Recently I have been working on a project where I needed to parse XML files that were between 5mb and 20mb in size. Performance was critical for the project, so I wanted to make sure that I would parse these files as quickly as possible.
The two C# classes that I know of for parsing XML are XmlReader and XmlDocument. Based on my understanding of the two classes, XmlReader should perform faster in my scenario because it reads through an XML document only once, never storing more than the current node in memory. On the contrary, XmlDocument stores the whole XML file in memory which has some performance overhead.
Not knowing for certain which method I should use, I decided to write a quick performance test to measure the actual results of these two classes.
The Data
In my project, I knew what data I needed to extract from the XML up front so I decided to configure test in a way that mimics that requirement. If my project required me to run recursive logic in the XML document, needing a piece of information further down in the XML in order to know what pieces of information to pull earlier on from the XML, I would have set up an entirely different test.
For my test, I decided to use the Photography Stack Exchange user data dump as our sample file since it mimics the structure and file size of one my actual project's data. The Stack Exchange data dumps are great sample data sets because they involve real-world data and are released under a Creative Commons license.
The Test
The C# code for my test can be found in its entirety on GitHub.
In my test I created two methods to extract the same exact data from the XML; one of the methods used XmlReader and the other XmlDocument.
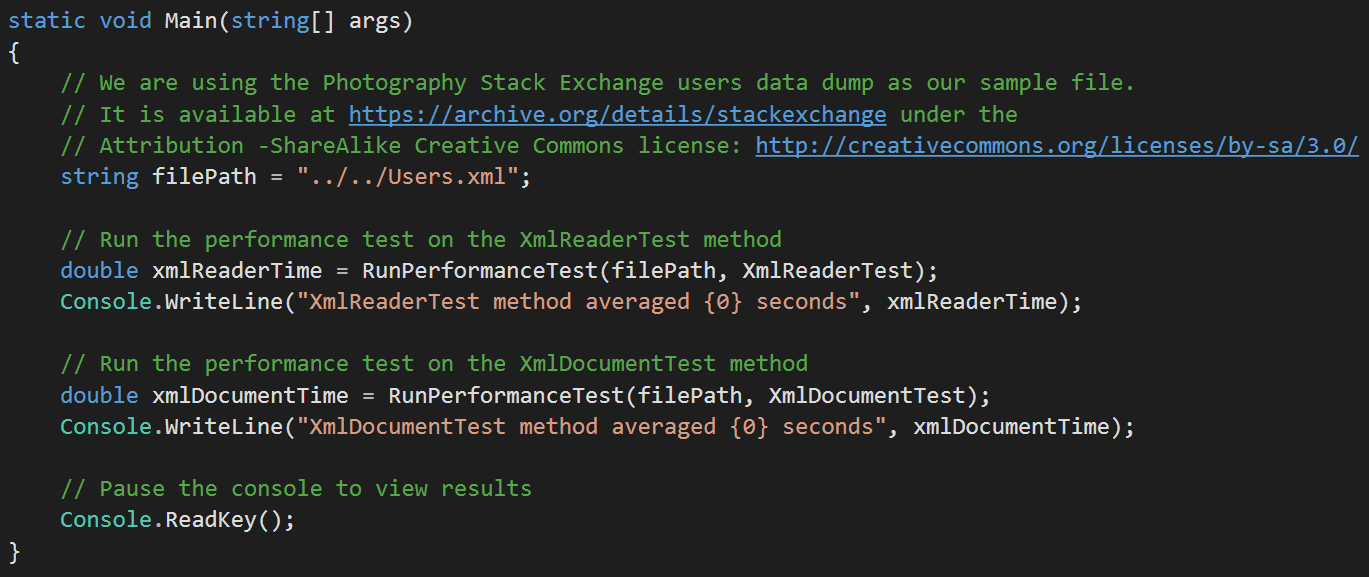
The first test uses XmlReader. The XmlReader object only stores a single node in memory at a time, so in order to read through the whole document we need to usewhile(reader.Read()) in order to loop all of the nodes. Inside of the loop, we check if each node is an element that we are looking for and if so then parse out the necessary data:
public static void XmlReaderTest(string filePath)
{
// We create storage for ids of all of the rows from users where reputation == 1
List<string> singleRepRowIds = new List<string>();
using (XmlReader reader = XmlReader.Create(filePath))
{
while (reader.Read())
{
if (reader.IsStartElement())
{
if (reader.Name == "row" && reader.GetAttribute("Reputation") == "1")
{
singleRepRowIds.Add(reader.GetAttribute("Id"));
}
}
}
}
}
On the other hand, the code for XmlDocument is much simpler: we load the whole XML file into memory and then write a LINQ query to find the elements of interest:
public static void XmlDocumentTest(string filePath)
{
List<string> singleRepRowIds = new List<string>();
XmlDocument doc = new XmlDocument();
doc.Load(filePath);
singleRepRowIds = doc.GetElementsByTagName("row").Cast<XmlNode>().Where(x => x.Attributes["Reputation"].InnerText == "1").Select(x => x.Attributes["Id"].InnerText).ToList();
}
After writing these two methods and confirming that they are returning the same exact results it was time to pit them against each other. I wrote a method to run each of my two XML parsing methods above 50 times and to take the average elapsed run time of each to eliminate any outlier data:
public static double RunPerformanceTest(string filePath, Action<string> performanceTestMethod)
{
Stopwatch sw = new Stopwatch();
int iterations = 50;
double elapsedMilliseconds = 0;
// Run the method 50 times to rule out any bias.
for (var i = 0; i < iterations; i++)
{
sw.Restart();
performanceTestMethod(filePath);
sw.Stop();
elapsedMilliseconds += sw.ElapsedMilliseconds;
}
// Calculate the average elapsed seconds per run
double avergeSeconds = (elapsedMilliseconds / iterations) / 1000.0;
return avergeSeconds;
}
Results and Conclusions
Cutting to the chase, XmlReader performed faster in my test:
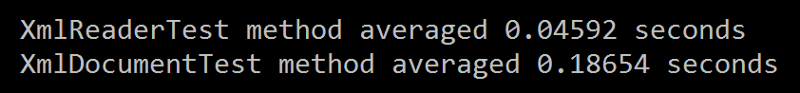
Now, is this ~.14 seconds of speed difference significant? In my case, it is, because I will be parsing many more elements and many more files dozens of times a day. After doing the math, I estimate I will save 45–60 seconds of parsing time for each set of XML files, which is huge in an almost-real-time system.
Would I have come to the same conclusion if blazing fast speed was not one of my requirements? No, I would probably go the XmlDocument route because the code is much cleaner and therefore easier to maintain.
And if my XML files were 50mb, 500mb, or 5gb in size? I would probably still use XmlReader at that point because trying to store 5gb of data in memory will not be pretty.
What about a scenario where I need to go backwards in my XML document — this might be a case where I would use XmlDocument because it is more convenient to go backwards and forwards with that class. However, a hybrid approach might be my best option if the data allows it: if I can use XmlReader to get through the bulk of my content quickly and then load just certain child trees of elements into XmlDocument for easier backwards/forwards traversal, then that would seem like an ideal scenario.
In short, XmlReader was faster than XmlDocumet for me in my scenario. The only way I could come to this conclusion though was by running some real world tests and measuring the performance data.
So should you use XmlReader or XmlDocument in your next project? The answer is it depends.