Watch this week's video on YouTube
Imagine you have to perform some salary analysis for your employer International Mega Corp.
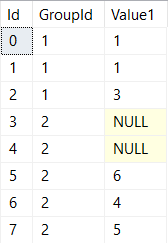
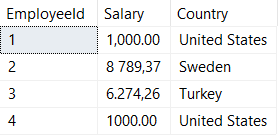
The data you have to work with looks something like this:
DROP TABLE IF EXISTS ##InternationalMegaCorpSalaries;
GO
CREATE TABLE ##InternationalMegaCorpSalaries
(
EmployeeId int IDENTITY,
Salary nvarchar(10),
Country nvarchar(20),
);
INSERT INTO ##InternationalMegaCorpSalaries VALUES ('1,000.00','United States');
INSERT INTO ##InternationalMegaCorpSalaries VALUES ('8 789,37','Sweden');
INSERT INTO ##InternationalMegaCorpSalaries VALUES ('6.274,26','Turkey');
INSERT INTO ##InternationalMegaCorpSalaries VALUES ('1000.00','United States');
Why are the salaries stored as nvarchar and formatted with commas, spaces, and periods?
Great question! Someone wanted to make sure these amounts would look good in the UI so storing the formatted values in the database would be the way to go...
Pretty for the UI, not really great for needing to do analysis on.
Thanks to Zanoni Labuschagne, one of the subscribers to my YouTube channel, for recommending this topic!
CONVERT!
I'm a firm believer that money values should always be stored in the decimal datatype. I can't think of a time where I wouldn't care about the precision and accuracy of money.
So let's try converting our salaries to decimal(10,2):
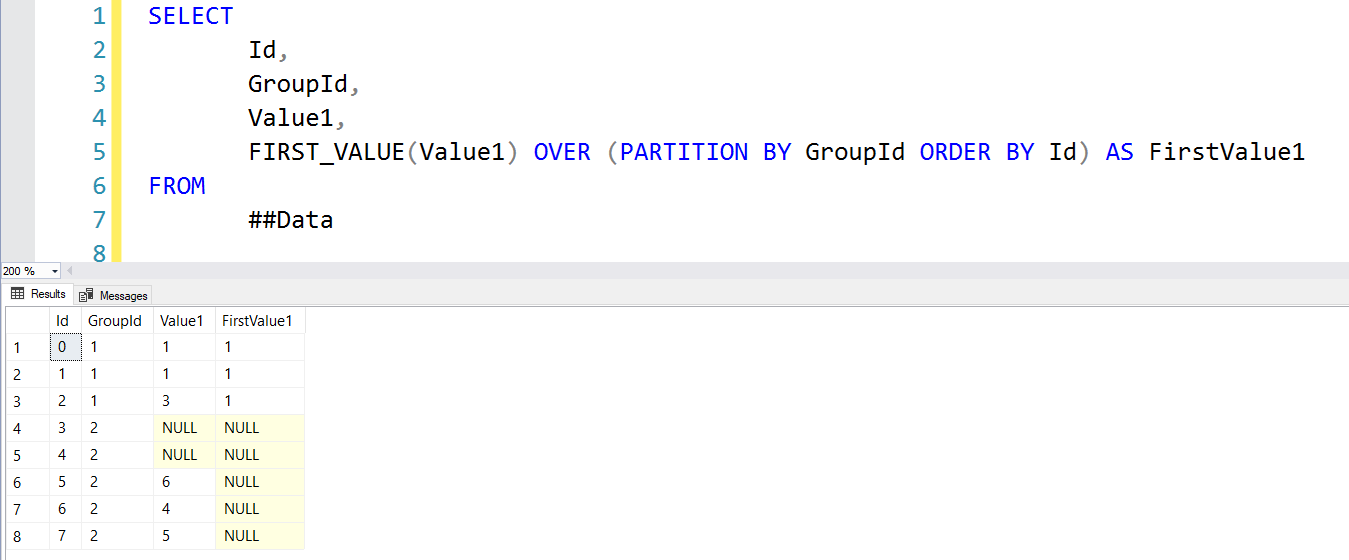
SELECT
EmployeeId,
TRY_CONVERT(decimal(10,2),Salary) AS Salary,
Country
FROM ##InternationalMegaCorpSalaries
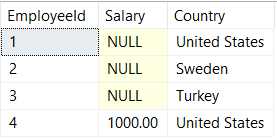
Well, that didn't work. Maybe converting to floats will work as a quick fix?
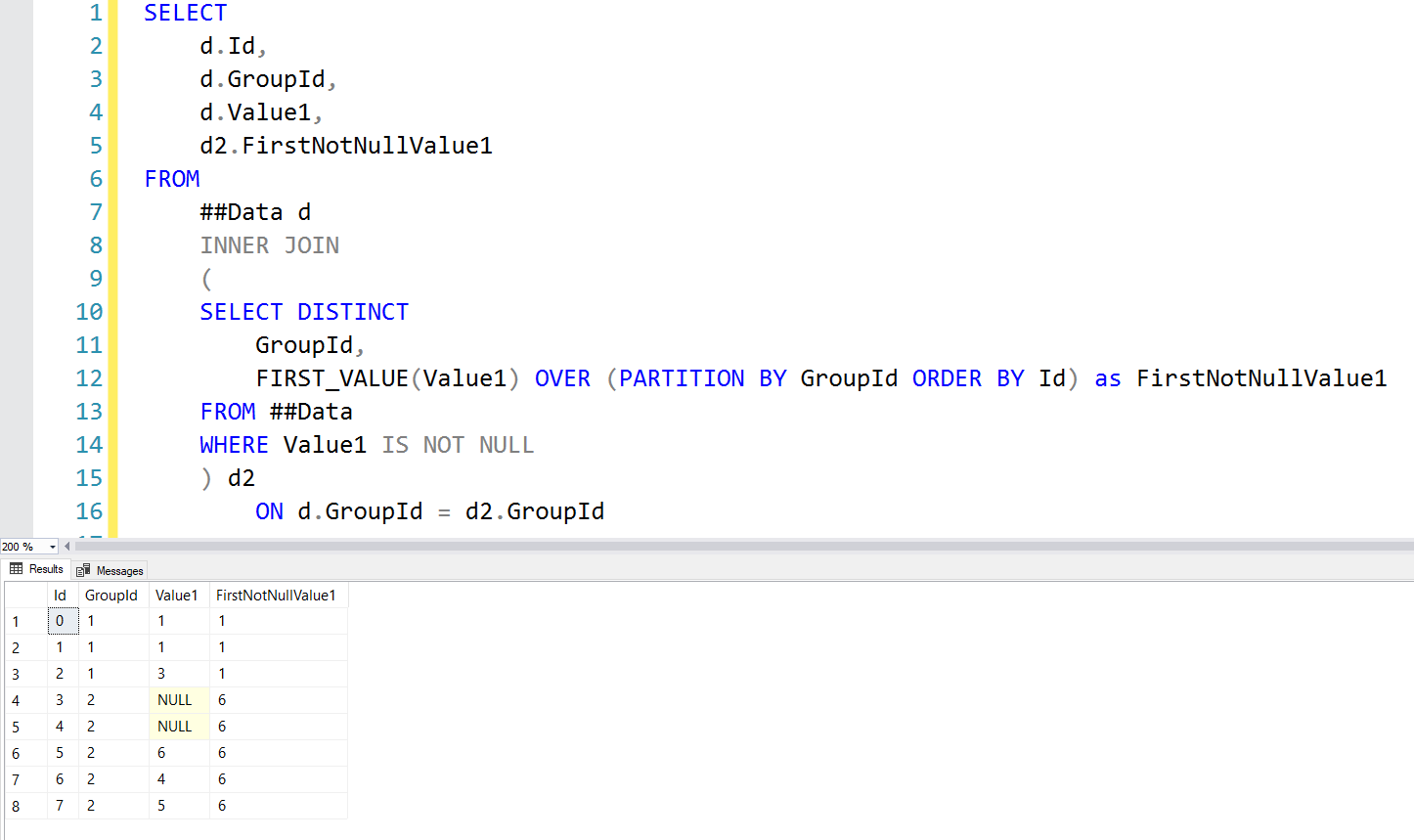
SELECT
EmployeeId,
TRY_CONVERT(float,Salary) AS Salary,
Country
FROM ##InternationalMegaCorpSalaries
Nope that didn't work either
(sidenote: I'm OK with that though - I don't think float should ever be used for storing money. If you want to see a quick example of why float math is problematic take a look at this (and for more detail read about it here):
DECLARE
@Num1 float = .15,
@Num2 float = .15,
@Num3 float = .1,
@Num4 float = .2
-- Not equal
SELECT IIF(@Num1+@Num2 = @Num3+@Num4,1,0)
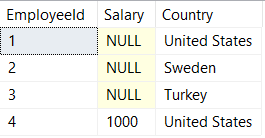
Ok so those didn't work. What if we try converting to the money datatype - that should work for being able to read these money formats right?
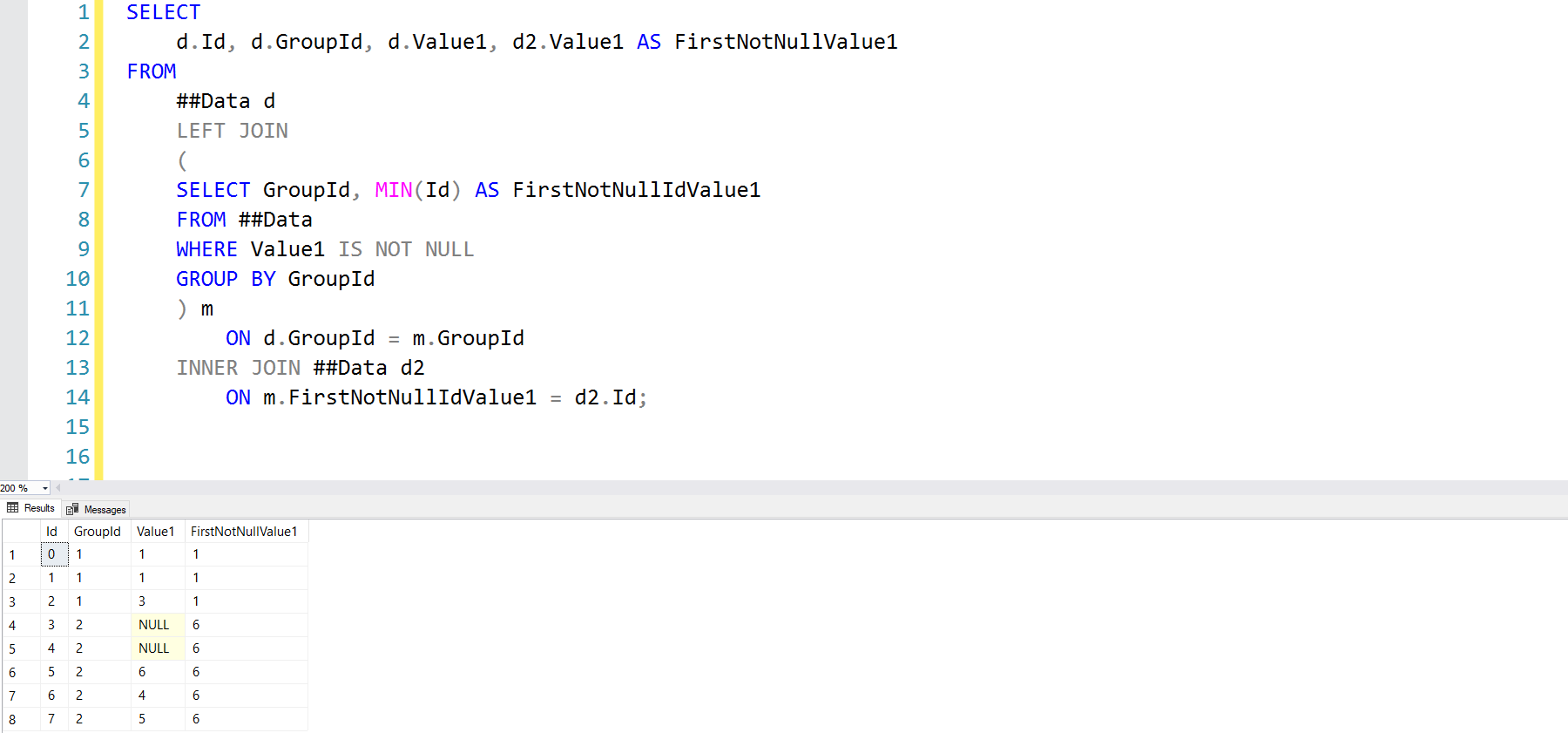
SELECT
EmployeeId,
TRY_CONVERT(money,Salary) AS Salary,
Country
FROM ##InternationalMegaCorpSalaries
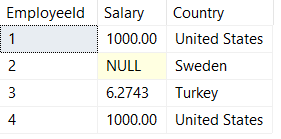
50% correct...! Our employees in Turkey are being seriously underpaid with conversion though. I'm kind of glad to not have to rely on this solution though since the money datatype has its own fair share of problems as well.
Time to get Cultured
SQL Server's TRY_PARSE function might be able to help us, but first we need to create a relationship between each country's money formatting and it's culture code:
ALTER TABLE ##InternationalMegaCorpSalaries
ADD CultureCode AS CASE Country
WHEN 'United States' THEN 'en-US'
WHEN 'Sweden' THEN 'sv-SE'
WHEN 'Turkey' THEN 'Tr-TR' END
And finally our SELECT query:
SELECT
EmployeeId,
TRY_PARSE(Salary AS DECIMAL(10,2) USING CultureCode) AS Salary,
Country
FROM ##InternationalMegaCorpSalaries
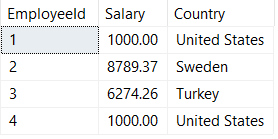
Success! Our salary values are now perfectly converted into the decimal datatype without the need for any ugly REPLACE(), SUBSTRING(), or other string parsing functions.
While this carefully curated demo correctly converted all of our values, it's important to always test that the culture value you choose correctly formats your string formatted number. For example, Wikipedia leads me to believe that the Danes write their numbers like "6 338,70" SQL Server's culture definition doesn't convert this correctly:
SELECT TRY_PARSE('6 338,70' AS DECIMAL(10,2) USING 'da-dk')
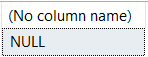
In those instances, you may need to substitute another culture code to get the correct conversion to occur.

 Imagine a stack of loose leaf pages. This collection of pages is our table.
Imagine a stack of loose leaf pages. This collection of pages is our table. To make searching through our pages easier, we sort all of the pages by bird name and glue on a binding. This book binding now keeps all of our pages in alphabetical order by bird name.
To make searching through our pages easier, we sort all of the pages by bird name and glue on a binding. This book binding now keeps all of our pages in alphabetical order by bird name. Let's say we want a lighter-weight version of our book that contains the most relevant information (bird name, color, description).
Let's say we want a lighter-weight version of our book that contains the most relevant information (bird name, color, description).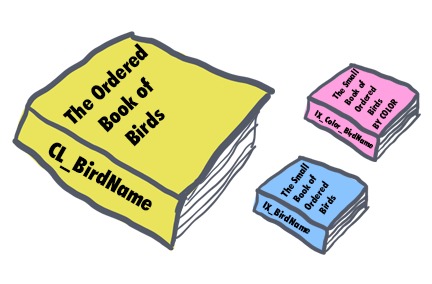 Instead of having a nonclustered index sorted by bird name, what we really need is a way to filter down to the list of potential birds quickly.
Instead of having a nonclustered index sorted by bird name, what we really need is a way to filter down to the list of potential birds quickly.