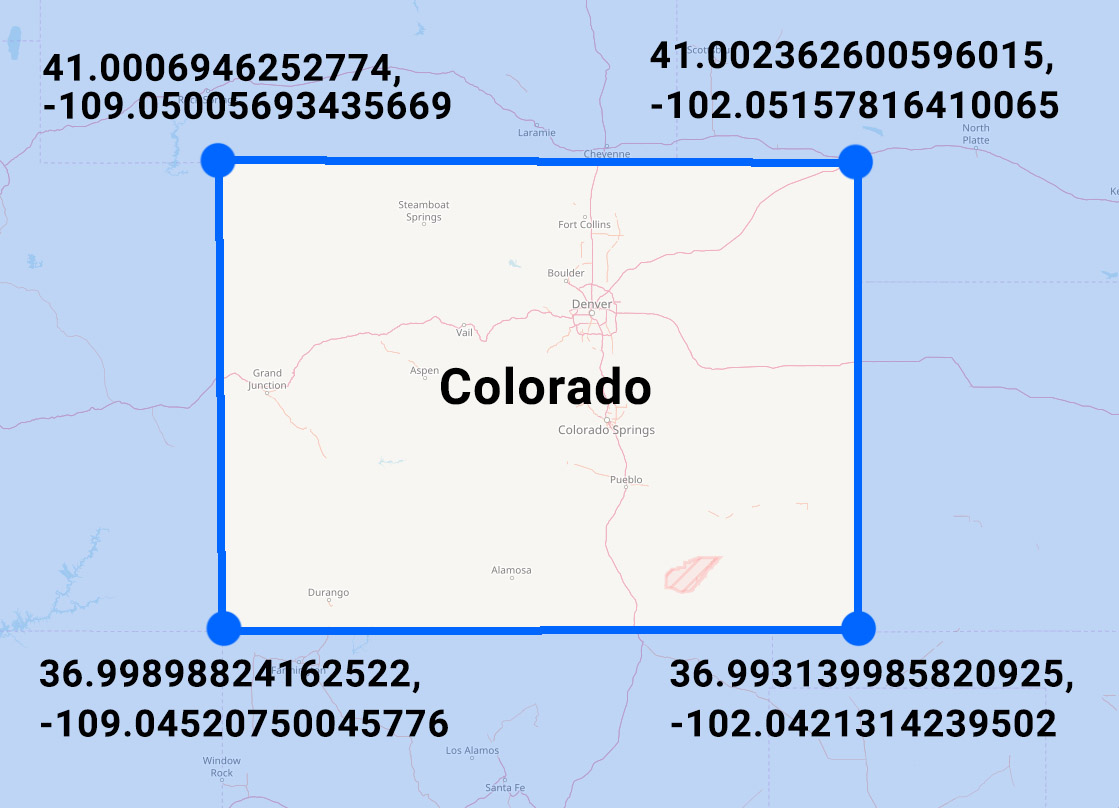
If you look at the state of Colorado on a map, you'll notice its border is pretty much a rectangle.
Roughly marking the lat/long coordinates of the state's four corners will give you a polygon comprised of the following points:
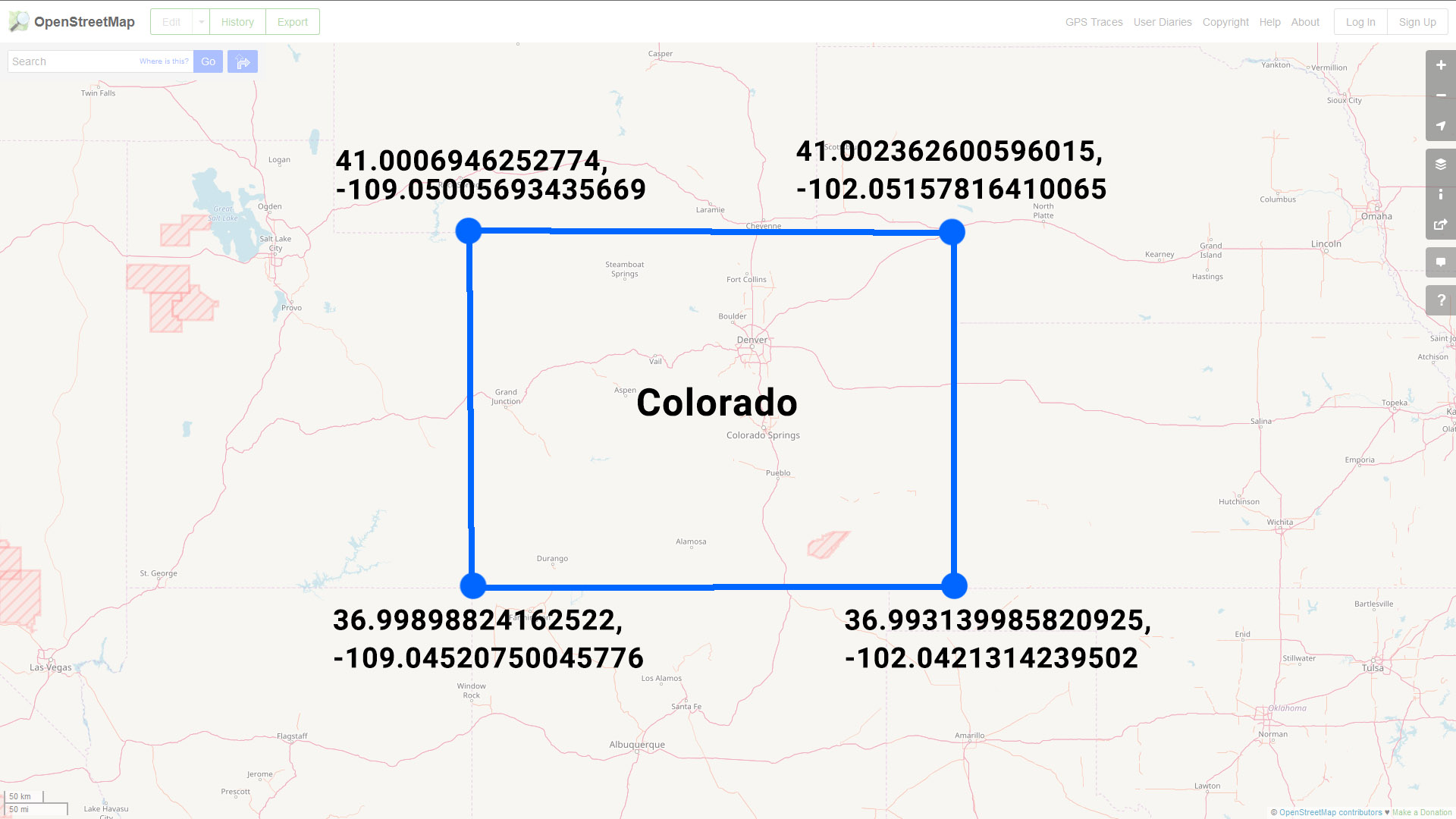
Or in GeoJSON format (set equal to a SQL variable) you might represent this data like so:
DECLARE @Colorado nvarchar(max) = N'
{
"type": "FeatureCollection",
"features": [{
"type": "Feature",
"properties": {},
"geometry": {
"type": "Polygon",
"coordinates": [
[
[-109.05005693435669,
41.0006946252774
],
[-102.05157816410065,
41.002362600596015
],
[-102.0421314239502,
36.993139985820925
],
[-109.04520750045776,
36.99898824162522
],
[-109.05005693435669,
41.0006946252774
]
]
]
}
}]
}
'
Note: four points + one extra point that is a repeat of our first point - this last repeated point let's us know that we have a closed polygon since it ends at the same point where it began.
Viewing Our Colorado Polygon
Converting this array of points to the SQL Server geography datatype is pretty straight forward:
SELECT
geography::STPolyFromText(
'POLYGON ((' + STRING_AGG(CAST(Long + ' ' + Lat as varchar(max)), ',') + '))'
,4326) AS StateBoundary
FROM
(
SELECT
Long,
Lat
FROM
OPENJSON(@Colorado, '$.features[0].geometry.coordinates[0]')
WITH
(
Long varchar(100) '$[0]',
Lat varchar(100) '$[1]'
)
)d
We can then take a look at SQL Server Management Studio's Spatial Results tab and see our polygon of Colorado drawn on a map. You might notice something looks a little funny with this picture though:
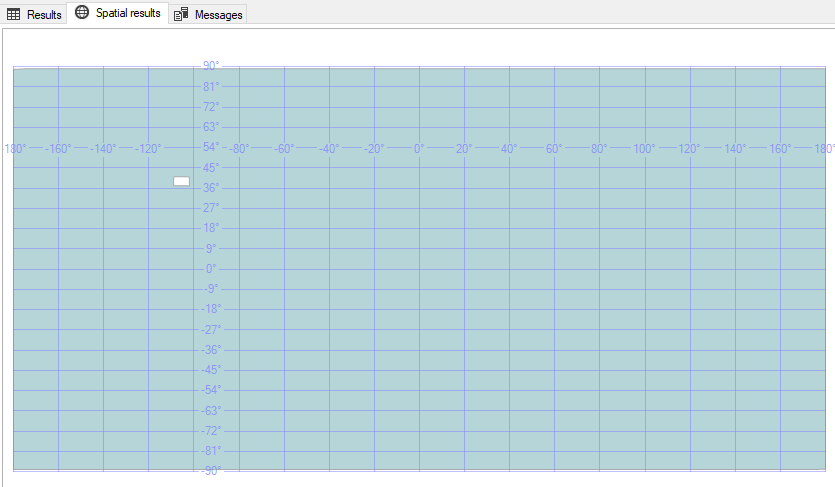
WHY IS MY POLYGON AREA INVERTED?!!??!
Discerning eyes might notice that SQL Server didn't shade in the area inside of the polygon - it instead shaded in everything in the world EXCEPT for the interior of our polygon.
If this is the first time you've encountered this behavior then you're probably confused by this behavior - I know I was.
The Left-Hand/Right-Hand Rules
There is a logical explanation though for why SQL Server is seemingly shading in the wrong part of our polygon.
SQL Server's geography datatype follows the "left-hand rule" when determining which side of the polygon should be shaded. On the contrary, the GeoJSON specification specifies objects should be formed following the "right-hand rule."
The left hand rule works like this: imagine you are walking the path of polygon - whatever is to the left of the line you are walking is what is considered the "interior" of that polygon.
So if we draw arrows that point in the direction that the coordinates are listed in our GeoJSON, you'll notice we are making our polygon in a clockwise direction:
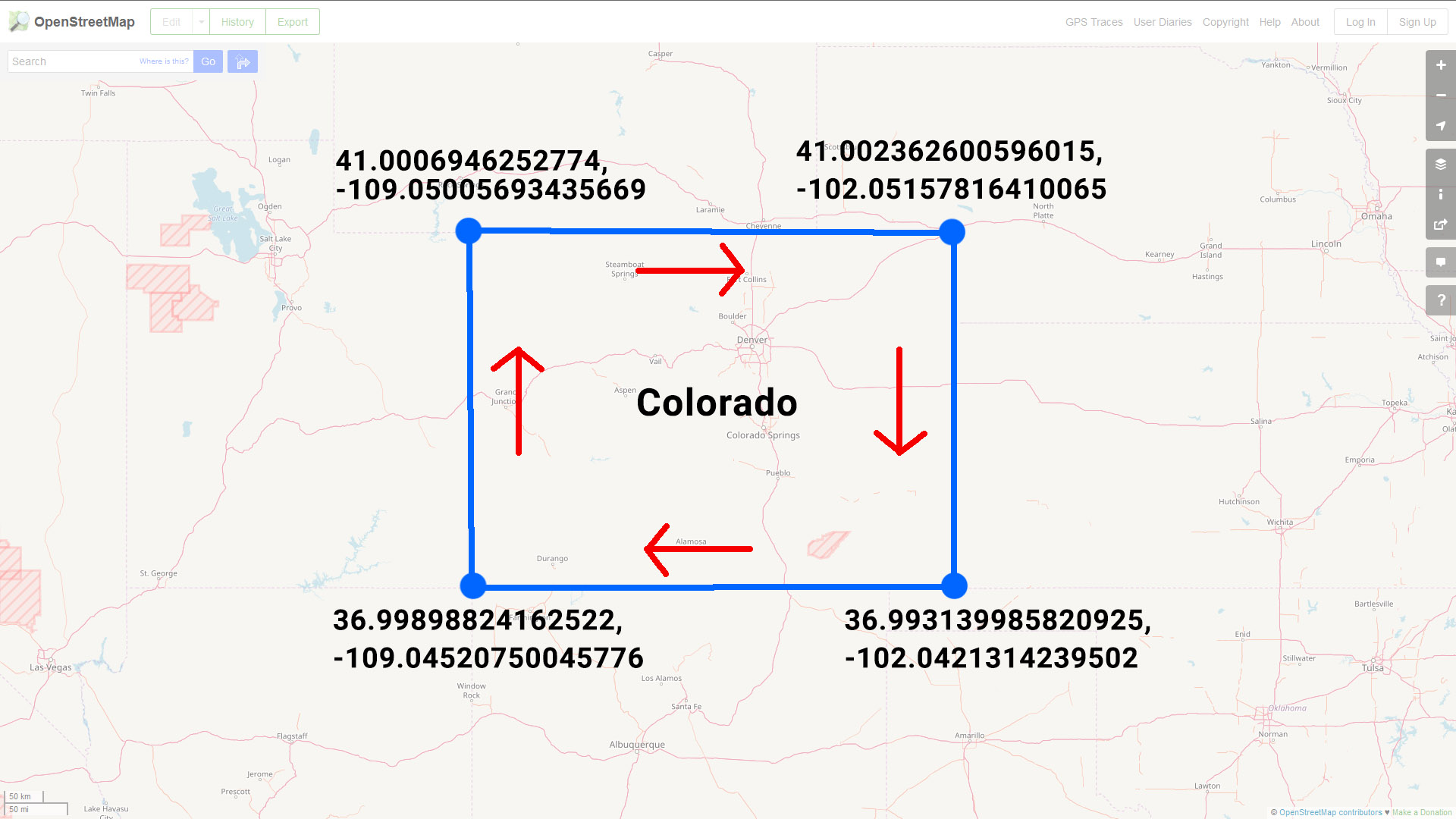
If you imagine yourself walking along this line in the direction specified, you'll quickly see why SQL Server shades the "outside" of the polygon: following the left-hand rule, everything except for the state of Colorado is considered the interior of our polygon shape.
Reversing Polygon Direction
So the problem here is that our polygon data was encoded in a different direction than the SQL Server geography datatype expects.
One way to fix this is to correct our source data by reordering the points so that the polygon is drawn in a counter-clockwise direction:
-- Note: The middle three sets of points have been included in reverse order while the first/last point have stayed the same
DECLARE @ColoradoReversed nvarchar(max) = N'
{
"type": "FeatureCollection",
"features": [{
"type": "Feature",
"properties": {},
"geometry": {
"type": "Polygon",
"coordinates": [
[
[-109.05005693435669,
41.0006946252774
],
[-109.04520750045776,
36.99898824162522
],
[-102.0421314239502,
36.993139985820925
],
[-102.05157816410065,
41.002362600596015
],
[-109.05005693435669,
41.0006946252774
]
]
]
}
}]
}
'
This is pretty easy to do with a polygon that only has five points, but this would be a huge pain for a polygon with hundreds or thousands of points.
So how do we solve this in a more efficient manner?
Easy, use SQL Server's ReorientObject() function.
SELECT
geography::STPolyFromText(
'POLYGON ((' + STRING_AGG(CAST(Long + ' ' + Lat as varchar(max)), ',') + '))'
,4326).ReorientObject() AS StateBoundary
FROM
(
SELECT
Long,
Lat
FROM
OPENJSON(@Colorado, '$.features[0].geometry.coordinates[0]')
WITH
(
Long varchar(100) '$[0]',
Lat varchar(100) '$[1]'
)
)d
ReorientObject() does what we did manually above - it manipulates the order of our polygon's points so that it changes the direction in which the polygon is drawn.
Note: SQL uses a different order when reversing the points using ReorientObject() than the way we reversed them above. The end result ends up being the same however.
Regardless of which method you choose to use, the results are the same: our polygon of Colorado is now drawn in the correct direction and the Spatial Results tab visually confirms this for us:

 A significant portion of Yellowstone National Park sits on top of a
A significant portion of Yellowstone National Park sits on top of a